苹果新推出的设备内及云端服务器基础模型介绍 [译]
在 2024 年全球开发者大会上,我们向大家展示了苹果智能系统,这是一套深度融入 iOS 18、iPadOS 18 及 macOS Sequoia 的个人智能体系。
这一系统集成了多个功能强大的生成式 AI,专为处理用户日常需求而设计,能够根据用户当前的活动实时调整。苹果智能中的基础模型经过专门微调,以优化各种用户体验,如文本编写、通知的排序与摘要、为家庭及朋友对话创造有趣的图像,以及简化应用间的交互操作。
我们将在后续概述中详细介绍其中的两款模型 — 一款约三亿参数的设备内语言模型及一款规模更大的服务器端语言模型,后者通过私有云计算服务在苹果硅质服务器上运行 — 这两款模型如何高效、精确、负责任地完成特定任务。这两款基础模型是苹果为支持用户和开发者而创建的生成式模型家族中的一部分,家族中还包括一个在 Xcode 中增添智能的编程模型,以及一个帮助用户在消息应用中进行视觉表达的扩散模型。我们期待不久后能分享这一系列模型的更多详情。
我们致力于负责任的 AI 开发
苹果智能的设计始终贯彻我们的核心价值,并以开创性的隐私技术为基础。
我们还设立了一套负责任 AI 原则,指导我们的 AI 工具和模型开发:
- 智能赋能:我们识别哪些领域的 AI 可以负责任地开发,用以满足用户的具体需求。我们尊重用户如何利用这些工具达成目标。
- 真实代表用户:我们的产品深度个性化,目标是真实地反映全球用户的多样性。我们持续努力,避免 AI 工具和模型中存在的刻板印象和偏见。
- 严谨设计:我们在设计、模型训练、功能开发和质量评估的每个阶段都会谨慎行事,防止 AI 工具被滥用或带来潜在风险。我们会不断根据用户反馈优化我们的 AI 工具。
- 重视隐私保护:我们利用先进的设备内处理和私有云计算等基础设施,坚决保护用户隐私。在训练基础模型时,我们不利用任何用户的私人数据或互动信息。
这些原则体现在支撑苹果智能的整体架构中,确保特定模型和工具之间的有效连接,并对输入和输出进行检测,确保各项功能能负责任地运作。
在概述的剩余部分中,我们详细介绍了相关决策,比如我们如何开发出高效、快速且节能的模型;我们的训练方法;适配器如何针对用户需求进行精准调整;以及我们如何评估模型的有效性和潜在风险。

Pre-Training
我们的先进模型在 苹果的 AXLearn 框架上接受训练,这是我们于 2023 年推出的一个开源项目。该框架基于 JAX 和 XLA,能够让我们在各种训练硬件及云服务上,包括 TPU 与云端及现场 GPU,实现高效和可扩展的模型训练。我们采用数据并行、张量并行、序列并行和完全分片数据并行(FSDP)技术,在多个维度如数据、模型大小和序列长度等方面进行扩展。
