PromptAgent:借助语言模型进行策略性规划,达到专家级的提示优化 [译]
Xinyuan Wang1 Chenxi Li1* Zhen Wang12* Fan Bai5 Haotian Luo2
Jiayou Zhang2 Nebojsa Jojic3 Eric Xing24 Zhiting Hu1
1 加州大学圣迭戈分校 4 卡内基梅隆大学
3 微软研究院 5 佐治亚理工学院
2 穆罕默德·本·扎耶德人工智能大学
{xiw136, chl078, zhw085,平等贡献通讯作者
概述
要想制作出高效而专业的任务提示,通常需要专家们深入研究并巧妙融合详细指令和行业洞察。这需要他们对大语言模型(LLMs)的运作方式和特定任务的复杂性有透彻的理解。但要自动化生成这种水平的专业提示却是一件非常棘手的事情。现有的提示优化方法通常会忽略行业知识的深度,并在探索广阔的专家级提示空间时显得力不从心。为此,我们引入了 PromptAgent,这是一种能够独立创建出与专家亲手打造的提示同样优质的优化方法。
PromptAgent 把提示优化当作一个策略规划问题来处理,并运用了一种植根于蒙特卡罗树搜索的算法,巧妙地规划并探索专家级提示的可能性。它借鉴了人类通过试错探索的方法,通过反思模型的错误并提出建设性的反馈,帮助自己产生专业级的见解和详尽的指导。这种独特的框架让它能够反复检查和完善提示,预测未来可能获得的回报,并找到通往专家级提示的最佳路径。
我们已经将 PromptAgent 应用到了 12 个不同的任务中,涵盖了三个实际领域:BIG-Bench Hard (BBH)、特定领域的任务和通用的自然语言处理任务。结果显示,它的性能远超过目前强大的 Chain-of-Thought 和其他最新的提示优化方法。通过广泛的分析,我们还强调了 PromptAgent 在高效并且通用地创建富有洞察力且专业级别的提示方面的卓越能力。
1 引言
在大语言模型(LLMs)的世界里,提示工程正成为一门关键技术,它通过设计精妙的提示来充分发挥这些模型的强大能力。最新的自动化提示优化研究已经取得了显著的进展,比如训练出可以灵活应用的软提示(参见 Lester 等人于 2021 年的研究)、寻找最优的离散标记组合(比如 Shin 等人在 2020 年的工作),这些都是通过运用 LLMs 内部的状态或梯度来实现的。
然而,在使用像 GPT-4 这样的尖端且专有的 API-based LLMs 时,提示工程更多地依赖于人机之间的直觉交互。这就要求人类专家不仅要有丰富的领域知识,还要有洞察 LLMs 工作方式的直觉,从而创造出最有效的提示。以图 1 中展示的人类专家设计的理想提示为例,其中融入了任务描述、领域专业知识、解决方案的指导等丰富元素,极大地增强了提示的质量和效果。

图 1 展示了专家级提示与普通人类编写的提示、基于采样方法的自动提示工程师设计的提示之间的对比。任务是从生物医学领域中提取疾病实体,可以看到专家提示给出了更丰富的领域特定信息和结构化指导,从而导致了正确的预测结果。
在利用基于 API 的大语言模型(LLM)进行自动化的专家级提示构建中,我们面临着巨大的挑战。这主要是因为专家级提示本身就非常复杂(如图 1 所示)。近期虽然有一些优化提示方法涌现出来,它们使用了如迭代采样、蒙特卡罗搜索(Monte Carlo search,Zhou et al., 2022)和吉布斯抽样(Gibbs sampling,Xu et al., 2023)等先进技术。但这些方法多数依赖于基于直觉的编辑或改述技巧来产生候选提示,并且往往缺乏系统的策略来引导搜索过程。结果就是,这些方法通常只能生成普通用户级别的提示,很难达到专家级别的精细度。而且,这些方法往往忽视了提示构建实际上是一个需要人类参与的过程,人类专家通过不断地迭代和调整,将自己的领域知识融入到提示中,优化提示的效果。但人类探索虽然有效,却可能成本较高,尤其是在需要同时处理多个错误时。
为了解决这些问题,同时将类人的探索方式和机器的高效性结合起来,我们在这篇文章中提出了一个叫做 PromptAgent 的工具。PromptAgent 吸取了人类试错方法的精髓,并采用了一种名为蒙特卡罗树搜索(MCTS)的策略规划方法,对提示进行系统性优化。PromptAgent 将提示优化视作一种策略规划问题,通过不断的试错和模型错误分析,结合 LLM 自身的反馈能力,来引导搜索过程向更深入、更高质量的提示方向发展。它从一个初步的提示出发,通过策略性规划和反馈的运用,逐步深入探索复杂的专家级提示空间,并优先探索那些可能带来更好结果的路径。这种方法让 PromptAgent 能够预见到未来可能的收益,并据此调整当前的搜索策略,从而在探索过程中找到更优质的提示。
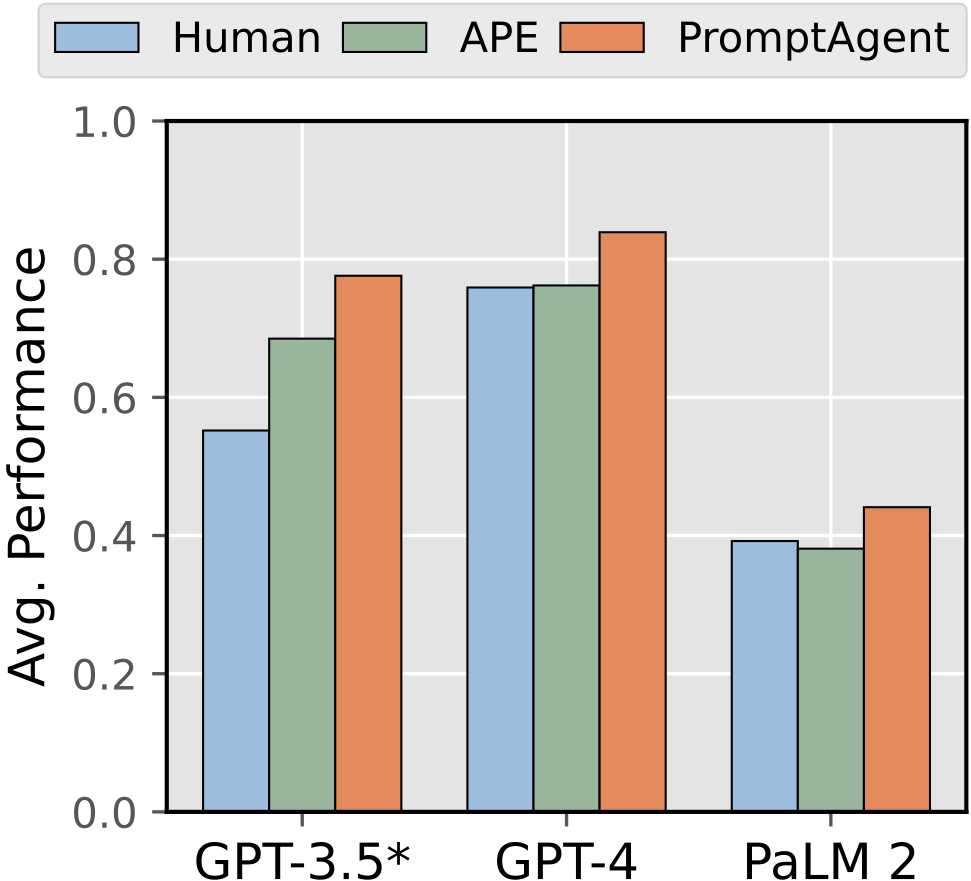
我们在这篇文章中展示了一个名为 PromptAgent 的工具,它能够在多个不同领域的 12 个任务上发现高效的专家级提示方法。这些任务包括 BIG-Bench Hard (BBH)(由 Suzgun 等人在 2022 年提出)以及一些特定领域和通用的自然语言处理(NLP)任务。PromptAgent 起始于一个人类编写的提示和一小批训练样本,不仅能大幅提升这个初始提示的性能,还能显著超过当前强大的思考链(Chain-of-Thought,CoT)方法和最新的提示优化技术。举个例子,从图 2 我们可以看到,无论是在 GPT-3.5、GPT-4 还是 PaLM 2 这三种模型上,PromptAgent 都比人类和自动提示工程师(APE)做得更好,分别提升了 9.1%、7.7% 和 6%。此外,我们通过大量的案例研究,进一步证明了 PromptAgent 优化后的提示在解决复杂任务时具有专家级的性能,它能够有效地克服不同领域间的差距,展现出极高的探索效率和泛化能力。我们相信,随着越来越强大的大语言模型(LLMs)的出现,它们能够理解更加复杂的指令,专家级的提示方法将成为提示工程领域的新趋势。而 PromptAgent,作为这个方向上的先驱,正引领着这一潮流的发展。
2. 相关研究
提示优化现已成为大语言模型时代一个至关重要的课题。对于开源的大语言模型,我们可以通过运用其内部状态或梯度,进一步训练如软提示(soft prompts)这样的额外参数,或者运用基于梯度的搜索和强化学习方法来寻找最佳的离散提示。但这些方法对闭源的大语言模型却不太适用,因此我们需要研究一种不依赖梯度、只需要 API 和有限训练集的提示优化方法。这类方法通常采用迭代式的提示采样过程,从一个初始提示开始,不断对提示候选进行采样和评分,从而挑选出最优的提示进行下一轮迭代。为了增加提示候选的多样性,研究者们尝试了多种方法,如基于编辑的方法、回译、进化操作和基于自然语言反馈的语言模型重写等。这些方法旨在帮助我们更有效地从大语言模型中挖掘知识,并优化我们与模型交互的方式。
此外,科研人员还探索了其他一些采样方法,如蒙特卡罗搜索(由 Zhou 等人在 2022 年提出)、吉布斯采样(由 Xu 等人在 2023 年提出)以及束搜索(由 Pryzant 等人在 2023 年提出)。不过,PromptAgent 这个工具在两方面与这些方法有着本质的不同。首先,尽管以前的研究已经深入探讨了各种搜索算法,但我们是第一批在提示优化研究中引入策略性规划的团队。这一创新方法为我们提供了一种系统的手段,可以高效地在复杂的提示空间中找到最优解,同时具备了前瞻和回溯等高级功能。其次,与以往的方法不同,它们通常会生成一些局部的变体,如通过改述或 LLM 采样来产生提示候选,但这样做往往忽略了细致入微的领域知识。我们的方法则是把生成提示当作一种状态转移,把错误反馈转化为新的状态,最终能够生成像专家一样精准的提示。
让 LLM 更上一层楼:引入自我反思和计划。尽管当下的大语言模型(LLM)已经相当强大,但它们仍然存在一些问题,比如在长篇内容上保持一致性的能力不足,这一点在 Malkin 等人 2022 年的研究中得到了证实;同样,它们也缺少一个能够理解和模拟现实世界的内部模型,这一问题在 Hao 等人 2023 年的论文中被提到。此外,LLM 无法直接在现实世界中进行操作。为了解决这些问题,研究人员开始尝试将 LLM 与外部模块结合使用,比如引入推理和工具模块,这在 Mialon 等人 2023 年的研究中得到了广泛的关注。在这方面,有两种主要策略:一种是自我反思,即让 LLM 自己审视并批判自己的输出,然后提出更好的解决方案,这在 Jang 2023 年的文章中有详细讨论;另一种是结合计划,即通过计划来提高 LLM 的性能。这些方法已经在多个领域取得了成功,包括复杂的计算任务、文本生成和推理等。
另外,运用大语言模型(LLM)进行规划不仅有助于我们对这些模型进行更好的评估,还能进一步提升它们的性能。规划,作为一种为了达成特定目标而生成一连串行动的能力,是智能体不可或缺的一部分(参见 McCarthy 等人 1963 年的研究和 Bylander 1994 年的工作)。目前,有两条主要的研究路径。一条是直接在规划任务上测试并评价 LLM 的表现(如 Liu 等人在 2023 年的工作)。比如,有些方法会将自然语言指令转换成可以执行的程序,再运用传统的规划算法来执行这些程序。另一条路径是通过结合基于规划的算法来增强 LLM 的战略推理能力。例如,“Thoughts 的树”(ToT)通过深度优先或广度优先搜索来增强链式推理(CoT)的效果,而 CoRe(由 Zhu 等人于 2022 年提出)和 RAP(由 Hao 等人在 2023 年提出)则利用蒙特卡洛树搜索(MCTS)来探索更丰富的推理路径。不过,与其他增强 LLM 性能的尝试相比,PromptAgent 是第一个专为提示优化而设计的框架,它独特地将自我反思和规划相结合。
3 方法论
在我们面临的任务中,我们有一个基本的大语言模型 B 和一个我们想要完成的特定任务 T。作为一个提示工程师,我们的任务是巧妙地设计一个优化过的自然语言提示 PT,这样可以让 B 在任务 T 上的表现达到最佳。但是,对于初学者和专家来说,特别是在一些需要专门知识的领域,比如生物医学,他们之间的差距可能会很大。我们的主要目标是通过自主调整任务提示 PT 来缩小这个知识差距,并且尽量减少人工干预。目前大多数方法都是通过不断地尝试不同的局部提示来找到最优解,但这样做既耗费资源又不能保证一定能找到最好的提示。因此,我们提出了一个名为 PromptAgent 的框架,它通过策略规划和在提示过程中根据错误反馈进行调整,找到了在探索和性能之间的平衡点,从而能够生成专家级别的任务提示。
