Google DeepMind 最新的 FunSearch
FunSearch 是 Google DeepMind 最近利用大语言模型在数学领域的一个重大成果,甚至于你能从中看出前不久传闻中的 Q* 的影子,因为它本质上是实现了大语言模型自己提出解决数学问题的方案,并自己去验证解决方案。
它有一个前提条件,就是需要将数学问题描述成计算机代码“函数”,这就是 FunSearch 中“Fun”的由来,也就是“Function”。
下图很清楚的描述了 FunSearch 的工作原理。
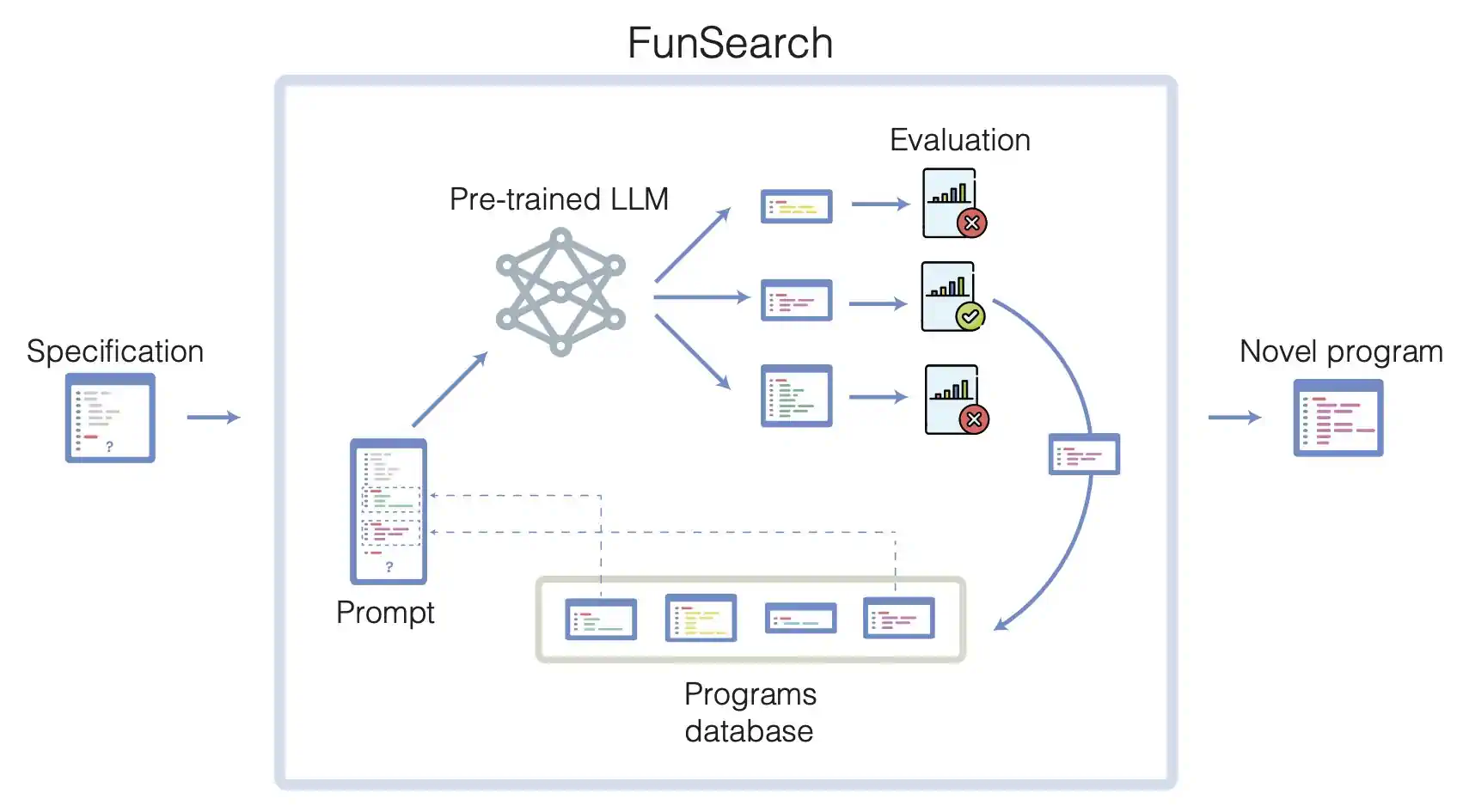
FunSearch 主要由几个部分组成:
- 大语言模型:根据现有代码,提出创新性的解决方案,生成新的代码
- 评估器:防止错误或虚构的结果,评估生成的结果,选择最好的结果
- 程序池:保存已经生成好的并且评估器评选的最好的代码
FunSearch 是一个循环迭代的过程。在每一轮中:
- 系统会从现有程序池选取若干程序,交由 LLM 加工。