我们在经授权的数据上训练这些模型,涵盖了用于强化特定特性的选定数据和我们的网络爬虫 AppleBot 收集的公开数据。网站运营者可以通过 选择退出 控制其网页内容不被用于苹果智能训练。
在训练过程中,我们绝不利用用户的私人信息或互动数据,并采取措施删除网络上公开的个人识别信息,如社会保障号和信用卡信息。我们还剔除了不雅词汇及其他质量低下的内容,确保这些不会融入训练数据集中。此外,我们还进行了数据的提取、去重及使用基于模型的分类器来筛选高质量的文档。
Post-Training
我们认识到数据质量对模型成功的重要性,因此在训练管道中采用了混合数据策略,结合了人工标注数据和合成数据,并进行了全面的数据整理和过滤。我们在训练后开发了两种新算法:(1)拒绝采样微调算法,该算法由教师委员会监督;(2)从人类反馈中强化学习(RLHF)算法,结合了镜像下降策略优化和留一出优势估计器。我们发现,这两种算法显著提升了模型的指令执行质量。
优化
除了确保我们的生成式 AI 模型极具能力外,我们还采用了多种创新技术,以提升设备和私有云中的模型运行速度和效率。我们对模型的初次 token 生成和后续 token 生成的处理性能进行了全面优化。
无论是设备上的模型还是服务器模型,都采用了分组查询注意力机制。通过共享输入输出词汇嵌入表,我们有效减少了内存使用和计算成本。这些共享嵌入表设计巧妙,避免了数据的重复。设备端模型的词汇量为 49K,而服务器端模型的词汇量达到 100K,增加了许多专业语言和技术相关的 token。
在设备端推断中,我们应用了低比特率调色技术,这是一项关键优化手段,帮助满足内存、电力和性能的需求。为保证模型的准确性,我们还创新开发了一个基于 LoRA 适配技术的框架,采用了 2 位与 4 位混合配置,平均每个权重 3.5 位,以确保与未压缩模型相同的效果。
我们还利用了 Talaria 交互式模型延迟和功率分析工具来优化每一步骤的比特率选择,同时实施了激活量化和嵌入量化。此外,我们还开发了一种在神经引擎上高效更新键 - 值缓存的方法。
通过这些优化措施,在 iPhone 15 Pro 上,我们实现了每个提示 token 大约 0.6 毫秒的首次响应时间,并且可以每秒生成 30 个 token。值得一提的是,在采用 token 预测技术之前,我们就已经实现了这样的高性能。
模型的适应
我们的基础大语言模型经过精细调整,能够针对用户的日常活动进行优化,并可即时根据特定任务进行专门调整。我们利用了适配器,这种小型的神经网络模块可插入预训练模型的多个层中,专为各种任务定制。我们调整了 Transformer 架构中解码层的注意力矩阵、注意力投影矩阵以及点式前馈网络中的全连接层。
通过专门调整适配器层,保留了模型的通用知识,同时确保基础模型的原始参数不变,为特定任务提供支持。