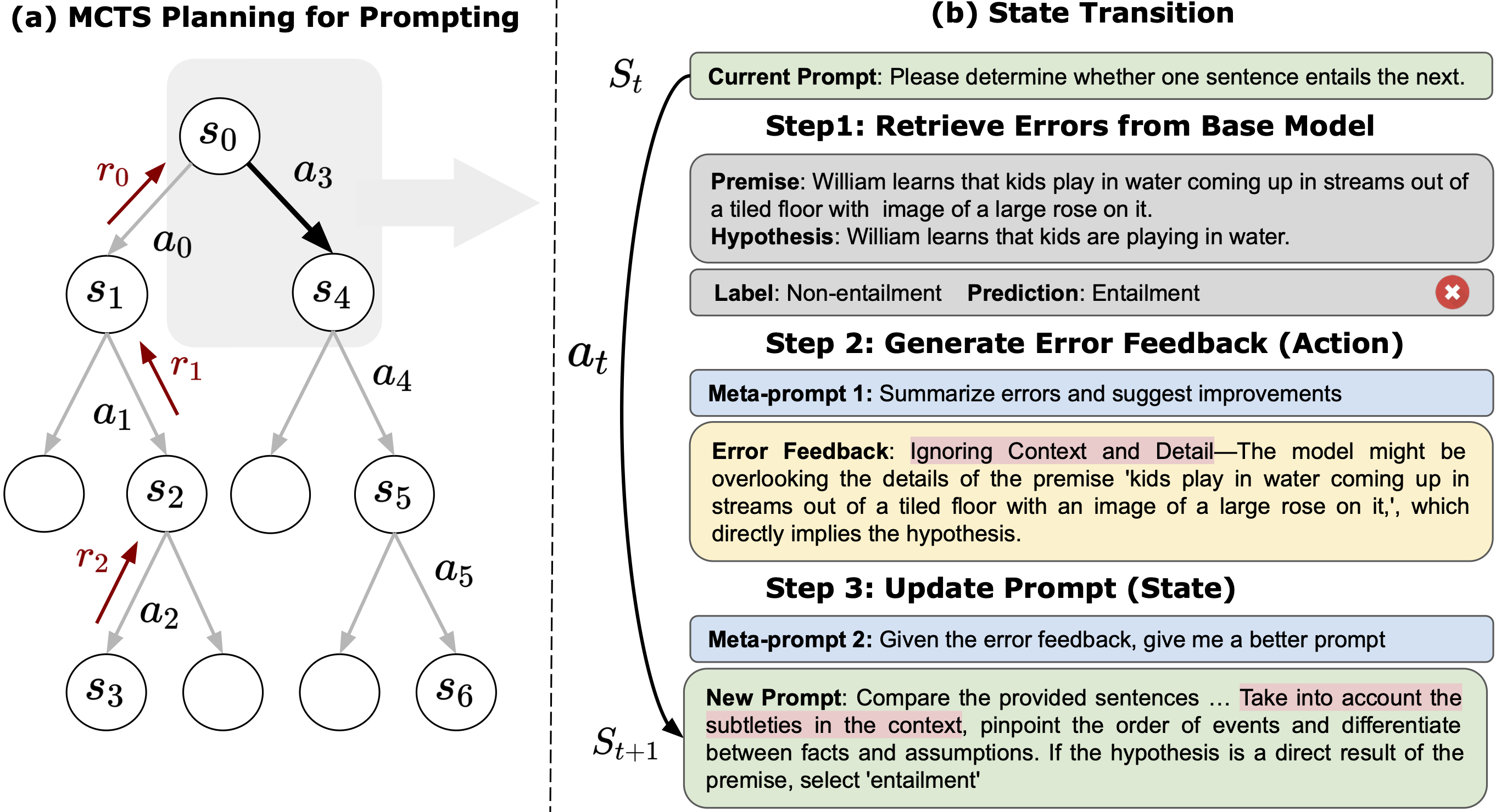
图 3:(a) MCTS(蒙特卡罗树搜索)规划用于生成专家级别的提示,树结构帮助 PromptAgent 进行策略规划。(b)这是一个简化的状态转换示例。在当前的提示状态下,基础模型(gpt-3.5-turbo)会从任务数据集中找出错误,然后优化器模型(gpt-4)会提供相应的错误反馈,最后模型会根据这些反馈更新提示,并转移到下一个状态。
问题定义。我们按照标准的提示优化流程来进行(参见 Zhou 等人的研究,2022)。我们从一个初始的自然语言任务提示 P0(例如,“我们一步一步来解这个问题”)和一小组目标任务 T 的训练样本出发,表示为 (Q,A)={qi,ai}Ni=1,其中 qi 和 ai 分别是每个样本的输入和输出。给定包含 P 和 qi 的模型输入,基础大语言模型 B 会进行预测,通常是通过从左到右的生成过程,基于 pB(ai|qi,P)。提示优化的目标是找到一个最优的自然语言提示 P∗,以最大化某个测量函数 R(如准确度)。这可以被形式化地定义为一个优化问题:P∗=argmaxP∈S ∑iR(pB(ai|qi,P)),其中 S 表示自然语言提示的所有可能样本空间,这是一个巨大且难以完全枚举的空间。通常情况下,人类专家会依靠经验和特定领域的知识来设计这些提示。虽然之前的优化方法也尝试使用迭代采样方法来发现优秀的提示(再次参见 Zhou 等人的研究,2022),但我们通过提出一个将战略规划完美融合在一起的统一框架,进一步推动了这个领域的研究,目标是实现更加卓越和专业级别的提示优化。接下来,我们将详细介绍 PromptAgent 的构思,以及我们基于规划的提示优化方法。
3.1 PromptAgent 框架设计
PromptAgent 的使命是把专家的丰富知识完美融入到任务提示中,同时还要巧妙且高效地挖掘庞大的提示空间。在这个规划框架下,我们把每一次任务提示的迭代或变体都看作一个“状态”,记作 st=Pt。这让我们能够跟踪提示的演变过程,并直接对其进行精细调整。这里的“行动”可以理解为对当前提示进行的各种可能的修改,比如替换词语或者进行意义上的转述,这在之前的研究中已经有所涉及(Jiang et al., [2020];Prasad et al., [2023])。然而,一个理想的行动空间应该能引入更有意义且更有效的调整,能够借助之前专家的知识,最终达到专家级别的提示。基于这个理念,我们提出了“基于错误的行动”——每一个行动都是基于基础模型之前犯下的错误来生成的。如图 3(b)所示,我们把行动定义为对错误的反馈,用来指导后续对提示的优化。这种基于错误的反馈能够有效地指明纠正模型错误的方向,确保优化后的提示能更好地引导基础模型规避之前出现的问题。值得注意的是,这种方法也与最近关于大语言模型(LLMs)自我反省能力的研究成果相契合,这表明 LLMs 能够直接从自身的错误中吸取教训,从而更好地优化任务提示。
在明确了状态和行动的概念后,PromptAgent 把任务提示优化问题定义为一个马尔科夫决策过程(MDP),用四元组(S, A, T, r)来表示。其中,S 代表状态空间,A 是行动空间,T 定义了状态之间的转移函数,r 则是奖励函数。如图 3(a)所示,在给定当前状态 st 的情况下,PromptAgent 会通过一个叫做优化器的大语言模型 O,根据公式 at∼pO(a|st,m1) 迭代生成一个行动 at,其中 m1 是一个元提示,用来帮助生成行动。具体而言,如图 3(b)展示的那样,行动生成包括两个步骤:第一步,从训练样本中搜集基础模型犯下的错误;第二步,反思这些错误,提炼出有用的错误反馈。之后,PromptAgent 会根据转移函数 pO(st+1|st,at,m2) 获取一个新的状态。这里的 m2 也是一个元提示,它帮助状态转移并更新任务提示,同样运行在优化器 O 上。更具体地说,给定当前的错误反馈作为行动 at,m2 将引导优化器生成一个新的提示(或者说新的状态),借助特定领域的知识来有效地解决模型的错误,这个过程和提示优化专家根据错误反馈来调整他们的提示非常相似。
最终,我们通过一个叫做奖励函数的工具(( r_t = r(s_t, a_t) ))来评估在执行了某个动作(( a_t ))后所达到的新状态(( s_t ))的质量。这个过程有点类似于强化学习(Reinforcement Learning, RL)中复杂而微妙的奖励设计环节:为了使奖励更符合特定领域的知识和针对某个特定任务的需求,构建奖励的过程可能会变得相当复杂。为了确保我们的框架能够灵活应用于各种不同的任务,我们选择了一种直接而简单的方法来定义奖励:即直接以模型在一组从训练样本中独立出来的测试集上的表现作为奖励。当然,具体如何定义奖励还是要根据任务的具体需求和标准来确定,这一点将在文中后续的实现细节部分给出更具体的说明。
3.2 精明规划,迅速优化
通过重新定义提示优化的过程,我们现在能够将 PromptAgent 和一些主要的规划算法完美融合,尤其是蒙特卡洛树搜索(MCTS)。这样一来,我们就能在巨大的提示空间中巧妙地游走,找到那些既能探索新奇路径又能充分利用已知信息的高回报策略,最终获得具有广泛适用性的专家级提示。有时,某些错误反馈可能会使任务提示过于特定化,难以泛用到整个任务类别上,这就需要我们运用策略性规划来挖掘更具普适性的错误反馈,从而获得更大的回报。正如图 3(a)所展示的那样,MCTS 通过逐步构建一棵树,并运用状态 - 动作价值函数 Q:S×A↦R 来进行策略性的搜索。我们利用这个函数来预测在给定状态 - 动作对后可能获得的回报,并根据这个预测来指导搜索。MCTS 通过连续执行选择、扩展、模拟和回传四个操作来实现这一过程,直至达到预定的迭代次数,最终选出最高回报的路径作为最终的提示。下面,我们将详细解释 PromptAgent 中这四个操作的具体实现,并且在附录中的算法 1 提供了基于 MCTS 的提示优化的伪代码。
首先是选择操作,其目的是在树的每个层级中挑选出最有潜力的节点进行进一步的探索。它从根节点开始,逐层向下,每次都选择一个子节点,直至达到叶子节点。在选择子节点时,我们运用了一种称为上限置信区间应用于树(UCT)的算法,该算法能够在挑选高价值节点(即充分利用已知信息)和探索访问次数较少的节点(即寻找新的可能性)之间取得平衡,其计算公式如下:
| (1) |
其中 A(st) 是节点 st 下所有可能的动作,N(st) 是节点 st 的访问次数,ch(s,a) 表示在执行动作 a′t 后到达的子节点,c 是一个调整探索强度的常数。这个公式的第一部分代表利用(选择已知高价值的节点),第二部分代表探索(对于访问较少的节点给予更多的关注)。
接着是扩展操作,其任务是在选择操作到达的叶子节点处添加新的子节点。这是通过重复应用动作生成和状态转移(如图 3(b)所示)来实现的,进而产生一系列新的动作和状态。需要注意的是,为了获取多样化的错误反馈,我们可能会采样多个训练批次。在这些新节点中,我们将奖励最高的节点传递给下一个模拟操作。
最后是模拟操作,其目的是对扩展操作选出的节点进行前瞻性的模拟,以预测其未来的轨迹和可能获得的回报。这个过程通常会有一个快速达到终态的策略,如随机选择动作。为了减少计算成本并简化过程,我们通过重复执行扩展操作直至达到终态,即在每一层中都生成多个动作,并选择其中奖励最高的节点继续前进。
在模拟过程中,一旦达到预定的结束状态,就会触发一种叫做反向传播的机制。所谓终止状态,可能是因为模拟深度达到了事先设定的上限,或者是满足了某个提前终止的条件。此时,我们会从终止节点开始,一路回溯到树的根部,过程中逐一更新每个节点的 Q 值。更新的具体方式是,对于路径上的每一对状态和动作,我们会计算从当前状态出发,未来所有可能路径上的奖励总和的平均值:
| (2) |
这里的 M 代表从当前状态出发的未来可能路径的数量,Sjst 和 Ajat 分别代表第 j 条路径上的状态序列和动作序列。
PromptAgent 会重复进行这四个步骤,进行多次迭代,以确保 Q 值稳定,并且能够充分地探索庞大的提示空间。在这个过程最后,我们需要从树中选出一个最优的节点(或者说,提示),用于最终的评估。虽然有多种不同的策略来做这个选择,但为了简单和实际考虑,我们通常会选取在实验中表现最好的那个,即在最佳路径上奖励最高的节点,作为最终的输出提示。
4. 实验
4.1 实验设置
任务与数据集
为了深入了解专家级提示优化在各种应用场景中的效果,我们精心挑选了 12 个来自三个不同领域的任务,进行了全面的实验研究。其中包括了 BIG-Bench Hard(简称 BBH)、领域特定任务和通用自然语言处理(NLP)任务。
BBH 是一套极富挑战性的 BIG-Bench 任务子集,其难度已经超出了目前大语言模型(LLMs)的处理能力。在这个子集中,我们特意选取了 6 个任务,这些任务既考验领域专业知识,如“几何形状”和“因果判断”,也考验复杂的推理能力,如“桌上的企鹅”、“对象计数”、“认识论推理”和“时间序列”。
在生物医学领域,我们还选择了三个强调专业领域见解的任务,以便在设计专家级提示时能够精准把握需求。这其中包括了一个疾病命名实体识别(NER)任务(NCBI,Doğan 等人发表于 2014 年)、一个生物医学句子相似性任务(Biosses,Soğancıoğlu 等人发表于 2017 年)以及一个医疗问题回答任务(Med QA,Jin 等人发表于 2021 年)。
最后,为了证明 PromptAgent 这一工具在传统 NLP 任务中也能大放异彩,我们额外选取了三个知名的自然语言理解(NLU)任务,包括两个文本分类任务(TREC,由 Voorhees 和 Tice 在 2000 年提出;Subj,由 Pang 和 Lee 在 2004 年提出)和一个自然语言推理任务(CB,由 De Marneffe 等人在 2019 年提出)。
基线