- LLM 在这些程序的基础上进行创新,生成新程序,并自动对它们进行评估。
- 表现最佳的程序将被重新加入程序池,形成一个自我提升的循环。
借助代码和评估器,FunSearch 就类似于 Alpha Go 的训练那样,实现了一套自动训练优化的机制,让 LLM 提出新的解决方案,持续不断地优化解决方案,最终解决问题。
另外如果你记得 Jim Fan 他们做过的 GPT-4 自动玩 Minecraft 的 Voyager https://twitter.com/DrJimFan/status/1662115266933972993,原理也是类似的:把 Minecraft 的操作转换成代码,GPT-4 生成技能代码,生成后去 Minecraft 中执行校验,优秀的技能代码最终保存到技能库。思路惊人的相似。
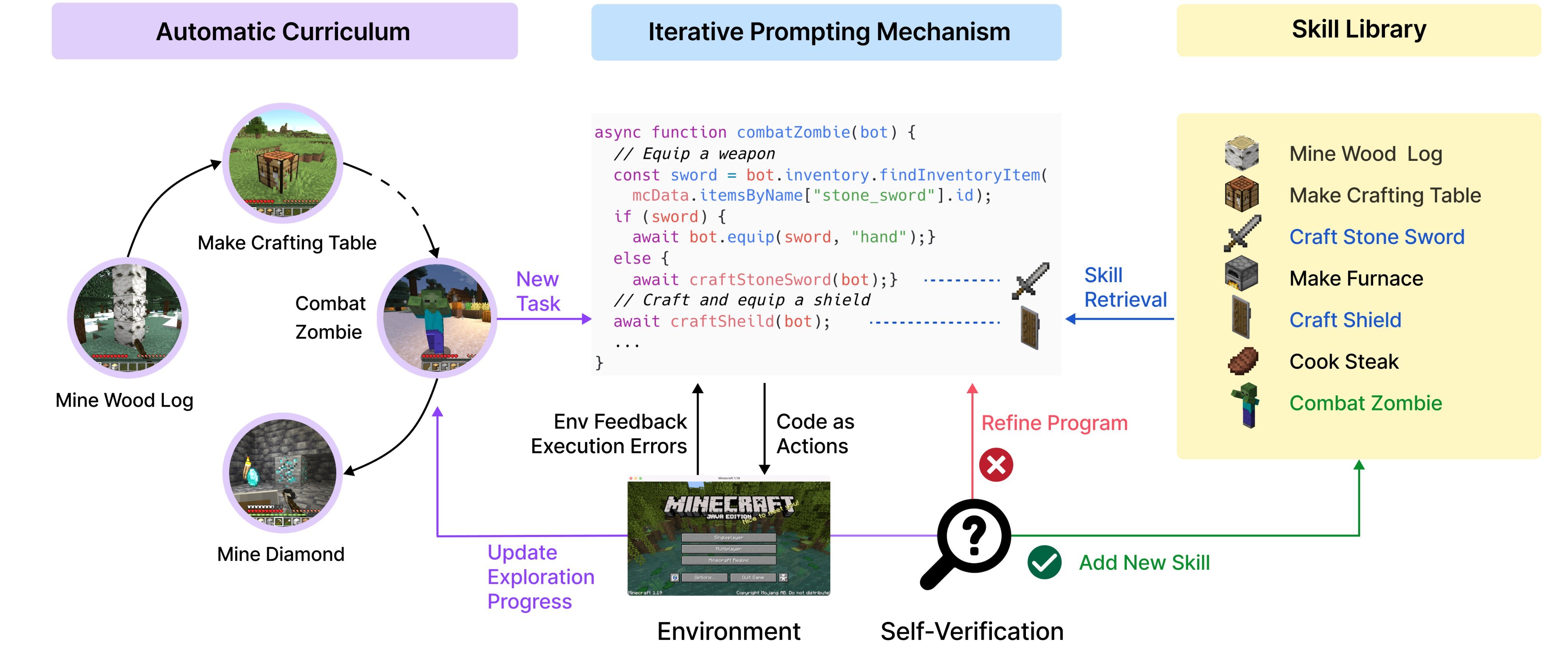
感觉这个(LLM - 代码 - 验证器)框架以后可以有越来越多的有创新的应用场景!