图 2: 适配器是一组小型的模型权重集合,附加在通用的基础模型上。这些适配器可以随时加载和替换,使基础模型能够即时针对特定任务进行专门化。Apple Intelligence 提供了多种适配器,每一种都针对特定功能进行了微调,这是一种扩展模型功能的高效方法。
我们将适配器参数设为 16 位,对于约 30 亿参数的设备模型,一个 16 等级的适配器通常需要数十兆的存储空间。这些适配器可以被动态加载,并且可以暂时存储在内存中进行交换,从而在不占用过多系统资源的同时,增强模型的特定任务处理能力。
为了便于适配器的快速训练和部署,我们建立了一套高效的系统,可在基础模型或数据更新后迅速进行适配器的训练、测试和部署。适配器的初始参数设置基于我们在优化部分提到的准确性恢复技术。
性能评价与分析
我们的目标是提供能使用户在苹果产品中沟通、工作、自我表达和完成任务的生成式模型。在基准测试中,我们注重人类评估,因为这些评估与产品中的用户体验密切相关。我们对针对特定功能的适配器和基础模型进行了全面的性能评价。
举例来说,我们评估摘要适配器的过程如下。鉴于电子邮件和通知摘要的需求各有不同,我们在调色板化模型基础上微调了 LoRA 适配器,以确保满足这些需求。我们的训练数据来源于大型服务器模型生成的合成摘要,经过精选,只留下高质量的摘要。
为评估针对特定产品的摘要功能,我们针对每种应用场景精选了 750 个响应进行测试。这些数据集涵盖了产品可能面对的多种输入情况,包括各种类型和长度的文档。评估这些与真实应用场景相符的数据集对于产品特性极为重要。结果显示,我们的适配器模型在摘要生成上优于同类模型。
在负责任开发的过程中,我们特别关注摘要可能的风险。例如,摘要有时可能会丢失重要的细节,这是不希望看到的。但我们的测试显示,适配器在绝大多数对抗性测试中没有放大敏感内容。我们将持续进行对抗性测试,识别潜在风险,并通过持续的评估推动产品的持续优化。
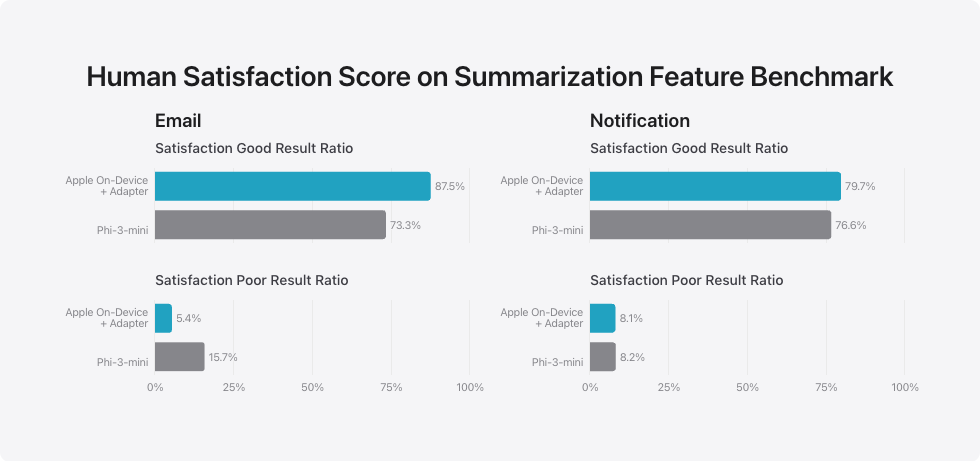
对摘要功能的人类满意度评估
电子邮件
满意度高的结果比例
- Phi-3-mini: 73.3%
- 苹果设备内 + 适配器:87.5%
Phi-3-mini 苹果设备内 + 适配器 73.3%87.5%
满意度低的结果比例
- Phi-3-mini: 15.7%
- 苹果设备内 + 适配器:5.4%
0%25%50%75%100%Phi-3-mini 苹果设备内 + 适配器 15.7%5.4%
通知
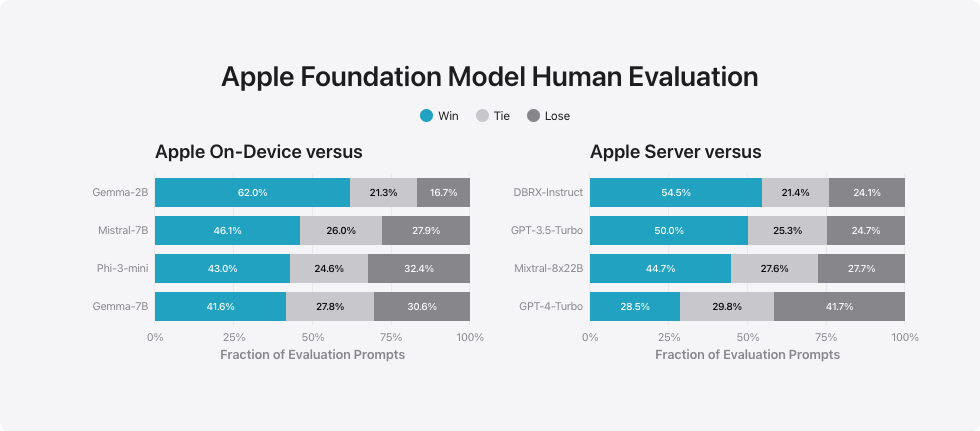