通过这些多样化的任务和数据集,我们将对 PromptAgent 的性能和适用性进行全方位的评估。
在这篇文章中,我们把我们的方法与三种常见的基线进行了对比:常规的人类设计的提示、思考链提示和最新的提示优化技术。人类设计的提示代表了常规的提示工程水平,通常来源于原始数据集。对于某些特定任务(BBH 任务),我们还参考了 Suzgun 等人 2022 年的工作,采用了包含教学示例的 few-shot 版本。对于其他任务,则是随机从训练集中抽取样本。
思考链提示则是一种通过引导模型进行中间步骤推理来提升其性能的技巧,对于 BBH 任务尤为有效。我们直接采用了 Suzgun 等人 2022 年提供的思考链提示,并为其他任务自行设计了相应的提示。此外,我们还尝试了一种 zero-shot 版本的思考链提示,即直接告诉模型“让我们一步步来思考”,而不提供任何示例。
最后,我们还探究了两种最新的提示优化方法:GPT Agent 和自动提示工程师(APE)。GPT Agent 代表了最近对于利用 LLM 实现强大自主智能体的浓厚兴趣,这些智能体有望独立完成规划和自我反思,从而解决人类提出的任务,包括优化任务提示。我们利用了 OpenAI 在 2023 年发布的一款强大的 ChatGPT 插件,AI Agents,来进行提示优化。具体而言,我们模仿了 PromptAgent 的做法,通过采样模型错误并要求 AI Agents 插件根据这些错误来重写提示,从而达到优化的目的。APE 则是另一种最新的提示优化方法,它通过蒙特卡洛搜索来迭代地提出并选择最优提示。
| Penguins | Geometry | Epistemic | Object Count. | Temporal | Causal Judge. | Avg. | |
| Human (ZS) | 0.595 | 0.227 | 0.452 | 0.612 | 0.720 | 0.470 | 0.513 |
| Human (FS) | 0.595 | 0.315 | 0.556 | 0.534 | 0.408 | 0.620 | 0.505 |
| CoT (ZS) | 0.747 | 0.320 | 0.532 | 0.542 | 0.734 | 0.610 | 0.581 |
| CoT | 0.747 | 0.540 | 0.720 | 0.960 | 0.626 | 0.650 | 0.707 |
| GPT Agent | 0.696 | 0.445 | 0.406 | 0.502 | 0.794 | 0.520 | 0.561 |
| APE | 0.797 | 0.490 | 0.708 | 0.716 | 0.856 | 0.570 | 0.690 |
| PromptAgent | 0.873 | 0.670 | 0.806 | 0.860 | 0.934 | 0.670 | 0.802 |
表 1 展示了各种方法在 BBH 任务中的表现。这里用到了两种测试方式:Zero-Shot (ZS) 和 Few-Shot (FS)。BBH 任务是由 Suzgun 等人在 2022 年提出的,包括了六个需要特定领域知识或较强推理能力的挑战性任务,如几何学(Geometry)和因果判断(Causal Judgement)。在这些任务中,我们的方法在五个任务中都取得了优于其他方法的成绩,只有在物体计数(Object Counting)这一任务中略逊于 CoT 方法。总体来看,我们的准确率比其他所有方法平均高出至少 9%。
实施详情
对于那些已经划分好默认测试集或验证集的数据集,我们直接采用其原有的划分方式来确定我们的测试集。如果没有官方划分训练集和测试集的情况,比如在 BBH 任务中,我们就会随机抽取一个相对较大的数据集来进行稳定的测试。正如我们在3.1 节所提到的,我们还从训练样本中划分出一部分用于计算奖励。关于数据集的更多详细信息,可以参见附录 A.1。除非另有特别说明,我们选择了 GPT-3.5 作为默认的基础语言模型(LLM)进行优化,它是目前相当强大的现代语言模型之一。至于优化器语言模型,我们需要一个具有出色自我反思能力的模型,因此我们选择了 GPT-4 作为默认的优化器语言模型。在进行预测时,我们将基础语言模型的温度设置为 0.0,在其他场合设置为 1.0。在实现 PromptAgent 的过程中,我们将蒙特卡洛树搜索(MCTS)的迭代次数设置为 12,探索权重 c 在公式 1中设置为 2.5。在扩展步骤中,我们根据模型的错误从训练样本中抽取批次来生成动作。每次我们会抽取 expand_width 批次,并为每个批次生成 num_samples 个新的提示。每条路径的最大深度限制为 depth_limit。为了更简单地调整这些超参数,我们测试了三种不同的设置:Standard、Wide 和 Lite。其中,Standard 和 Lite 的路径深度较大,而 Wide 在每次扩展步骤中生成更多的节点(具体的参数设置可以参见附录表 7)。我们根据奖励的大小来选择 PromptAgent 的最佳设置。关于输入格式、数据分割以及 PromptAgent 和基线方法的具体实施细节,可以参见附录 A。
4.2 结果与分析
| 专业任务 | 通用语言理解任务 | |||||||
| NCBI (F1) | Biosses | Med QA | 平均 | Subj | TREC | CB | 平均 | |
| 人工(零样本) | 0.521 | 0.550 | 0.508 | 0.526 | 0.517 | 0.742 | 0.714 | 0.658 |
| 人工(全样本) | 0.447 | 0.625 | 0.492 | 0.521 | 0.740 | 0.742 | 0.429 | 0.637 |
| CoT(零样本) | 0.384 | 0.425 | 0.508 | 0.439 | 0.656 | 0.63 | 0.750 | 0.679 |
| CoT | 0.376 | 0.675 | 0.542 | 0.531 | 0.670 | 0.784 | 0.643 | 0.699 |
| GPT Agent | 0.125 | 0.625 | 0.468 | 0.406 | 0.554 | 0.736 | 0.339 | 0.543 |
| APE | 0.576 | 0.700 | 0.470 | 0.582 | 0.696 | 0.834 | 0.804 | 0.778 |
| PromptAgent | 0.645 | 0.750 | 0.570 | 0.655 | 0.806 | 0.886 | 0.911 | 0.868 |
表 2:Prompt 在不同任务上的表现分析。其中,“专业任务”指的是那些需要特定领域知识的生物医学任务,而“通用语言理解任务”则展示了我们方法的广泛适用性。可以看出,无论是哪一类任务,我们的 PromptAgent 都表现出色,大大超过了其他方法和人工评估。
与各种提示基线的对比
与各种提示基线的对比中,PromptAgent 显露出其独特优势。通过表格 1 和 2 的展示,我们可以清晰看到,无论是对于人类编写的提示、CoT 方式,还是其他存在的优化方法,PromptAgent 在 12 个涉及三大领域的任务上都展现出了卓越的性能。以 BBH 任务为例,PromptAgent 不仅整体表现优越,而且在相对于人工提示、CoT 和 APE 这三种方法上,分别取得了 28.9%、9.5% 和 11.2% 的显著提升。特别值得一提的是,CoT 在 BBH 任务中表现尤为出色,甚至超过了人类编写的提示。这也从侧面印证了 Suzgun 等人在 2022 年的研究结果。CoT 通过逐步推理,能够很好地处理需要严谨格式化答案的任务,比如“对象计数”。但即便如此,除了在“对象计数”任务上,PromptAgent 在所有其他任务中都大幅领先于 CoT,显示出即使在零次提示的设置下,经过优化的专家级提示也能带来更大的提升。至于优化方法,我们认识到 GPT Agent 在规划和自我反思方面的能力,但它的规划范围仅限于单次提示的重写,并没有进行全面的、战略性的提示空间探索。而 APE 虽然展现出更强的搜索能力,但它基于蒙特卡洛搜索,存在规划效率低下和缺乏错误反馈的问题。这些问题凸显出在 PromptAgent 中进行战略规划的重要性,以便更全面地挖掘提示空间,生成真正达到专家级别的提示。
表格 2 给我们展示了在特定领域和一般自然语言处理任务上的结果对比。在生物医学等特定领域的任务中,需要丰富的专业知识和对大语言模型提示设计的深刻理解,而传统的人类编写的提示和 CoT 方法往往难以胜任。APE 这类通过自动化采样和优化来提高提示质量的方法显然更为合适,能够在减少人工干预的同时融入专业知识。而 PromptAgent 则更进一步,它平均在性能上比 APE 高出了 7.3%,展现出其在生成专家级提示、缩小新手与专家之间差距方面的独到优势。对于一般自然语言处理任务,PromptAgent 的通用性和效能同样得到了验证,它不仅在性能上超过了 CoT 和 APE,而且其性能提升幅度分别达到了 16.9% 和 9%,这再次强调了即使在常规任务中,专家级提示的重要性也不容忽视,它在各种应用场景中都发挥着不可替代的作用。
提示的通用性探究
接下来,我们通过实验来探讨一下我们优化后的提示是否能够应用到其他基础级语言模型(LLM)上。这一环节非常关键,因为它突出了专家级提示的稳定性和易迁移性,这两点对于我们来说是非常重要的。它告诉我们两个关键的信息:一是专家提示中深刻的领域认识和细致的引导能够毫无障碍地在各种强大的语言模型间转换,彰显了专家提示广泛的适用性;二是我们只需对每个任务优化一次提示,就能大大提升计算效率。但需要明确的是,PromptAgent 的主要目标是为顶尖的语言模型优化提示,以达到专家级别的效果。对于像 GPT-2 或 LLaMa 这样相对落后、规模较小的模型,它们可能难以完全捕捉到专家级提示的微妙之处,可能会导致性能的显著下降。尽管如此,为了更全面的评估,我们还对两个其他的基础 LLM 进行了评估:一个比 GPT-3.5 更强大的 GPT-4 和一个相对较弱的 PaLM 2。