除了评估由基础模型和适配器驱动的特定功能外,我们还评估了设备端和服务器端模型的整体性能。我们使用了一个全面的评估集,包含真实世界中的各种提示,来测试模型的整体能力。这些提示涵盖了不同难度级别的主要类别,例如头脑风暴、分类、封闭问答、编码、信息提取、数学推理、开放问答、重写、安全性、摘要和写作。
我们将我们的模型与开源模型(Phi-3、Gemma、Mistral、DBRX)和同等规模的商业模型(GPT-3.5-Turbo、GPT-4-Turbo)进行了比较。结果显示,我们的模型在大多数情况下比同类竞争模型更受人类评分员的青睐。在这个基准测试中,我们的设备端模型(约 3B 参数)优于包括 Phi-3-mini、Mistral-7B 和 Gemma-7B 在内的更大模型。我们的服务器端模型在与 DBRX-Instruct、Mixtral-8x22B 和 GPT-3.5-Turbo 的对比中表现良好,并且效率很高。
苹果设备内对比
- 与 Gemma-2B 的对比:苹果设备内赢 62.0%,平 21.3%,输 16.7%。
- 与 Mistral-7B 的对比:苹果设备内赢 46.1%,平 26.0%,输 27.9%。
- 与 Phi-3-mini 的对比:苹果设备内赢 43.0%,平 24.6%,输 32.4%。
- 与 Gemma-7B 的对比:苹果设备内赢 41.6%,平 27.8%,输 30.6%。
Gemma-2B, Mistral-7B, Phi-3-mini, Gemma-7B:各类评估提示的胜平负统计比例分别是 0%、25%、50%、75%、100%,数据显示:62.0%、46.1%、43.0%、41.6% 胜出;21.3%、26.0%、24.6%、27.8% 平局;16.7%、27.9%、32.4%、30.6% 失败。
苹果服务器对比其他模型
- 与 DBRX-Instruct 的比较:胜率 54.5%,平局率 21.4%,败率 24.1%。
- 与 GPT-3.5-Turbo 的比较:胜率 50.0%,平局率 25.3%,败率 24.7%。
- 与 Mixtral-8x22B 的比较:胜率 44.7%,平局率 27.6%,败率 27.7%。
- 与 GPT-4-Turbo 的比较:胜率 28.5%,平局率 29.8%,败率 41.7%。
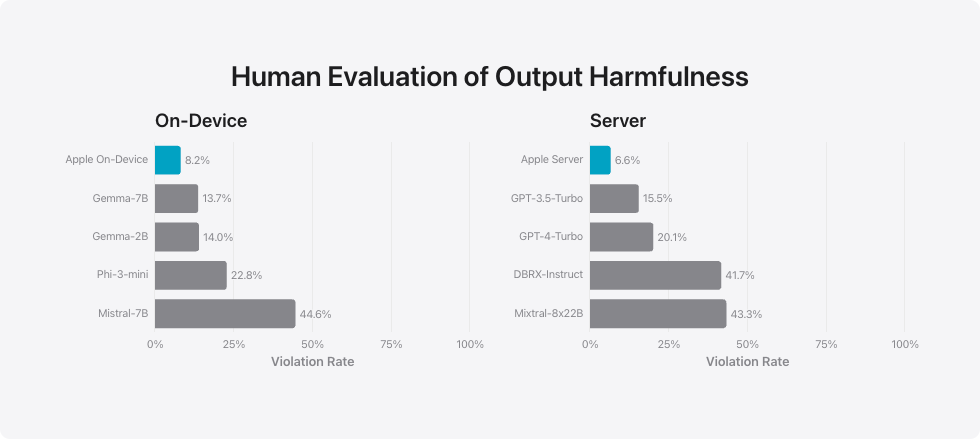
为了评估模型在处理有害内容、敏感主题及事实性问题上的效能,我们采用了一系列多样化的对抗性提示。这些模型的违规率由人类评审员在这些测试中测得,违规率越低越好。面对对抗性提示时,苹果公司的设备内模型和服务器模型都显示出了优越的抗压性,违规率低于多数开源及商业模型。
设备上的输出有害性人类评估
设备内
- Mistral-7B:44.6%
- Phi-3-mini:22.8%
- Gemma-2B:14.0%
- Gemma-7B:13.7%