在表 3 中,我们展示了将 GPT-3.5 优化后的提示直接应用于 GPT-4 和 PaLM 2(chat-bison-001)在所有 12 个任务上的结果。作为对比,我们还使用了相同的人工和 APE 提示作为基线。值得注意的是,在某些任务上,如“Penguins”,我们可能会使用与表 1 中引用的提示略有不同的版本,以确保 PaLM 2 能够给出合理的回答,而不是一味地返回空结果。
通过观察表 3,我们可以清楚地看到,当使用更为强大的 GPT-4 时,我们的专家提示表现得更加出色,几乎在所有任务(11/12 个)上都达到或超过了人工和 APE 提示的水平(唯一的例外是“Temporal”任务,GPT-4 几乎完美地解决了这个问题)。这一发现凸显了专家提示巨大的潜力,尤其是随着更为复杂的语言模型的出现,这一潜力还将进一步增大。而当我们把专家提示应用到相对较弱的 PaLM 2 上时,虽然性能有了明显的下降,但 PromptAgent 在 7/12 个任务上仍然超过了基线,尤其在一些领域特定的任务上,如 NCBI,展现出了专家提示所蕴含的领域知识的强大力量。
| GPT-3.5 | GPT-4 | PaLM 2 | |||||||
| Tasks | Human | APE | Ours | Human | APE | Ours | Human | APE | Ours |
| Penguins | 0.595 | 0.747 | 0.797 | 0.772 | 0.848 | 0.962 | 0.430 | 0.443 | 0.456 |
| Geometry | 0.227 | 0.490 | 0.670 | 0.495 | 0.445 | 0.680 | 0.290 | 0.215 | 0.360 |
| Epistemic | 0.452 | 0.708 | 0.806 | 0.734 | 0.848 | 0.848 | 0.470 | 0.392 | 0.588 |
| Object Count. | 0.612 | 0.716 | 0.860 | 0.830 | 0.852 | 0.888 | 0.290 | 0.378 | 0.320 |
| Temporal | 0.720 | 0.856 | 0.934 | 0.980 | 0.992 | 0.982 | 0.540 | 0.522 | 0.620 |
| Causal Judge. | 0.470 | 0.570 | 0.670 | 0.740 | 0.740 | 0.770 | 0.440 | 0.440 | 0.430 |
| NCBI (F1) | 0.521 | 0.576 | 0.645 | 0.588 | 0.428 | 0.697 | 0.016 | 0.025 | 0.177 |
| Biosses | 0.550 | 0.700 | 0.750 | 0.700 | 0.775 | 0.800 | 0.500 | 0.300 | 0.600 |
| Med QA | 0.508 | 0.470 | 0.570 | 0.770 | 0.758 | 0.774 | 0.284 | 0.274 | 0.276 |
| Subj | 0.517 | 0.696 | 0.806 | 0.867 | 0.805 | 0.879 | 0.496 | 0.537 | 0.499 |
| TREC | 0.742 | 0.834 | 0.886 | 0.716 | 0.764 | 0.876 | 0.380 | 0.400 | 0.230 |
| CB | 0.714 | 0.804 | 0.914 | 0.911 | 0.893 | 0.911 | 0.571 | 0.643 | 0.732 |
| Average | 0.552 | 0.685 | 0.776 | 0.759 | 0.762 | 0.839 | 0.392 | 0.381 | 0.441 |
表 3 展示了我们在提示泛化方面的实验结果。虽然 GPT-3.5 是我们优化的主要对象,但实际上我们优化后的提示同样适用于其他的大语言模型,比如 GPT-4 和 PaLM 2(chat-bison-001)。值得注意的是,GPT-4 在采用我们的提示后,性能得到了显著提升,在绝大多数(11/12)任务中都超越了之前的基准。对于相对性能较弱的 PaLM 2 来说,虽然我们的高级提示对它来说有一定的挑战,但它仍然在超过半数(7/12)的任务中取得了比基准更好的结果。总的来说,无论是哪个基础的大语言模型,我们的方法都能显著地超越原有的基准。
| 蒙特卡罗 | 波束 | 贪婪 | MCTS(我们的方法) | |
| 企鹅 | 0.772 | 0.823 | 0.810 | 0.873 |
| 首领 | 0.575 | 0.675 | 0.700 | 0.750 |
| 几何 | 0.490 | 0.610 | 0.545 | 0.670 |
| 因果 | 0.650 | 0.610 | 0.660 | 0.670 |
| 主观 | 0.692 | 0.765 | 0.778 | 0.806 |
| 平均 | 0.635 | 0.697 | 0.698 | 0.754 |
表 4: 我们通过比较不同的搜索方法来深入研究它们各自的效果。这些方法包括蒙特卡罗搜索(MC),波束搜索(Beam),贪婪搜索(Greedy),以及我们自己提出的方法 MCTS。通过在不同任务上的测试,我们发现无论在哪个领域,我们的方法都表现得更加出色。
搜索策略的消融
我们对搜索策略进行了详细的比较,以便更好地理解 PromptAgent 在战略规划上的表现。我们尝试了多种不同的搜索方法,包括单步的蒙特卡罗搜索,贪婪的深度优先搜索,以及波束搜索,并仅在搜索策略上做出了调整,保持其他所有设置不变。具体来说,蒙特卡罗搜索是一种无目标、随机的搜索方法;贪婪搜索则在每一步都选择最优的选项进行探索;波束搜索则在每一层上保留多个有前途的路径,进行更为结构化的探索。为了公平比较,我们确保了所有方法探索的提示数量相同。更多实现细节可以在附录 A.4 中找到。
由于计算资源有限,我们从三个领域中各选取了一部分任务进行比较。结果显示,在贪婪搜索和波束搜索的帮助下,性能相较于蒙特卡罗搜索有了显著的提升,这验证了结构化迭代探索在我们框架中的重要性。虽然在保持相同探索效率的情况下,贪婪搜索和波束搜索的整体表现相差无几,但它们都缺乏策略性地探索提示空间的能力,不能预测未来的结果,也不能回溯到过去的决策。相比之下,MCTS 的策略规划使我们的方法能够更有效地探索复杂的专家提示空间,其性能在所有任务上都超过了其他方法,相比最好的基线方法,整体性能提升了 5.6%。
| 方法 | 优化过的提示词 | F1 分数 |
| 人工 | 从句子中找出疾病或状况,如果有的话。 | 0.521 |
| APE | 从句子中提取出疾病或状况,如果提到的话。 | 0.576 |
| PromptAgent | 你的任务是从给定的句子中提取疾病或状况,要注意避免包含任何相关的元素,如遗传模式(如常染色体显性)、基因或基因座(如 PAH)、蛋白质或生物途径。这个任务不涉及基于上下文中的其他高级生物术语对疾病名称进行推测或推断。要考虑具体疾病和广泛分类,并注意疾病和状况也可能以常见缩写或变体形式出现。请按照这种格式提供识别出的疾病或状况:{entity_1,entity_2,….}。如果没有疾病或状况,以这种形式输出一个空列表:{}。注意,“locus”一词应被认为是基因组位置,而非疾病名称。 | 0.645 |
表 5: NCBI 任务的提示对比,包括普通人工提示、APE 优化的提示,以及由 PromptAgent 优化的专家级提示。两个基线主要是描述任务,而我们的专家提示包含更复杂的结构和特定领域的深刻见解,从而实现了更优秀的性能。粗体文本表示通常由领域专家手工制作的领域知识,但在这里是由 PromptAgent 自动发现的。我们用不同的颜色突出显示了专家提示的不同方面,包括任务描述、术语澄清、解决方案指南、异常处理、优先级与强调、格式设置。(颜色显示效果最佳)
 (a) 性能与探索效率 | 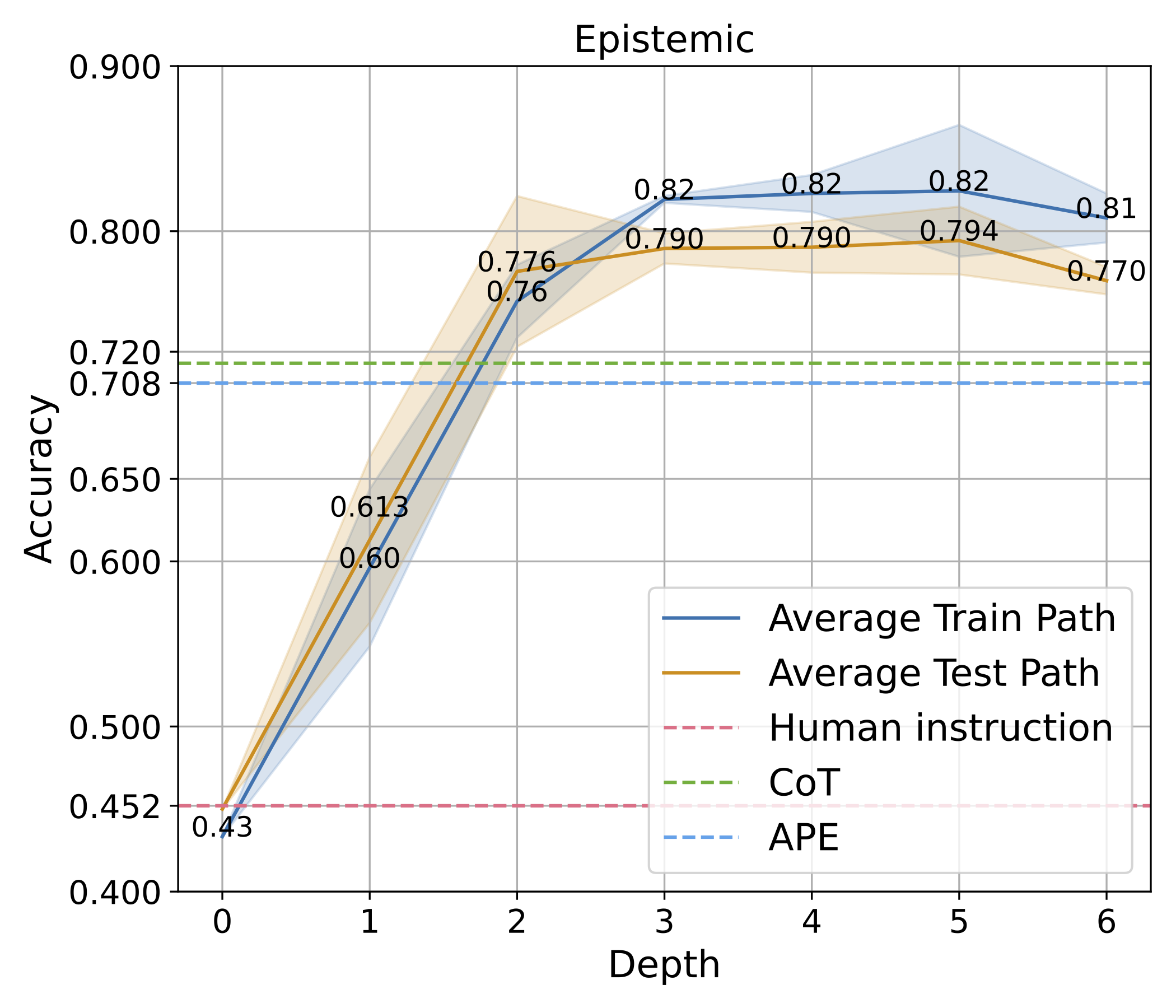 (b) 收敛性分析 |
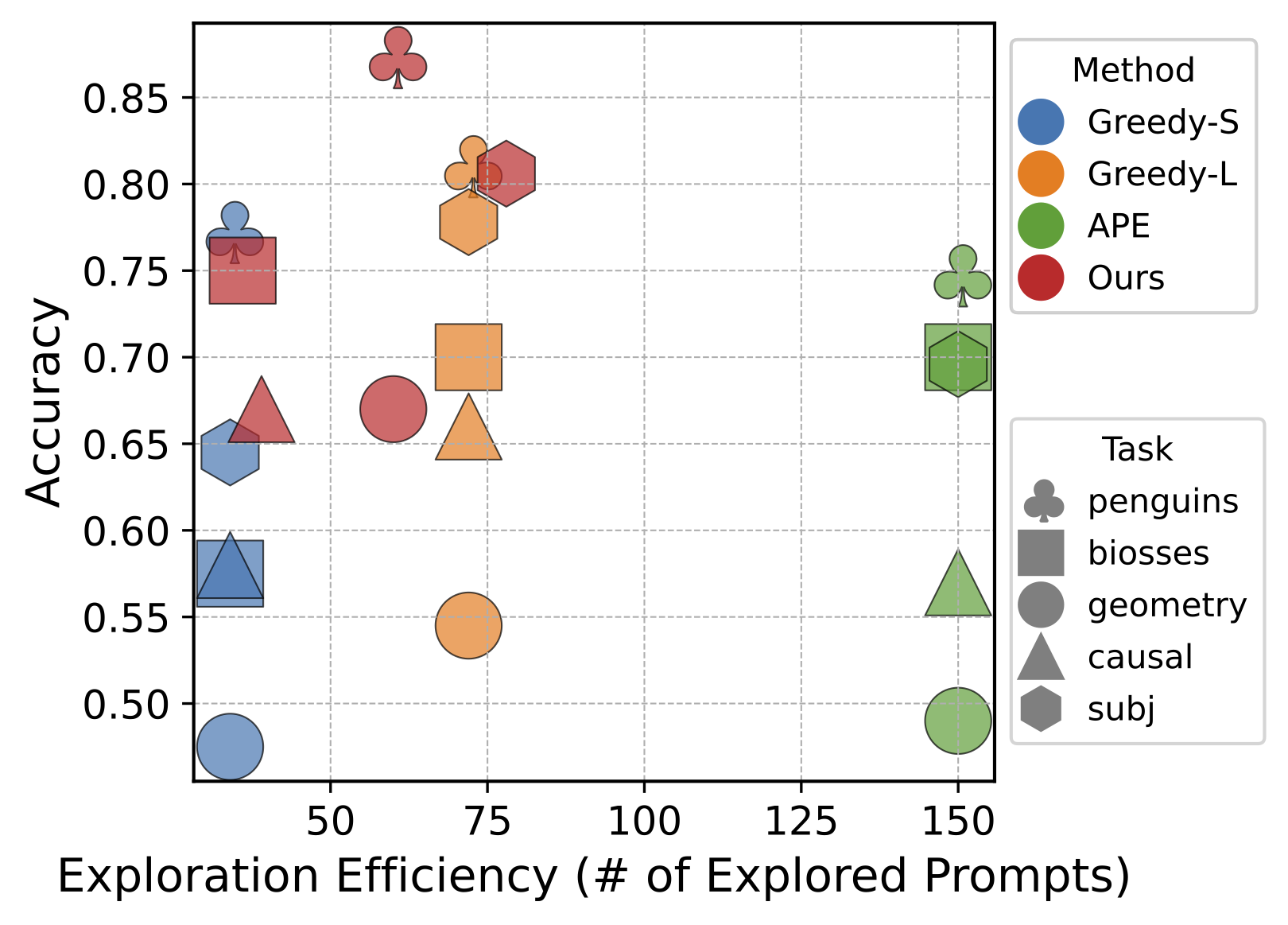
图 4: (a) 探索效率分析。在搜索和规划中找到探索和利用之间的正确平衡是至关重要的。我们比较了我们的方法与三个强大基线在探索提示数量上的差异。我们的方法实现了性能和探索效率之间的最佳平衡(集中在左上角)。(b) 对于 Epistemic 任务的收敛曲线,我们展示了训练和测试性能随时间的变化,均值和方差都在初始阶段上升,并在深度达到 3 后趋于稳定,显示出稳定的学习过程。
探索效率分析
除了卓越的性能外,PromptAgent 的另一个关键优势是其能够通过策略性规划高效地探索提示空间。探索效率对于保持搜索的计算成本在可管理的范围内也是至关重要的。因此,我们通过将 PromptAgent 与一些搜索基线(包括前一节中的贪婪搜索和 APE)进行比较,来分析探索效率。具体来说,通过搜索过程中探索的提示数量来衡量探索效率,即生成的节点数量。我们在图 3(a) 中绘制了探索效率与任务性能之间的关系。Greedy-S 和 Greedy-L 基于贪婪搜索,分别探索了 34 个和 72 个提示。APE 在每个任务中探索了 150 个提示。图表显示,PromptAgent 的数据点集中在左上角,表明在探索较少节点的同时实现了更高的准确性和更好的性能(更高的探索效率)。值得注意的是,尽管在贪婪搜索中增加提示数量可能会提高性能(从 Greedy-S 到 Greedy-L),但它需要更高的探索成本,并且仍然无法超过 PromptAgent。另外,没有明确指导的盲目搜索,如 APE,即使在探索更多时也不能有效提升性能。因此,为了保持探索效率和卓越的性能,PromptAgent 中的策略性规划至关重要,值得在未来的工作中进一步投资研究。关于 Greedy-S、Greedy-L 和 APE 的详细超参数设置见附录 A.4。
收敛性分析
想要深入理解 PromptAgent 如何学习的话,我们可以观察一下它在决策树计划过程中是如何改进专家提示的。具体来说,我们关注了树的不同深度下性能的变化,并将这一变化可视化出来。以 Epistemic 任务为例(如图 3(b) 所示),我们对所有节点的性能进行了评估,并在每个深度层次上汇总了训练和测试的性能。从图中我们可以看到,无论是在训练阶段还是在测试阶段,性能都在持续提升,并且最终超过了所有基准方法。其他任务和超参数设置的收敛性分析也在附录 C 和附录 A.3 中给出,但为了节省计算资源,这些分析仅关注训练过程。从这些分析中,我们可以看到一个明显的趋势:在最初的迭代中,性能会迅速提升,这说明了 PromptAgent 在迭代过程中不断优化专家提示的能力。
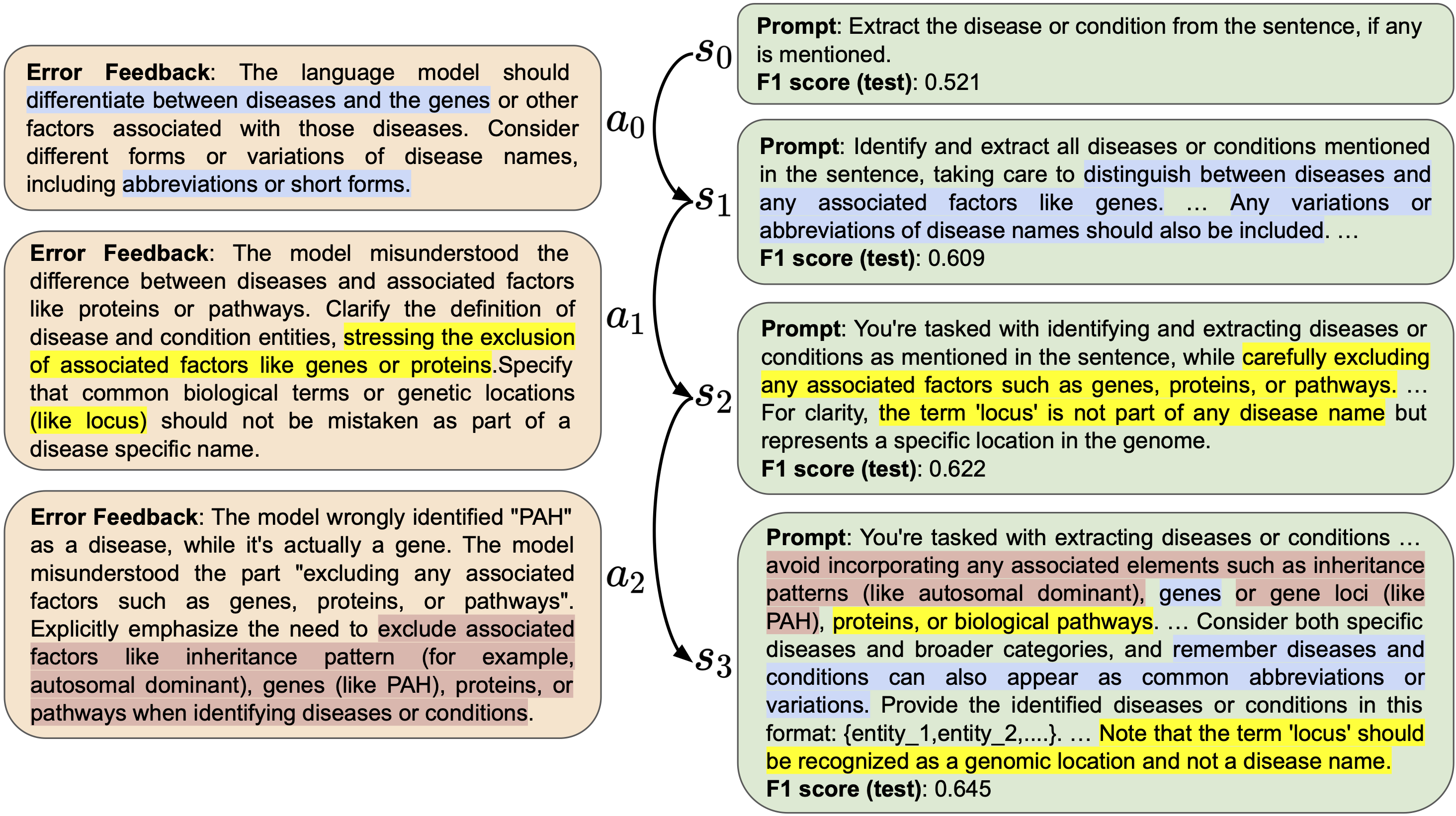
图 5:这是在 NCBI 数据集上获得最高平均奖励的路径的 MCTS 状态 - 动作转换轨迹。最初的状态 s0 是一个人工编写的提示,随后在每一步中,我们根据错误反馈调整前一个状态,以生成新的提示。颜色突出显示的部分表示领域特定的见解。在最后的状态中,我们整合了整个路径的信息,将 F1 分数从 0.521 提升到了 0.645。
定性分析
为了直观地展示 PromptAgent 是如何利用错误反馈来改进提示的,我们对其探索过程中的优化路径进行了定性分析。图 5 展示了在 NCBI 任务上获得最佳奖励路径的前四个状态和三次状态转换,目标是提取疾病实体(根据 Doğan et al. 2014 年的研究)。我们用颜色高亮显示了动作和状态中的领域特定见解,相同颜色表示相似的见解。可以看到,PromptAgent 从一个人类编写的初始提示(s0)出发,通过不断发现有用的错误反馈,并将其有效地整合到优化后的提示中,从而在测试性能上取得了进步。随着状态的转移,疾病实体的定义变得越来越清晰,生物医学领域的细节也得到了充分的融入。这个过程的积累最终体现在最后的状态 s3 上,它汇聚了前面路径上的所有见解,形成了一个专家级别的提示,实现了卓越的性能提升。
我们对优化后的专家提示的各个质量方面进行了详细的注解,深刻揭示了专家提示是如何提升提示设计技术并增强大语言模型对任务的深层次理解的。从 表 15 和 附录 D 可以看出,无论是对 NCBI 任务还是其他任务,PromptAgent 提供的提示比一般人类和 APE 优化的提示要详细得多,它提供了全方位的任务指导,并触及了各种不同的内容,比如解释专业术语、指导解决方案和处理特殊情况等等。需要特别指出的是,尽管未来可能会有研究通过采用提示压缩技术(比如 Jiang 等人在 2023 年和 Yin 等人在 2023 年的工作)来精简专家提示,而不损失性能,但专家级提示的复杂性的确与大语言模型最新的发展水平相匹配,这有助于更复杂、更深入地理解各种任务和人类的请求。
5 总结
在这篇文章中,我们向大家介绍了 PromptAgent,这是一个能够自动创造出能胜任特定任务的高水平提示的新型框架。它与传统的提示设计方法不同,因为它能够更加有效地融入领域内的专业知识,帮助领域专家填补他们的知识空白。PromptAgent 把提示优化当作一项策略规划任务来处理,运用 MCTS 规划技术来巧妙且高效地探索复杂的提示设计空间。通过对大语言模型的自我反思能力的利用,PromptAgent 能够通过不断试错的方式,将任务中的特定领域知识整合进新生成的提示中。我们在包含三个不同领域的 12 个多样化任务上对 PromptAgent 进行了测试。结果表明,由 PromptAgent 优化过的提示表现出了专家级的特质,丰富了特定领域的细节和指导,性能上也显著超过了人工编写的提示、连锁思考提示和其他优化方法。更深入的分析还揭示了我们的专家提示在可转移性、探索效率和质量上的卓越表现,为将来更进一步挖掘先进大语言模型对复杂任务深刻理解的提示设计工作奠定了基础。
输入:初始状态的提示 s0,状态转换函数 pθ,奖励函数 rθ,动作生成函数 pϕ,生成动作的数量 d,最大探索深度 L,迭代次数 τ,探索权重 c(详见方程 1)。 初始化:状态到动作的映射 A:S↦A,子节点映射 ch:S×A↦S,奖励 r:S×A↦R,状态 - 动作值函数 Q:S×A↦R,访问次数计数器 N:S↦N。对于 n=0 到 τ−1,执行以下步骤: 对于 t=0 到 L−1,执行以下步骤: 如果 A(st) 不为空,选择最优动作 at,更新状态 st+1,奖励 rt,和访问次数 N(st)。 否则,进行扩展和模拟:对于 i=1 到 d,随机选择动作 ait,更新状态 sit+1,奖励 rit,动作映射 A(st),子节点 ch(st,ait) 和奖励 r(st,ait)。选择最优动作 at,更新状态 st+1,奖励 rt 和访问次数 N(st)。 如果 st+1 是提前停止状态,中断循环。 结束循环。 T=实际执行的步数。 对于 t=T−1 到 0,根据方程 2,回传更新 Q(st,at) 的值。 结束循环。
算法 1:PromptAgent-MCTS(s0,pθ,rθ,pϕ,d,L,τ,c)
附录 A:更多实验详情
A.1 输入格式说明
当我们向模型输入信息时,通常包含以下几个部分:提示(Prompt)、任务前缀(Task Prefix)、问题(Question)、任务后缀(Task Suffix)和答案格式(Answer Format)。
其中“提示”是我们想要模型优化的目标。“任务前缀”(这部分可以根据需要选择是否添加)是对特定任务背景的简单介绍,比如在企鹅数据集中,可能就是一些关于企鹅的背景数据表格。“问题”则是我们想要模型回答的主要内容。“任务后缀”(这部分也是可选的)可能包括一些选项,比如在选择题中可能是 yes/no 或者 A, B, C, D 等。“答案格式”(同样是可选的)是我们期望模型在回答时遵循的格式。关于如何输入这些任务的例子,你可以在附录 B 找到。
关于元格式(meta formats)和提示(prompts)的更多细节,你可以在 3.1 节和附录 A.5 找到相关内容。
| Task | Train | Test |
| Bigbench | ||
| Penguins | 70 | 79 |
| Geometry | 150 | 200 |
| Epistemic | 500 | 500 |
| Object counting | 300 | 500 |
| Temporal | 300 | 500 |
| causal judgement | 90 | 100 |
| Domain Knowledge | ||
| NCBI | 2000 | 940 |
| Biosses | 60 | 40 |
| Med QA | 2000 | 500 |
| General NLP | ||
| Subj | 400 | 1000 |
| TREC | 400 | 500 |
| CB | 125 | 56 |
表 6 则展示了我们如何划分数据集的详细信息。
A.2 数据集划分细节
对于那些已经明确定义了测试集的数据集,我们会直接使用这些测试集。如果测试集的样本数量超过 1000,我们会从中随机抽取 1000 个样本作为我们的测试集。如果一个数据集没有预先定义的测试集,我们会首先将数据打乱,然后将大约一半的数据作为测试集,剩下的作为训练集。在训练集中,我们会再抽取一部分数据用于计算奖励,这部分数据默认包含 150 个样本。但如果训练集的大小小于 150 或者非常大,这个子集的大小会在 60 到 200 个样本之间进行调整。具体的数据划分细节,你可以在表 6 中查看。
A.3 更多实施细节
PromptAgent(我们自己的模型):PromptAgent 在提示语的选择范围内进行 MCTS(蒙特卡洛树搜索)计划制定,这需要设定何为结束状态以及如何评估奖励。当搜索的深度达到预设的限制 depth_limit 时,就认为达到了结束状态。奖励的评估标准则是根据模型在验证集上的表现来确定的。为了提高计算效率,防止模型浪费时间在不太可能的选择上,我们引入了一种提前停止的方法,即当搜索深度超过 2 层,且当前状态的奖励值低于最小阈值 min_threshold 或高于最大阈值 max_threshold 时,就停止搜索。具体来说,min_threshold 是其父节点和根节点奖励的平均值,而 max_threshold 是所有当前节点中的最大值,这样的设置鼓励搜索过程优先考虑路径较短的选项。详细算法可以参见文献 1。
-
初始化:PromptAgent-MCTS 算法以一个初始的提示语作为搜索的起点。对于 BBH(Behavioral Benchmarks for Humans)任务,我们直接使用数据集原有的任务描述作为初始的提示语,但 Object Counting 任务的默认描述并不符合我们需要的格式,因此我们为这部分任务另外设计了初始提示。根节点在开始第一轮搜索扩展之前会先进行评估,以确定其奖励值。
-
MCTS 迭代过程。智能体将执行 12 轮 MCTS(蒙特卡洛树搜索)迭代。在选择阶段,智能体将从根节点出发,根据 UCT(上限置信区间树)公式 1 计算并选择最优的子节点加入到搜索路径中,其中 UCT 公式中的探索权重 c 设定为 2.5。在扩展阶段,智能体会从训练集中随机选取若干批次的样本(每批次 5 个),并将这些样本送入基础模型中以找出可能的错误。如果一轮迭代中没有发现错误,智能体会继续进行下一轮迭代,直到找到错误为止。找到的错误会通过 error_string 进行格式化,并记录在 error_feedback 中,方便后续优化器对错误进行总结(相关信息见表 8 和图 1 的 Meta-prompt 1)。此外,state_transit 提示还会整合当前扩展节点的提示信息、搜索路径上的提示序列以及错误总结信息,供优化器生成 num_samples 个新的提示节点(见表 8 和图 3 的 Meta-prompt 2)。这些新生成的节点将经过评估,非终端节点将被添加到扩展节点的子节点列表中,每次扩展都会产生 expand_width × num_samples 个新的提示。在模拟阶段,智能体会递归扩展搜索路径上最后一个节点,并选择奖励最高的节点加入到路径中。当达到终止条件或满足提前停止条件时,模拟过程将终止。在反向传播阶段,智能体会从搜索路径的最末端回溯到根节点,将沿途节点的累积奖励加入到各自的累积奖励列表中,并计算平均奖励作为该节点的 Q 值(参见公式 2)。在我们的实验中,我们设置了三种不同的超参数配置:标准(Standard)、宽松(Wide)和轻量(Lite)(详见表 7)。在标准和轻量实验中,expand_width 和 num_samples 分别设为 3 和 1,但它们的搜索深度限制(depth_limit)分别设为 8 和 4。宽松实验中,expand_width 设为 3,num_samples 设为 2,以在每次扩展中生成更多的节点,但搜索深度限制设为 6,以限制探索的提示总量。我们将根据最终的奖励值来为每个任务选择最佳的配置。