- 苹果设备内:8.2%
图:在这些设备上测试时,违规率从高到低依次是:Mistral-7B 44.6%,Phi-3-mini 22.8%,Gemma-2B 14.0%,Gemma-7B 13.7%,苹果设备内 8.2%。
服务器性能
- Mixtral-8x22B: 43.3%
- DBRX-Instruct: 41.7%
- GPT-4-Turbo: 20.1%
- GPT-3.5-Turbo: 15.5%
- Apple 服务器:6.6%
0%25%50%75%100% 违规响应比例 Mixtral-8x22BDBRX-InstructGPT-4-TurboGPT-3.5-TurboApple Server43.3%41.7%20.1%15.5%6.6%
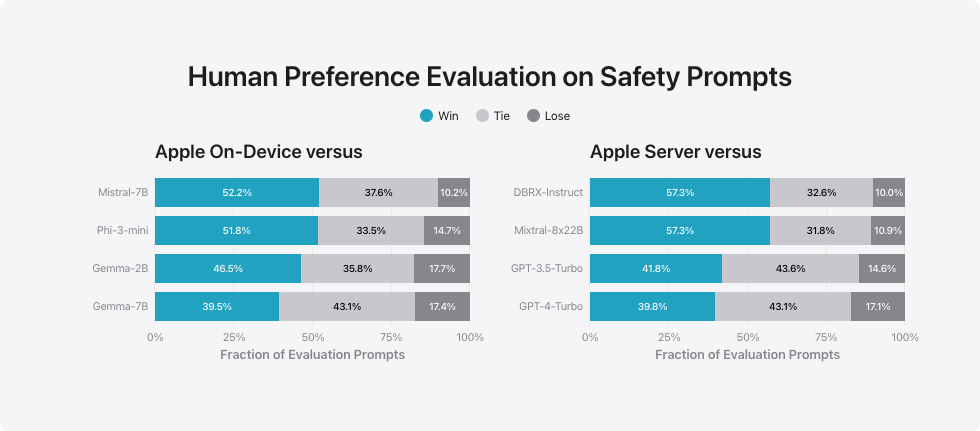
在人类评估中,相较于竞争对手的模型,我们的模型因其安全性和实用性被更多地推荐。然而,鉴于大型语言模型的广泛应用,我们认识到我们安全基准的局限性。我们正与内外部团队合作进行手动及自动的红队测试,以不断检验我们模型的安全性。
针对安全提示的人类偏好评估
胜出
平手
落败
Apple 设备对比
- Apple 设备与 Mistral-7B 的比较:胜出 52.2%,平手 37.6%,落败 10.2%。
- Apple 设备与 Phi-3-mini 的比较:胜出 51.8%,平手 33.5%,落败 14.7%。
- Apple 设备与 Gemma-2B 的比较:胜出 46.5%,平手 35.8%,落败 17.7%。
- Apple 设备与 Gemma-7B 的比较:胜出 39.5%,平手 43.1%,落败 17.4%。
Mistral-7BPhi-3-miniGemma-2BGemma-7B0%25%50%75%100% 测评比例 52.2%51.8%46.5%39.5%37.6%33.5%35.8%43.1%10.2%14.7%17.7%17.4%
苹果服务器的比较
- 苹果服务器对比 DBRX-Instruct:胜率 57.3%,平局 32.6%,败率 10.0%。
- 苹果服务器对比 Mixtral-8x22B:胜率 57.3%,平局 31.8%,败率 10.9%。
- 苹果服务器对比 GPT-3.5-Turbo:胜率 41.8%,平局 43.6%,败率 14.6%。
- 苹果服务器对比 GPT-4-Turbo:胜率 39.8%,平局 43.1%,败率 17.1%。
DBRX-Instruct、Mixtral-8x22B、GPT-3.5-Turbo、GPT-4-Turbo 0% 至 100%:57.3%,57.3%,41.8%,39.8%,32.6%,31.8%,43.6%,43.1%,10.0%,10.9%,14.6%,17.1%。
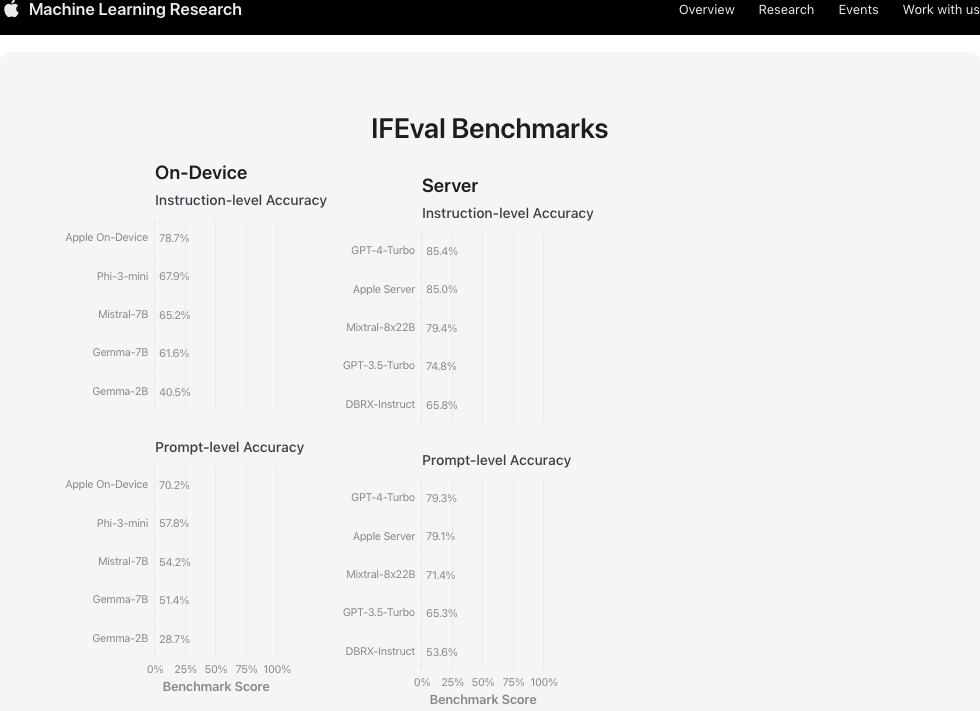
进一步评估我们的模型时,我们采用指令遵从评估(IFEval)基准,与其他相同规模的模型比较它们遵循指令的能力。结果显示,无论是设备内模型还是服务器模型,都比相同规模的开源及商业模型表现更好。
IFEval 基准
设备内
指令级准确性
- Gemma-2B:40.5%
- Gemma-7B:61.6%
- Mistral-7B:65.2%
- Phi-3-mini:67.9%
- Apple 设备内:78.7%
Gemma-2B、Gemma-7B、Mistral-7B、Phi-3-mini、Apple 设备内:40.5%,61.6%,65.2%,67.9%,78.7%
提示级别准确性
- Gemma-2B: 28.7%
- Gemma-7B: 51.4%
- Mistral-7B: 54.2%
- Phi-3-mini: 57.8%
- Apple 设备端:70.2%
0% 25% 50% 75% 100% 基准得分 Gemma-2B Gemma-7B Mistral-7B Phi-3-mini Apple 设备端 28.7% 51.4% 54.2% 57.8% 70.2%
服务器端
指令级准确性
- DBRX-Instruct(DBRX-Instruct): 65.8%
- GPT-3.5-Turbo(GPT-3.5-Turbo): 74.8%
- Mixtral-8x22B(Mixtral-8x22B): 79.4%
- Apple 服务器(Apple Server): 85.0%
- GPT-4-Turbo(GPT-4-Turbo): 85.4%
DBRX-Instruct GPT-3.5-Turbo Mixtral-8x22B Apple 服务器 GPT-4-Turbo 65.8% 74.8% 79.4% 85.0% 85.4%
指令响应准确性
- DBRX-Instruct: 53.6%
- GPT-3.5-Turbo: 65.3%
- Mixtral-8x22B: 71.4%
- Apple Server: 79.1%
- GPT-4-Turbo: 79.3%
0%25%50%75%100% 基准得分 DBRX-InstructGPT-3.5-TurboMixtral-8x22BApple ServerGPT-4-Turbo53.6%65.3%71.4%79.1%79.3%
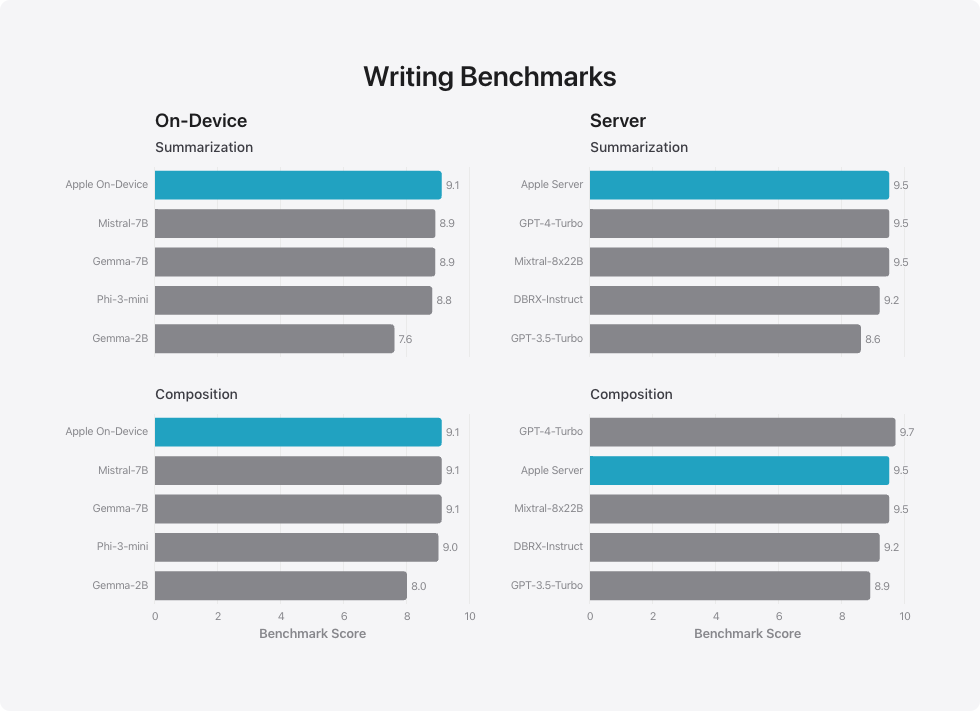
我们对模型进行了内部的总结性和创作性写作能力测试,涉及多种写作指令。这些结果没有考虑到我们为总结特别设计的适配器(详见图 3),我们也没有一个专门针对创作的适配器。