-
输出策略。在 MCTS 的每次迭代中,我们会得到一条从起点到终点的路径,并在搜索过程中生成了数十个节点。我们会挑选平均奖励最高的路径,然后在这条路径上选择奖励最大的提示作为最终输出的提示。之所以这么做,是因为平均奖励最高的路径代表了最佳的搜索轨迹,而且最好的提示并不一定出现在最优路径的最后,有时可能因为达到了深度的限制而提前终止。
| 实验名称 | 标准版 | 加宽版 | 精简版 |
| depth_limit | 8 | 6 | 4 |
| expand_width | 3 | 3 | 3 |
| num_samples | 1 | 2 | 1 |
表 7:PromptAgent 实验的超参数设置
A.4 基准测试实现的细节
我们在此详细介绍了实验中使用的各种基准测试方法。
蒙特卡洛(MC)。这种方法通过多次尝试,从中选出最优的提示。它和 PromptAgent 采用相同的样本生成方法,但搜索的深度仅为一层。在我们的搜索消融研究中,每个任务会生成 72 个新的提示。
束搜索(Beam)。这种方法也采用了和 PromptAgent 相同的扩展函数。每个节点(根节点除外)会扩展成三个新节点,束宽设置为 3,这意味着搜索树的每一层都会有 9 个节点,其中最好的 3 个会被保留用于下一次扩展。根节点会被扩展成 9 个新节点。搜索的深度为 8,所以总共会有 72 个节点或新的提示。
贪婪搜索(Greedy)。这种方法基于束搜索,但其束宽为一,因此变成了一种深度优先的贪婪搜索方法。我们进行了两个实验,Greedy-S 和 Greedy-L(如图 3(a) 所示),它们的搜索深度都是 8,但扩展宽度不同。Greedy-S 的扩展宽度为 3,共有 34 个提示;而 Greedy-L 的扩展宽度为 9,共有 72 个节点,这也是表 4 中提到的 Greedy 基准测试方法。
APE(由 Zhou 等人在 2022 年提出)。我们采用了论文中建议的迭代式 APE,并仅进行了一次迭代作为我们的基线。在生成新的提示时,我们会从数据中随机抽取一个包含 5 个数据点的小批量作为输入输出示例。具体来说,在初始提议阶段,我们随机抽取了 10 个数据批次,每个批次用来生成 10 个新的提示,总共产生 100 个候选提示。(对于处理时间较长的 Med QA,这个阶段只生成了 25 个候选提示。)然后,我们选出评分最高的五个提示进入迭代提议阶段。在这个阶段,我们对每个已选提示再次进行数据抽样和提示生成,总共产生了 50 个候选提示。最后,我们从中选出评分最高的一个作为最终优化后的提示。
A.5 元格式
在本节中,我们展示了在 PromptAgent 中使用的元提示的完整格式。"input_format" 是给定一个问题时基础模型的实际输入。"error_string" 表示每个错误示例的格式。"error_feedback" 包括若干个错误示例,并指导优化器模型收集错误反馈。"state_transit" 指导优化器模型进行状态转换(生成新的提示),其中包括错误示例的信息和在选定路径中的提示序列,即 "trajectory_prompts"。
| 格式名称 | 元格式 |
| input_format | {prompt}{task_prefix}{question}{task_suffix}{answer_format} |
| error_string | <{index}>模型的输入是:{question} 模型的回应是:{response} 正确标签是:{label} 模型的预测是 {prediction} |
| error_feedback | 我正在为一个设计用于一项任务的语言模型编写提示。我当前的提示是:{cur_prompt} 但这个提示错误地处理了以下示例:{error_string} 对于每个错误的示例,仔细检查每个问题和错误回答的每个步骤,提供全面和不同的理由,解释为什么这个提示会导致错误的回答。最后,基于所有这些理由,总结并列出所有可以改进提示的方面。 |
| state_transit | 我正在为一个设计用于一项任务的语言模型编写提示。我当前的提示是:{cur_prompt} 但这个提示错误地处理了以下示例:{error_string} 根据这些错误,这个提示的问题和原因是:{error_feedback} 有一个包括当前提示的前一个提示列表,每个提示都是基于它的前一个提示修改的:{trajectory_prompts} 基于以上信息,请根据以下指南编写 {steps_per_gradient} 个新的提示:1. 新的提示应该解决当前提示的问题。2. 新的提示应该考虑提示列表,并基于当前提示进行演变。3. 每个新的提示应该用 <START> 和 <END> 包裹。新的提示是: |
表 8:元格式。
附录 B 任务输入示例
在本节中,我们展示了一些基础模型在几个任务中的输入示例。具体来说,我们的任务分为三类:多项选择、命名实体识别和直接答案匹配。作为代表性的示例,我们选择了“Penguins in A Table”、”NCBI”和“Subjective”来说明输入格式。

图 6:“Penguins in A Table”任务的输入格式。

图 7:“NCBI”和“Subjective”任务的输入格式。
附录 C:收敛观察细节
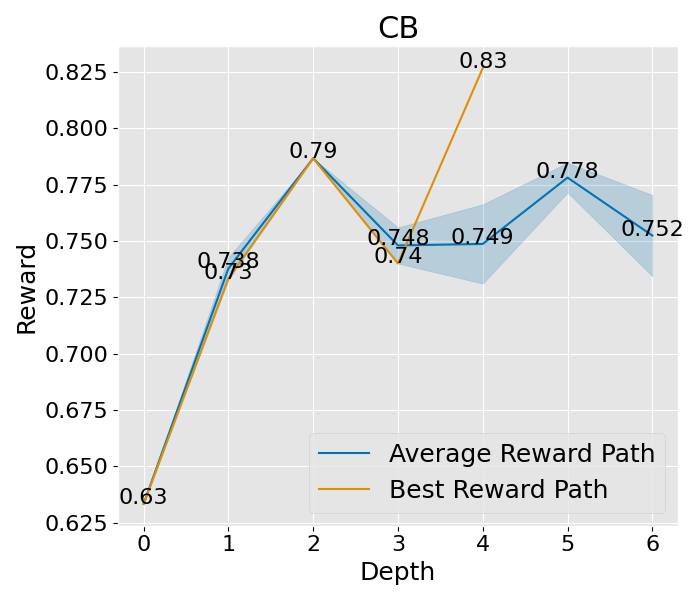 | 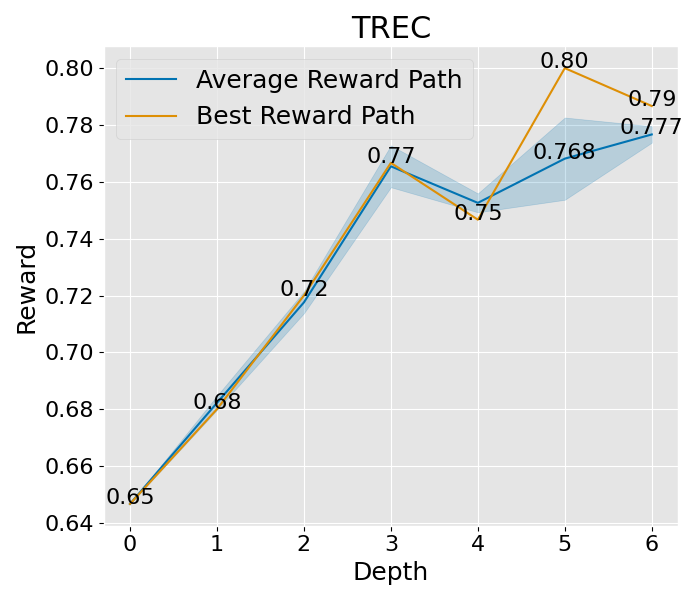 | 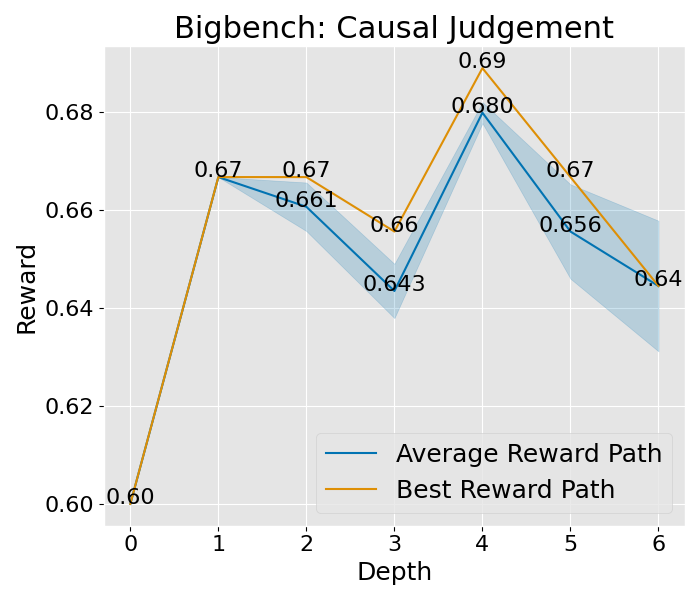 | 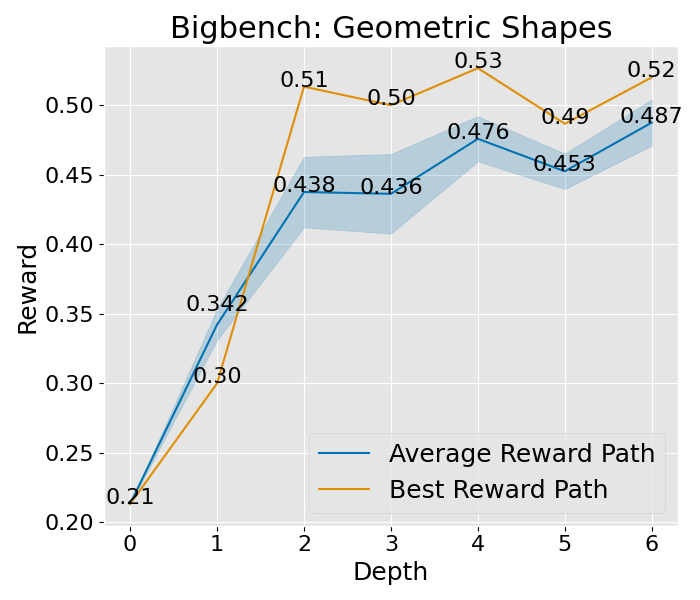 | 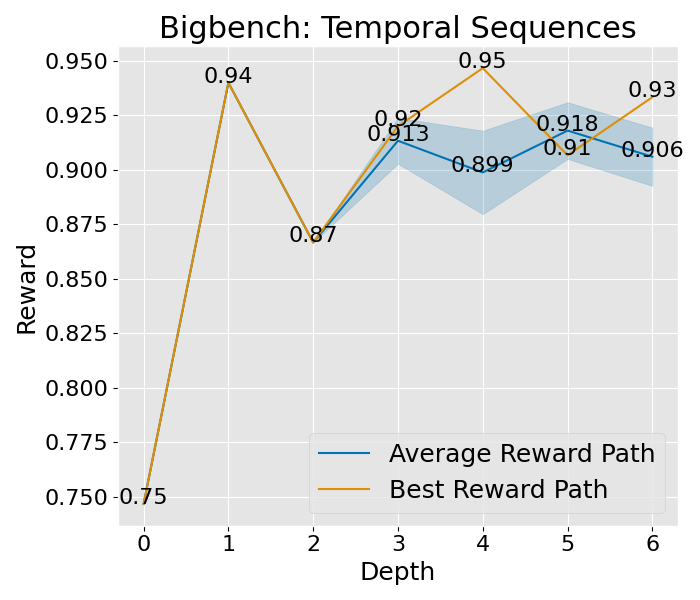 | 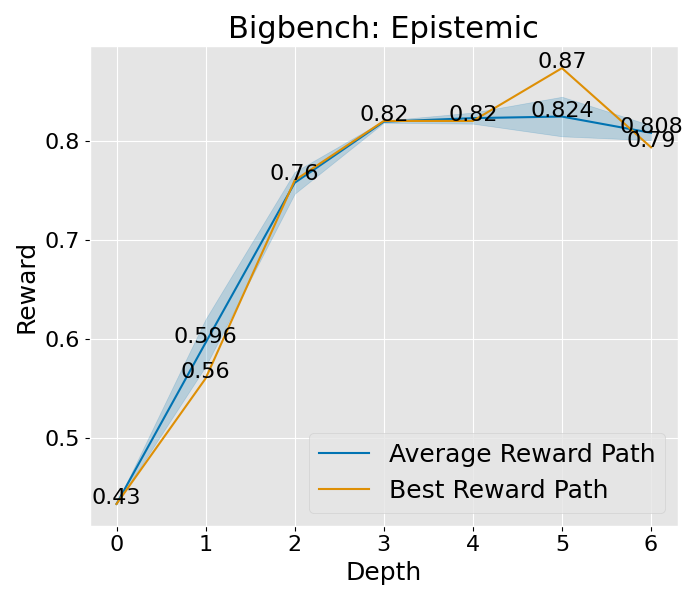 | 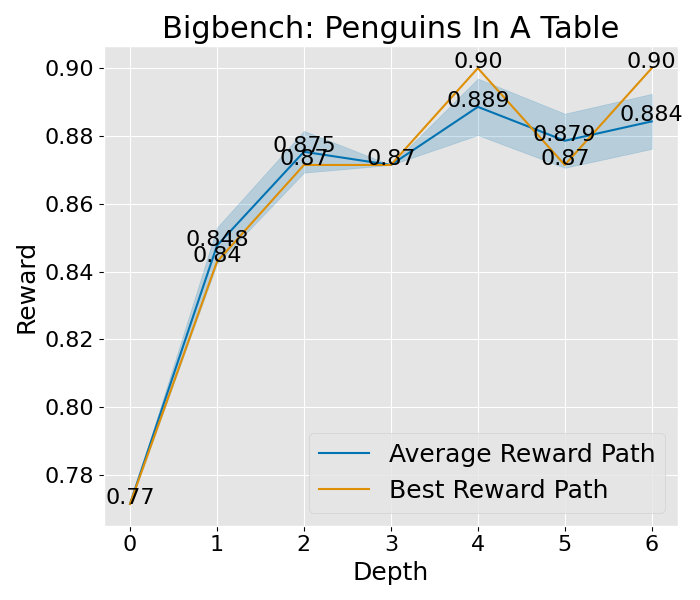 | 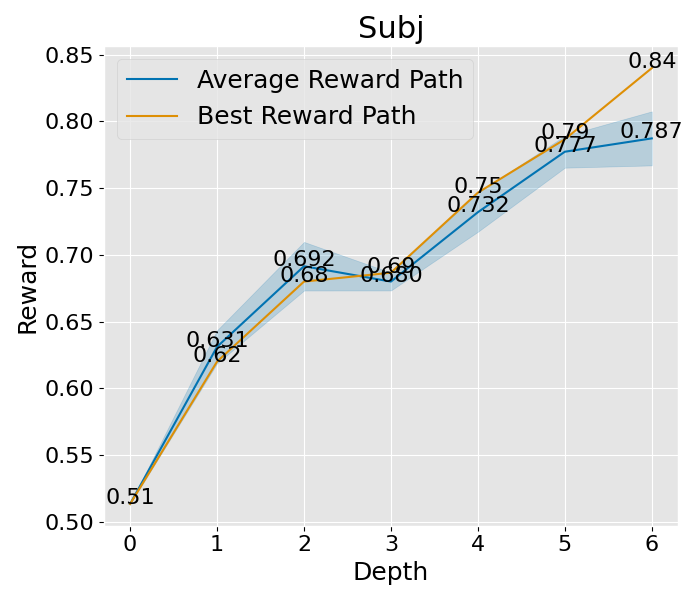 |
图 8: 这是在“宽阔”设置下的收敛曲线,其中展开宽度为 3,样本数为 2,深度限制为 6。这里所说的平均奖励路径,是指所有路径平均奖励的值,而蓝色的区域则展示了这些奖励值的波动范围。至于最佳奖励路径,它代表了平均奖励最高的那一条路径,而其中的最佳节点,则是这条路径上奖励值最高的那一个节点。
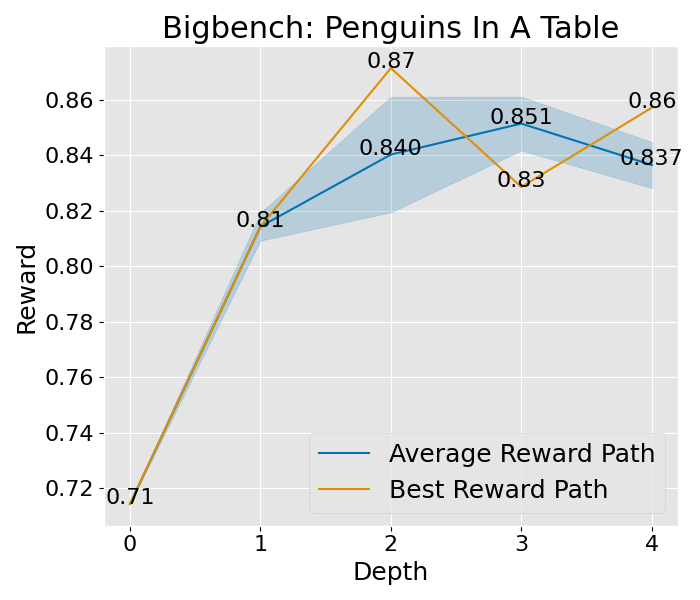 | 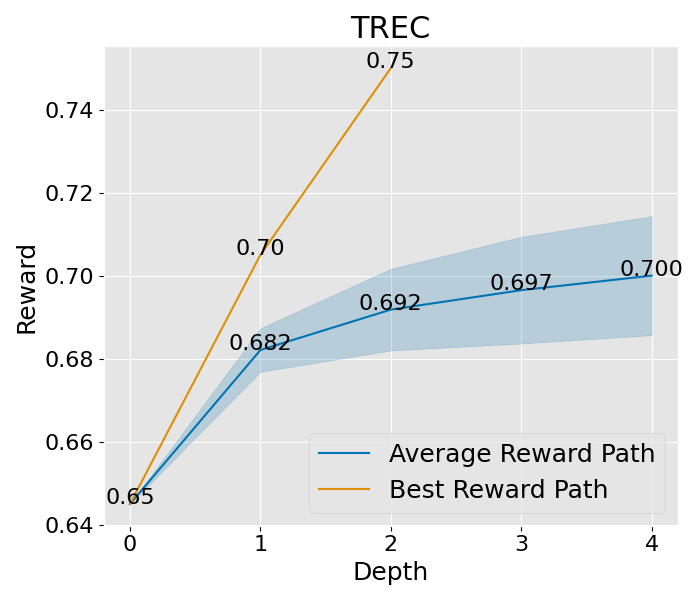 | 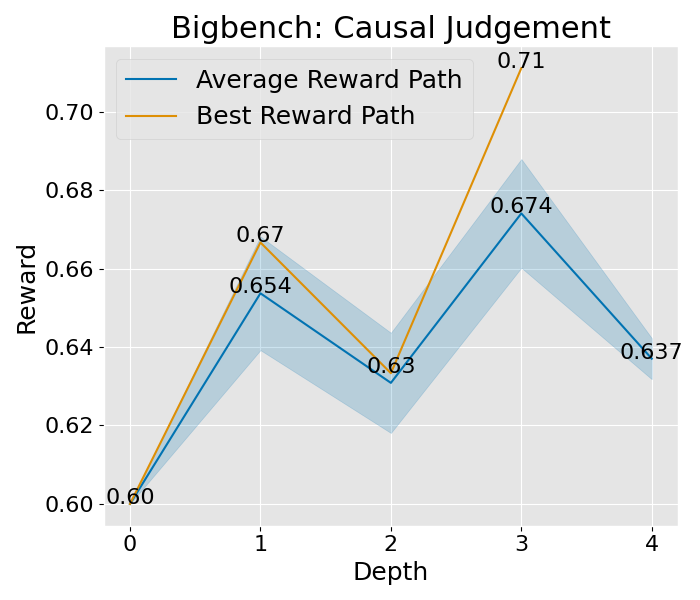 | 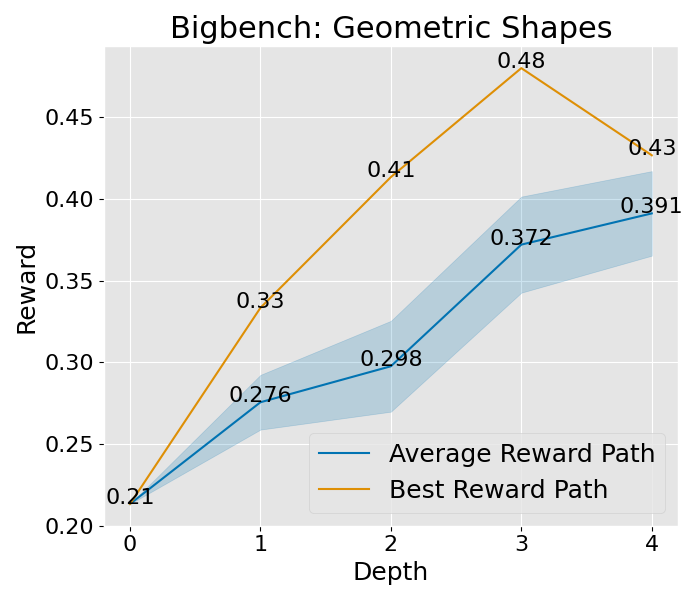 | 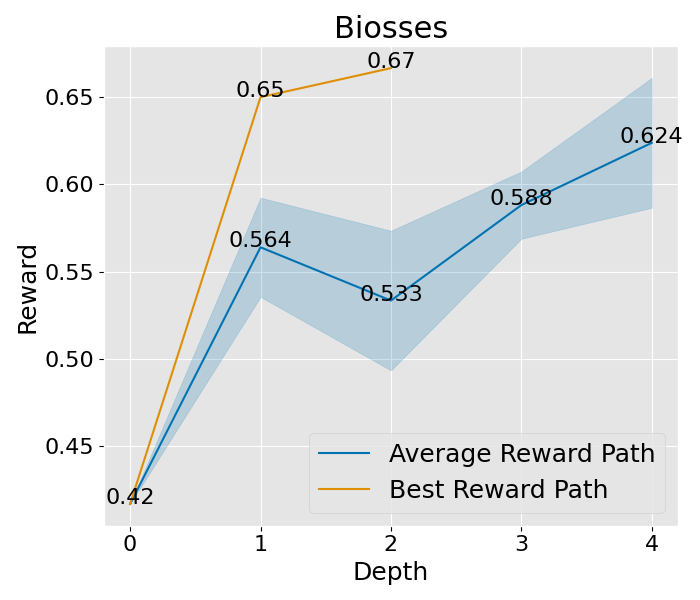 | 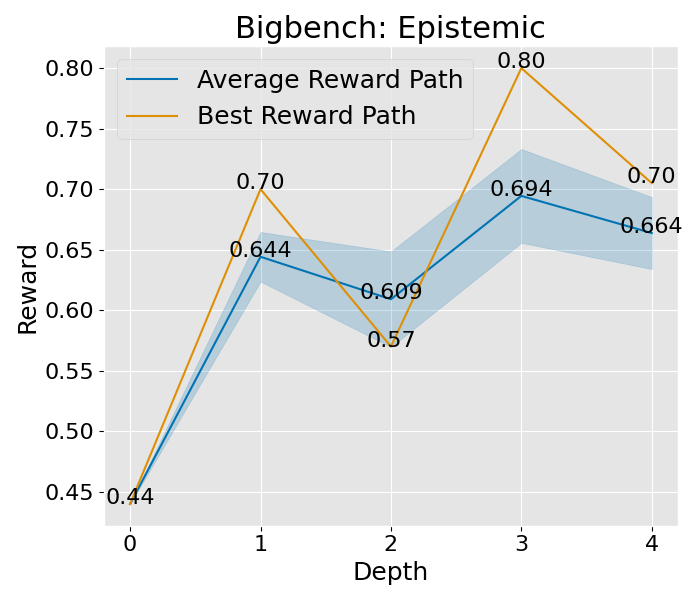 | 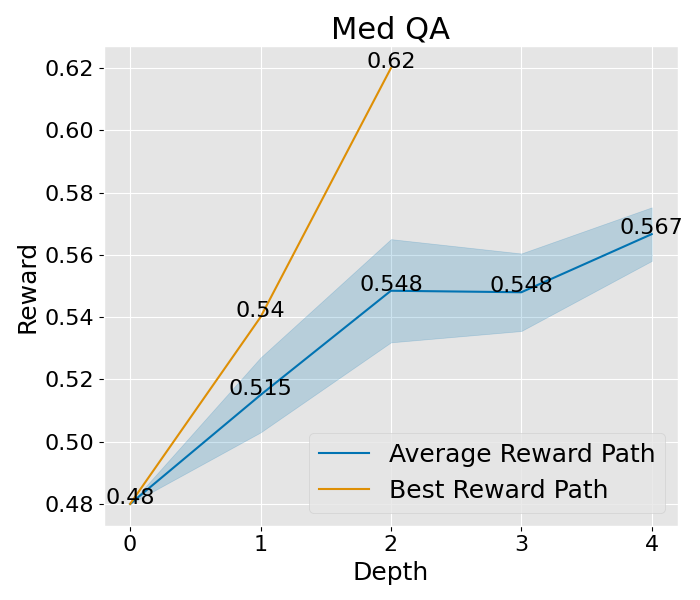 | 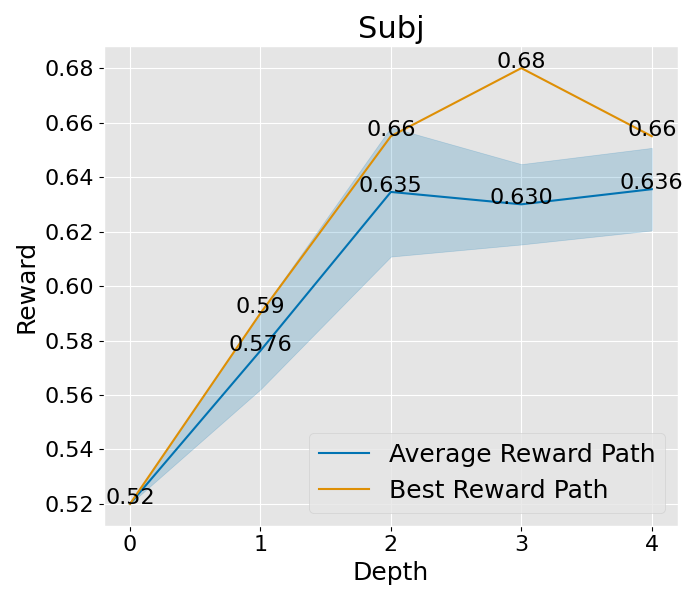 |
图 9: 这是在“轻量”设置下的收敛曲线,设置参数为:展开宽度为 3,样本数为 1,深度限制为 4。平均奖励路径和最佳奖励路径的定义同上,不再赘述。简单来说,这些曲线帮助我们了解在不同设置下,系统如何逐渐找到最优解的过程。
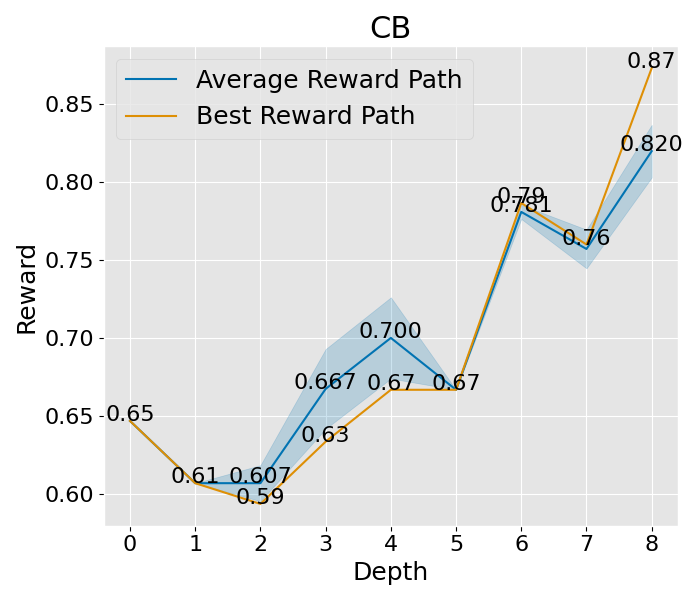 | 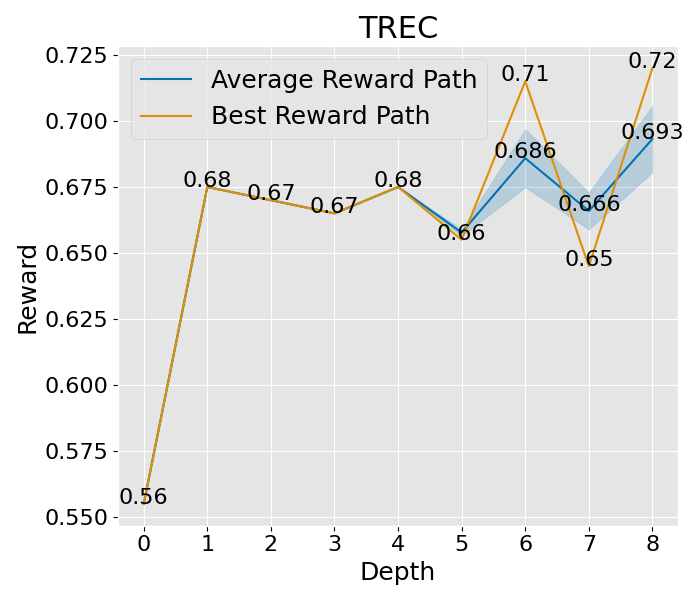 | 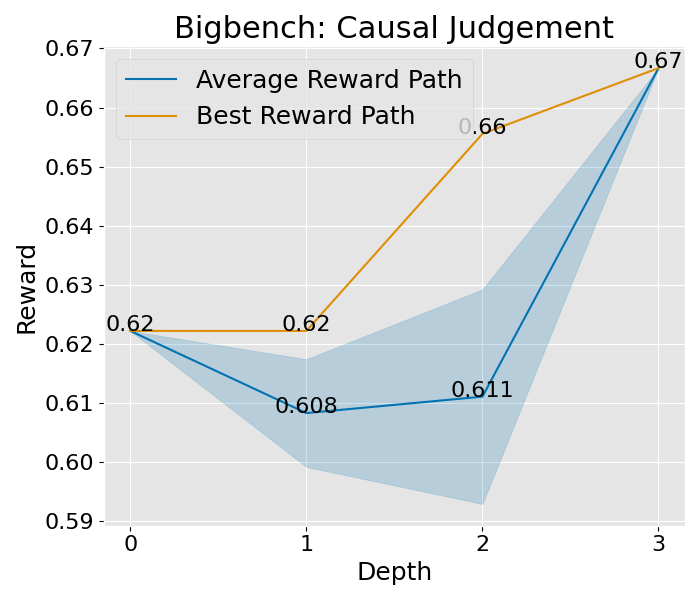 | 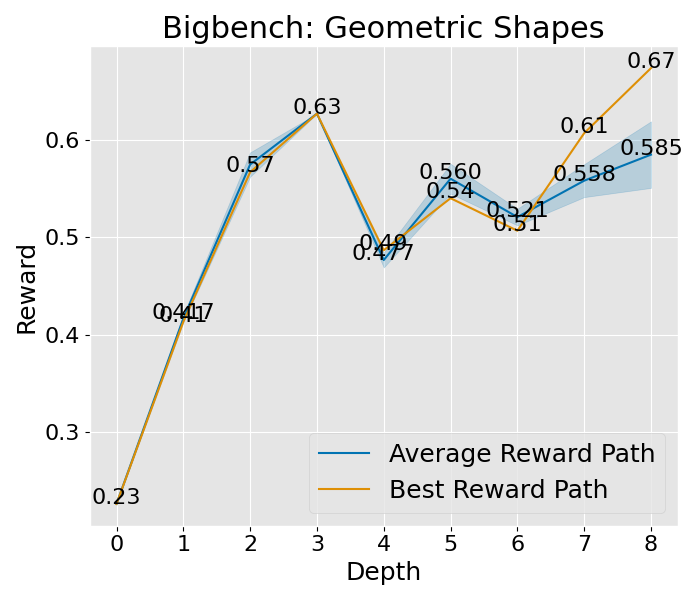 | 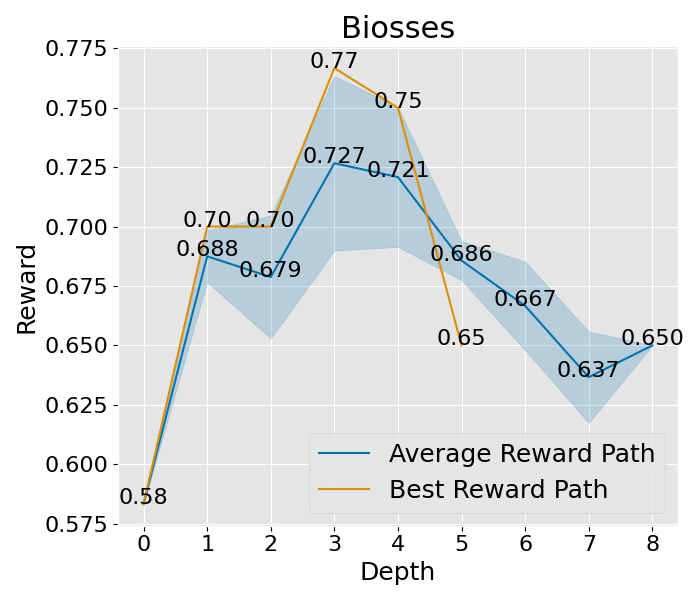 | 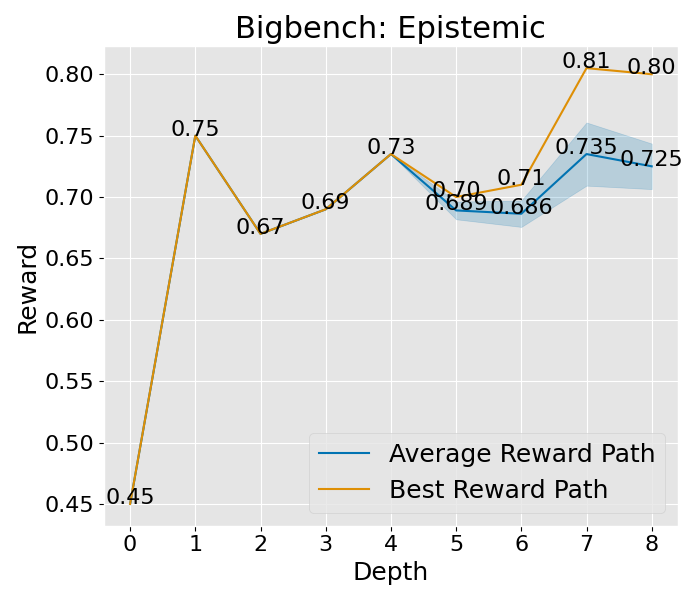 | 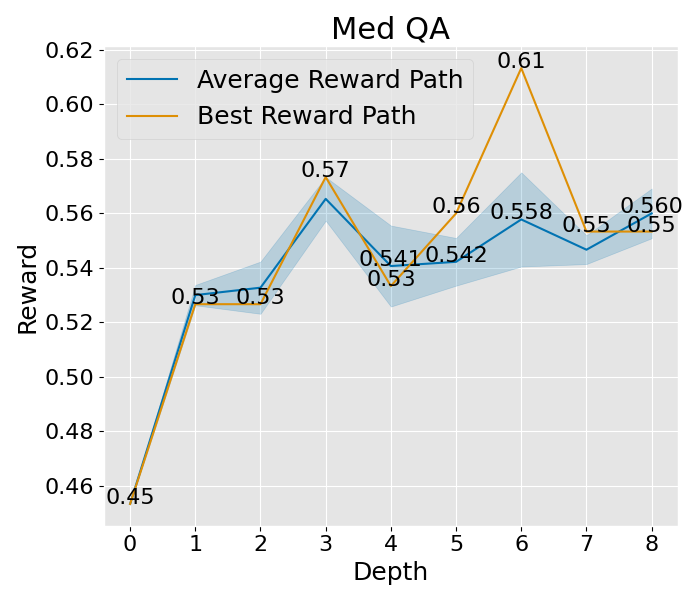 | 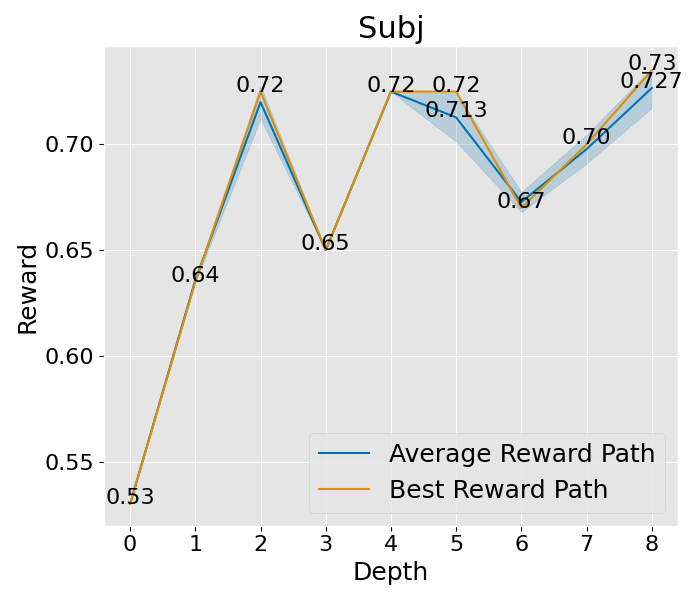 |
图 10:展示了在标准设置下的收敛趋势。这些设置包括 expand\_width=3、num\_samples=1 和 depth\_limit=8。你会看到平均的奖励曲线和其变动范围(蓝色部分表示)。而那条最显眼的线,就是在所有路径中奖励最高的,我们还特别标出了奖励最高的那个点。
附录 D 来自 PromptAgent 的提示优化示例
在这一部分,我们为大家展示了针对各种任务的优化提示,你将看到 PromptAgent 如何将普通的、人类编写的提示和 APE 优化过的提示升级成更高级的版本。
| 类型 | 优化后的提示 | 准确率 |
|---|---|---|
| 人工 | 从它们的 SVG 路径出发,给这些几何形状命名。 | 0.227 |
| APE | “弄清楚每个 SVG 路径元素所描绘的形状是什么,然后把它和给出的选项中的字母匹配起来。比如,在这个例子中,C 代表六边形,G 代表五边形,I 代表扇形,B 代表七边形。” | 0.490 |
| PromptAgent | 在这个任务中,你需要解读 SVG 路径,从而判断出它们代表的是什么几何图形。这些路径由一系列的命令组成,包括‘M’ (移动到)、‘L’ (画线到) 和‘A’ (画弧)。其中,‘M’命令用来开始一段路径,有时候还会把路径分成几个小段。但需要注意的是,不要一看到‘M’就以为是一个新的独立图形的开始,因为它们可能只是在为同一几何图形的不同部分做准备。‘L’命令用来画线段,形成图形的边界;而‘A’命令则用来画弧,它们的组合可以创造出圆形、扇形、椭圆等各种几何图形。值得一提的是,‘A’和‘L’的组合有时会形成特殊的图形,比如扇形。你需要仔细观察‘M’、‘L’和‘A’这三种命令是如何互动的,因为它们共同决定了最终图形的形状和连贯性。可能出现的图形种类繁多,从简单的直线到复杂的多边形应有尽有。如果任务中没有特别说明,“以上都不是”这个选项是无效的。在回答问题时,你需要清楚地解释每个命令的作用、它们共同作用的结果以及它们之间的关系。遇到多个‘M’命令时,不要随意将图形分割开来,而应该将它们视为构成同一图形的不同部分。即使在有‘M’命令的情况下,也要认真数清‘L’命令的数量,因为它们确定了图形的边数。要想准确无误地判断出整个图形,就需要你细致入微地检查所有的部分和命令,并保持对图形整体的连续认知。在最后确定答案之前,不妨再仔细检查一下边和弧的数量,以确保你对几何图形的识别是准确无误的。 | 0.670 |
表 9:这是一个关于几何形状任务的提示对比,包括了人工编写的提示、APE 优化过的提示,以及由 PromptAgent 优化过的专家级提示。两个基准主要是在描述任务,而我们的专家提示则包含了更为复杂的结构和深入的领域知识,因此表现更为出色。粗体文字用来标示通常需要领域专家手工制作的领域知识,而在这里,这些知识是由 PromptAgent 自动发现的。我们还用不同的颜色来突出显示专家提示中的各个部分,包括任务描述、术语解释、解决方案指导、异常处理、重点与强调、格式设置等等(为了更好的阅读体验,建议在支持颜色显示的设备上查看)。
| 方法 | 优化后的提示 | 准确率 |
| 人类 | 针对一张展示了各种企鹅及其特性的表格,回答相关问题。 | 0.595 |
| APE | 仔细检查所提供的表格,理解查询与给定信息之间的关系。准确找出相关数据,并进行必要的运算或比较,从而在众多选项中找到正确答案。 | 0.747 |
| PromptAgent | 在研究企鹅数据集的过程中,要重点关注企鹅的名字、年龄和性别等关键属性,并深刻理解这些属性在不同企鹅身上的不同含义。记住,数据集可能会发生变化,可能会有新的企鹅加入,也可能有一些企鹅被移除,当这种变化发生时,你需要立刻调整你的认知并重新进行计算,确保你后续的所有运算都考虑到了这些变动。你的主要任务是挖掘出属性之间的关系和规律,特别是要密切关注企鹅的姓名和年龄。面对复杂问题时,要将其拆解,确保不遗漏任何重要细节,并且在数据集发生变化时,要迅速重新计算,并特别注意累加或累乘等运算。确保你对“大于”、“小于”和“等于”等关系的理解准确无误,并能够根据问题的具体情境做出正确判断。并且,建立一套验证机制,确保你的答案是准确无误的,明确表述你对问题的理解和解决问题时所作的假设。注意,有时你可能需要将数据集与其他外部信息结合起来,比如,你可能需要了解某些特定年龄段的企鹅的常见姓名,或者识别出一些与名人关联的企鹅姓名。请仔细记录你关注的问题点,并在计算时保持极高的准确性,避免出现错误。最后,根据每一个新的问题灵活调整你的分析方法,这可能包括发现数字规律,理解数据的本质,或是联系外部资源以获得更全面的认识。最重要的一点,进行属性间比较,如年龄或身高时,一定要先对该属性下所有的值进行全面的审查。在对问题作出判断前,一定要先清楚问题的前提,并记住,数据集的任何变动都意味着你需要从头开始重新计算,以保证结果的准确性。 | 0.873 |
表 10:企鹅表格任务的提示对比,包括常规人类提示、APE 优化提示和 PromptAgent 优化的专家级提示。两种基线方法主要是在描述任务,而我们的专家级提示则包含了更为复杂的结构和领域特定的深刻见解,因此性能更加出色。粗体文字突出了通常由领域专家手工编写的领域知识,而在这里,这些知识是由 PromptAgent 自动发掘出来的。我们还用不同颜色标出了专家提示中的各个方面,包括任务描述、术语解释、解决方案指导、异常处理、优先级与重点以及格式(为获得最佳浏览体验,请开启颜色显示功能)。
| 方法 | 优化提示 | 准确率 |
| 人类 | 判断两个句子是否有蕴含关系。 | 0.452 |
| APE | 判断前提是否直接表达了假设的内容。如果前提明确表达了假设中提及的个人的观点或立场,那就选择“蕴含”。但如果前提表达的是别人的看法或猜测,就选择“非蕴含”。 | 0.708 |
| PromptAgent | 你的任务是仔细分析主句——也就是前提——来判断它是否确凿地支持了后面的句子或者假设的真实性。判断前提和假设之间的关系是“蕴含”还是“非蕴含”。如果前提为假设提供了充分的证据,而且不需要其他上下文信息,就认为是“蕴含”。但如果前提对假设的支持并不十分明确,那么就是“非蕴含”。理解句子内部的语义对于作出正确判断非常重要。一些表达个人看法或疑虑的词语,如“认为”、“相信”、“感觉”、“怀疑”等,可能会引入不确定性或主观性,因此不能直接视为对假设的确凿证明。同时,详细的前提也不一定就否定了一个较为泛泛的假设。例如,虽然前提中提到了“全面罩”,但这仍然与提到“口罩”的假设相符。在评估时,要始终保持对事实和逻辑的关注,只有当个人信仰或经验与句子中的事实内容紧密相关时,才应考虑纳入判断中。需要明确的是,这些都应视为个人的主观看法,而非客观的真理。在判断“蕴含”或“非蕴含”时,要简明扼要地给出你的理由,并避免草率下结论或提出没有依据的假设。你的判断应该基于前提和假设之间的事实和逻辑关系,而非其他无关因素或个人解读。在判断个人信仰的真实性或有效性时也应谨慎,除非这些信仰直接关系到前提和假设之间的事实联系。在做判断时,要细致地权衡信仰或疑虑带来的不确定性,以及确立蕴含关系时对事实精确性的需求。 | 0.806 |
表 11:Epistemic Reasoning 任务的不同提示方法对比,包括常规人类提示、APE 优化的提示和 PromptAgent 优化的专家级提示。前两者主要是对任务的描述,而我们的专家提示则更为复杂,包含了领域特定的深刻见解,从而实现了更高的性能。粗体文字代表通常需要领域专家手动制作的领域知识,而在此,这些知识是由 PromptAgent 自动发现的。我们还用不同的颜色标出了专家提示中的各个部分,包括任务描述、术语解释、解决方案指导、处理异常情况、确定优先级和强调重点、格式设置等元素(为获得最佳效果,请结合颜色观看)。
| 方法 | 优化后的提示语 | 准确率 |
| 人类 | 统计所有物品的总数。 | 0.612 |
| APE | 把所有单独和成组的物品都加在一起,计算它们的总和。 | 0.716 |
| PromptAgent | 仔细审查提供的信息,对每个提到的物品进行分类并记录其数量。如果某个物品的数量没提及,就当作一个单位计算。对于有明确数量的物品,要逐一计算并加到总数里。如果有涉及到物品分类或集合的情况,要把它们拆开,每个部分都要算进总数。总的来说,要确保计算出所有单独部分的总和,而不是子集或类型的数量。记住,要对每个物品都单独计数,而且相关的或同类的物品也要一一列出,它们的数量要准确地反映在最后的总数里。在分类和定义物品时,遵循通用的标准,仔细核对你的计数结果,确保没有算错。如有需要,根据物品的不同类别、类型或子类调整你的计数策略。最终,为每个物品或类别给出一个具体的数量,并给出一个总的单位数量,而不是类别数量。或者,根据需求,提供一个全面的总结。 | 0.86 |
表 12:在对象计数任务中,对比了人类、APE 和由 PromptAgent 优化的专家级提示语。其中人类和 APE 主要在描述任务,而我们的专家提示语则更为复杂,包含了更多领域特定的深刻见解,从而获得了更高的性能。粗体文字表示领域内通常需要专家来手工制作的知识,而在这里是由 PromptAgent 自动挖掘出来的。我们还用不同颜色来突出专家提示中的各个方面,包括任务描述、术语澄清、解决方案指导、处理异常情况、确定优先级和强调重点、以及格式设置(最好在彩色显示下查看)。
| 方法 | 优化后的提示语 | 准确率 |
| 人类 | 解答关于某些事件可能发生时间的问题。 | 0.72 |
| APE | 找出那个人可能在关闭时间之前访问指定地点的时段。 | 0.856 |
| PromptAgent | 审视一个人一整天的活动,找出他们何时有空,何时忙碌。利用这些空闲时间来确定他们可能参与其他活动的时间。刚起床的时候,一个人通常还不会立刻忙碌起来。注意任何可能的限制或关门时间,并确保活动不会在这些时间发生。避免活动时间的重叠,并在时间表上清晰标出。将空闲时间与可能进行活动的时间对照,找出最可能进行活动的时间段。 | 0.934 |
表 13:在时间序列任务中,对比了人类、APE 和由 PromptAgent 优化的专家级提示语。其中人类和 APE 主要在描述任务,而我们的专家提示语则更为复杂,包含了更多领域特定的深刻见解,从而获得了更高的性能。粗体文字表示领域内通常需要专家来手工制作的知识,而在这里是由 PromptAgent 自动挖掘出来的。我们还用不同颜色来突出专家提示中的各个方面,包括任务描述、术语澄清、解决方案指导、处理异常情况、确定优先级和强调重点、以及格式设置(最好在彩色显示下查看)。
| 方法 | 优化提示 | 准确率 |
| 人类 | 回答关于因果归因的问题。 | 0.47 |
| APE | ”对于每种情况,判断结果是故意造成的还是非故意的。如果事件背后的个人或团体意识到可能的结果并选择继续,选择‘A’。如果他们并不打算让结果发生,即使他们知道这可能会发生,选择‘B’。” | 0.57 |
| PromptAgent | 回答关于因果归因的询问,关注问题中特别强调的实体或实体。仔细研究可能同时独立运作的多因素原因,并识别个人行为背后的潜在意图。区分直接和附带的起源,并识别每个因素在创造结果中的贡献。检查直接情境和更大系统框架内因果关系的相互作用。始终坚持对上下文中提供的细节的不懈追求,并避免做出不受呈现证据支持的假设。始终考虑多个原因共同导致单一效果的复杂性,并抵制将效果归因于单一原因的诱惑。认识到原因之间可能存在的协同作用及其产生的效果。 | 0.67 |