写作能力基准
设备内
总结
- Gemma-2B: 7.6
- Phi-3-mini: 8.8
- Gemma-7B: 8.9
- Mistral-7B: 8.9
- Apple 设备内:9.1
Gemma-2BPhi-3-miniGemma-7BMistral-7BApple 设备内 7.68.88.98.99.1
创作
- Gemma-2B: 8.0
- Phi-3-mini: 9.0
- Gemma-7B: 9.1
- Mistral-7B: 9.1
- Apple 设备内:9.1
0246810 基准得分 Gemma-2BPhi-3-miniGemma-7BMistral-7BApple 设备内 8.09.09.19.19.1
服务器
概览
- GPT-3.5-Turbo: 8.6
- DBRX-Instruct: 9.2
- Mixtral-8x22B: 9.5
- GPT-4-Turbo: 9.5
- Apple Server: 9.5
GPT-3.5-Turbo, DBRX-Instruct, Mixtral-8x22B, GPT-4-Turbo, Apple Server 分别得分 8.6, 9.2, 9.5, 9.5, 9.5
构成
- GPT-3.5-Turbo: 8.9
- DBRX-Instruct: 9.2
- Mixtral-8x22B: 9.5
- Apple Server: 9.5
- GPT-4-Turbo: 9.7
得分 8.9, 9.2, 9.5, 9.5, 9.7 分别对应于 GPT-3.5-Turbo, DBRX-Instruct, Mixtral-8x22B, Apple Server, GPT-4-Turbo
结论
在 WWDC24 推出的 Apple 基础模型和适配器,形成了新的个人智能系统 Apple Intelligence,该系统深入整合进 iPhone、iPad 和 Mac 中,提供了覆盖语言、图像、操作及个人上下文的强大功能。我们的模型设计旨在帮助用户更好地使用 Apple 产品进行日常活动,并在开发的每个阶段都秉承 Apple 的核心价值观进行负责任的开发。我们期待不久后分享更多关于我们的语言、扩散和编码等广泛的生成模型系列的信息。
脚注
[1] 我们将这些模型与 gpt-3.5-turbo-0125、gpt-4-0125-preview、Phi-3-mini-4k-instruct、Mistral-7B-Instruct-v0.2、Mixtral-8x22B-Instruct-v0.1、Gemma-1.1-2B 和 Gemma-1.1-7B 进行了比较,无论是开源模型还是 Apple 模型均在 bfloat16 精度下进行了评估。