表 14:这是一份关于因果判断任务的提示对比表,展示了人类普通提示、经 APE 优化的提示,以及经 PromptAgent 优化的专家级提示。普通提示和 APE 优化的提示主要对任务进行了描述,而专家级提示则结合了复杂的结构和专业领域的深刻见解,从而获得了更高的性能表现。值得注意的是,专家提示中的粗体文本展示了通常需要领域专家手工制作的领域知识,但在这里却能够被 PromptAgent 自动识别并应用。专家提示中不同的方面还通过颜色加以区分,包括任务描述、术语解释、解决方案引导、异常情况处理、重点与强调、格式设置等(为获得最佳阅读效果,请使用颜色显示)。
| 方法 | 优化后的提示语 | 准确率 |
|---|---|---|
| 人类 | 就因果关系的问题给出答案。 | 0.47 |
| APE | 针对每种情况判断其结果是故意造成的还是非故意的。如果事件的发起者意识到可能会导致这个结果,并且还是选择继续,那么请选择‘A’;如果他们并不想要这个结果发生,即使他们知道可能会这样,也请选择‘B’。 | 0.57 |
| PromptAgent | 针对因果关系问题给出回答,并特别关注问题中强调的个体或团体。仔细考虑可能同时并独立作用的多重因素,并弄清楚个体行为背后的真正意图。区分直接和间接的成因,并评估每个因素对结果产生的贡献。研究即时情境和更广泛系统框架中因果关系的相互作用,坚持根据所提供的上下文详细信息做出判断,避免做出缺乏证据支持的假设。牢记多重因素可能共同导致一个结果,并且避免单一成因的简单归因。认识到不同因素间可能存在的协同作用及其对结果的影响。 | 0.67 |
表 15:这是一份关于 NCBI 任务的提示对比表,展示了人类普通提示、经 APE 优化的提示,以及经 PromptAgent 优化的专家级提示。普通提示和 APE 优化的提示主要对任务进行了描述,而专家级提示则结合了复杂的结构和专业领域的深刻见解,从而获得了更高的性能表现。值得注意的是,专家提示中的粗体文本展示了通常需要领域专家手工制作的领域知识,但在这里却能够被 PromptAgent 自动识别并应用。专家提示中不同的方面还通过颜色加以区分,包括任务描述、术语解释、解决方案引导、异常情况处理、重点与强调、格式设置等(为获得最佳阅读效果,请使用颜色显示)。
| 方法 | 优化后的提示语 | F1 分数 |
|---|---|---|
| 人类 | 如果句子中提到疾病或状况,请将其提取出来。 | 0.521 |
| APE | 提取句子中提到的任何疾病或状况。 | 0.576 |
| PromptAgent | 你的任务是从句子中识别出疾病或状况,注意避免包括遗传模式、基因、蛋白质或生物途径等相关元素。此任务不要求你根据其他生物学术语来推测或假设疾病名称。请考虑具体疾病和更广泛的分类,记住疾病和状况也可能以常见的缩写或变体形式出现。请按照 {entity_1,entity_2,….} 的格式给出你识别的疾病或状况,如果没有发现任何疾病或状况,请输出一个空列表 {}. 特别注意,‘locus’这个词应该被理解为一个基因组位置,而不是疾病名称。 | 0.645 |
在表 16 中,我们展示了针对 Biosses 任务的三种不同提示方法的比较:普通人类的提示方法、经 APE 优化的提示方法,以及由 PromptAgent 优化的专家级提示方法。前两种方法主要是对任务进行了描述,而我们的专家级提示方法则运用了更为复杂的结构和深入的领域知识,因此取得了更好的效果。粗体文本代表通常需要领域专家亲自操刀的专业知识部分,在这里却是由 PromptAgent 自动挖掘出来的。我们还运用了多种颜色来突出显示专家提示中的各个方面,包括任务描述、术语解释、操作指南、异常处理、重点与优先级划分、格式调整等(颜色效果最佳)。
| 方法 | 提示方式 | 准确率 |
| 人类 | 请依赖您的医学知识来回答这些问题。 | 0.508 |
| APE | “对于每个临床情境,请认真检查所给的症状和细节。从 A-E 选项中,找出最能确定问题原因或诊断的答案。” | 0.47 |
| PromptAgent | 当你面对这些医学情境时,像拼接复杂的拼图一样处理它们。从患者的基本信息到他们近期的相关活动,每一点细节都对你的判断至关重要。避免仅根据一两个症状下结论,而应深入分析各种医学条件。不要忽略症状的时间线,因为诊断往往很大程度上取决于这些症状的起始和持续时间。在你认为找到答案之前,确保与所有选择答案进行对比验证。最终的目标不仅是准确诊断,还要确保你的结论既全面又深入 |
表 17 展示了在 Med_QA 任务中,三种不同提示方式的对比:普通人类的提示、APE 优化后的提示,以及由 PromptAgent 优化的专家级提示。前两者主要是对任务进行了描述,而专家级提示则融入了更为复杂的结构和深度的领域知识,从而取得了更好的性能。其中加粗的文本代表了通常需要领域专家亲自操刀的领域知识部分,但通过 PromptAgent,这些内容得以自动生成。为了让你更好地理解专家提示的构成,我们还用不同的颜色标注了其包含的各个要素,包括任务的具体描述、术语的明确解释、解题的具体指导、如何处理特殊情况、在不同元素间的优先级和强调,以及整体的格式安排(为获得最佳阅读体验,请开启颜色显示功能)。
| 方法 | 优化后的提示 | 准确率 |
|---|---|---|
| 人类 | 判断文本是表达主观意见还是客观事实。 | 0.517 |
| APE | 分析文本是在陈述事实和细节,还是表达个人情感和选择。 | 0.696 |
| PromptAgent | 仔细阅读文本,判断其是表达作者的个人感受和观点,还是在客观描述事实或情况。注意,情感丰富和描述详细并不一定意味着作者在表达个人观点。同样,使用非常规标点符号和提问方式也不应直接视为作者主观色彩的体现。我们需要区分作者和文中角色的主观性,避免将角色的情感误解为作者的个人倾向。我们的重点应该放在分析作者在叙述中的立场上,而不是单纯关注文中的角色。请遵循这些指导原则,认真分析文本。 | 0.806 |
表格 18: 对于判断文本主观或客观的任务,这里展示了三种不同方法的比较:常规人类方法、由 APE 系统优化的方法,以及由 PromptAgent 系统优化的专家级方法。虽然前两种方法主要是在描述任务,但我们的专家级提示则更为复杂且包含了领域内的深刻见解,因此性能更为出色。粗体字部分显示了那些通常需要领域专家手动提炼的知识点,但在这里却是由 PromptAgent 自动发现并利用的。通过不同的颜色,我们还展示了专家提示中的各个要素,如任务说明、术语解释、解决方案指引、如何处理异常情况、确定优先级和强调重点、以及格式设置等。(为了最佳观看效果,建议使用彩色显示)
| 方法 | 优化后的提示 | 准确率 |
|---|---|---|
| 人类 | 根据问题的主题为文本贴上标签,选项包括人、地点、事物、概念等。 | 0.742 |
| APE | 分析问题的主题,然后根据问题的核心内容为文本选择最合适的标签。 | 0.834 |
| PromptAgent | 首先判断问题想要得到什么类型的回答,然后从给定的选项中选择最能反映这一意图的标签。请特别注意区分问题本身和问题想要得到的答案类型,优先标记出最主要的答案内容。如果一个标签无法全面覆盖问题的所有意图,可以选择多个标签。最终的标签应该反映预期答案的实质,而不仅仅是问题本身的内容或某些附带特征。请认真考虑,选择最能代表问题主要意图的标签。 | 0.886 |
表 19:这是一个关于 TREC 任务的提示对比表格,包括普通人类给出的提示、APE 系统优化后的提示,以及由 PromptAgent 优化后的专家级提示。基线测试主要是对任务进行了描述,而我们的专家级提示则更为复杂和深入,包含了更多特定领域的见解,因此性能更优。粗体字部分代表领域内的专业知识,通常需要由领域专家来手工制作,但在这里,它们是由 PromptAgent 自动发现的。我们还用不同的颜色来突出专家提示中的各个方面,例如任务是什么、术语是怎么定义的、如何指导解决方案、如何处理异常情况、什么最重要且需要强调、以及格式应该是什么样的(为获得最佳浏览体验,请使用彩色显示)。
| 方法 | 优化后的提示 | 准确率 |
| 人类 | 仔细阅读这两个观点,并判断它们之间是什么关系,可能是矛盾、中立或者蕴涵。 | 0.714 |
| APE | “弄清楚这两个观点之间的联系。如果第二个观点是对第一个观点的合理推论或者是由其衍生出来的,那么这是一种蕴涵关系。如果两者相互矛盾或者冲突,这就是矛盾关系。如果两者之间没有直接的关系,那么就是中立关系。” | 0.8036 |
| PromptAgent | 你的任务是深入挖掘这两个观点,并重点关注对话中提到的关键信息和主要元素,同时要考虑语言可能的多种表达方式。认识到第二个观点可能以不同的方式反映或重述第一个观点的内容,有时甚至可能是一种简化的表达。但记住,单纯的重复并不意味着这是一种蕴涵关系。第二个观点中的重述应体现第一个观点中的核心思想,这样才能被归类为蕴涵关系。如果第二个观点与第一个观点完全相反,请将其标记为矛盾关系。当两个观点看似没有直接联系或关系不明确时,使用中立标记。在处理含糊不清的情况时要特别小心,努力在第二个观点的语境中找到答案,不要被一些细微或假设性的表述所误导。请确保你的判断(蕴涵、矛盾或中立)完全基于两个观点之间的关系,不要受到个人观点或结论的影响。重点应放在理解对话的主旨和上下文上,而不是单纯地重复词语或短语。 | 0.911 |
表 20:这是一个关于 CB 任务的提示对比表格,包括普通人类给出的提示、APE 系统优化后的提示,以及由 PromptAgent 优化后的专家级提示。基线测试主要是对任务进行了描述,而我们的专家级提示则更为复杂和深入,包含了更多特定领域的见解,因此性能更优。粗体字部分代表领域内的专业知识,通常需要由领域专家来手工制作,但在这里,它们是由 PromptAgent 自动发现的。我们还用不同的颜色来突出专家提示中的各个方面,例如任务是什么、术语是怎么定义的、如何指导解决方案、如何处理异常情况、什么最重要且需要强调、以及格式应该是什么样的(为获得最佳浏览体验,请使用彩色显示)。