优化 Character.AI 的 AI 推理 [译]
优化 Character.AI 的 AI 推理

在 Character.AI,我们正朝着通用人工智能 (AGI) 的目标迈进。在未来,大语言模型 (LLMs) 将会增强我们的日常生活,不仅提高商业生产力和娱乐效果,还能在教育、教练、支持、头脑风暴、创意写作等方面提供帮助。
要在全球实现这一愿景,关键在于实现高效的“推理”,即 LLM 生成回复的过程。作为一家全栈 AI 公司,Character.AI 从头开始设计其模型架构、推理架构和产品,创造了独特的机会来优化推理,使其更高效、更具成本效益,并能扩展以满足快速增长的全球用户需求。
目前,我们每秒处理超过 20,000 次推理查询。为了让大家对这个数字有个具体的概念,这相当于 Google 搜索请求量的 20%,据第三方估计,Google 每秒处理大约 105,000 次查询 (Statista, 2024)。
我们之所以能够在如此规模上稳定地提供 LLM 服务,是因为我们在服务架构中开发了一系列关键创新。在这篇博客文章中,我们将分享过去两年中开发并最近采用的一些技术和优化方法。
内存高效的架构设计
在 LLM 推理中,吞吐量的关键瓶颈是注意力键和值(KV,Key-Value)的缓存大小。它不仅决定了 GPU 上可以处理的最大批量大小,还影响了注意力层的 I/O 成本。我们采用以下技术将 KV 缓存大小减少了超过 20 倍,同时保证了质量不受影响。这些技术使得 GPU 内存不再是处理大批量数据的瓶颈。
1. 多查询注意力 (Multi-Query Attention)。我们在所有注意力层中采用了多查询注意力 (Shazeer, 2019)。相比大多数开源模型中使用的分组查询注意力,这项技术将 KV 缓存大小减少了 8 倍。
2. 混合注意力视界 (Hybrid Attention Horizons)。我们将局部注意力 (Beltagy et al., 2020) 与全局注意力层交替使用。局部注意力通过滑动窗口(sliding windows)技术进行训练,将复杂度从 O(length^2) 降低到 O(length)。我们发现,将大多数注意力层的注意力视界减少到 1024 对评估指标,包括长上下文的 needle-in-haystack 基准测试,影响不大。在我们的生产模型中,每 6 层中仅有 1 层使用全局注意力。
3. 跨层 KV 共享 (Cross Layer KV-sharing)。我们将相邻注意力层的 KV 缓存绑定在一起,这进一步将 KV 缓存大小减少了 2-3 倍。对于全局注意力层,我们将多个全局层的 KV 缓存跨块绑定在一起,因为在长上下文使用情况下,全局注意力层主导了 KV 缓存大小。类似于最近的一篇论文 (Brandon et al., 2024),我们发现跨层共享 KV 不会影响质量。

状态缓存
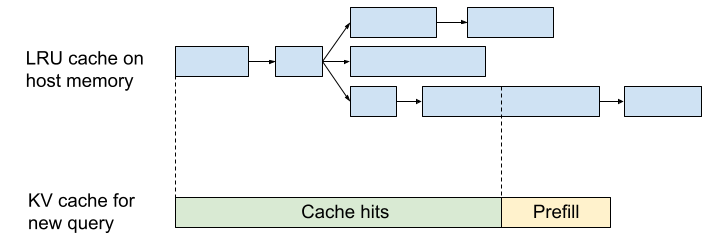
我们的一项关键创新是在聊天轮次之间有效缓存注意力键和值(KV,Key-Value)的系统。在 Character.AI 上,大多数聊天是长对话;平均每条消息有 180 条对话历史。随着对话的加长,每次轮次都重新填充 KV 缓存的成本将非常高。
为了解决这个问题,我们开发了一个轮次间缓存系统。对于每个预填充的前缀和生成的消息,我们将 KV 值缓存到主存中,并在将来的查询中检索它们。类似于 RadixAttention (Zheng et al., 2023),我们将缓存的 KV 张量组织在具有树结构的 LRU 缓存中。缓存的 KV 值由前缀 Token 的滚动哈希(rolling hash)索引。对于每个新查询,为上下文的每个前缀计算滚动哈希,并检索最长匹配的缓存。这允许即使是部分匹配的消息也能重用缓存。
在集群级别,我们使用粘性会话将来自同一对话的查询路由到同一服务器。由于我们的 KV 缓存大小很小,每台服务器可以同时缓存数千个对话。我们的系统实现了 95% 的缓存命中率,进一步降低了推理成本。
量化用于训练和服务
我们对模型的权重、激活和注意力键和值(KV,Key-Value)缓存使用了 int8 量化(int8 quantization)。为此,我们实现了定制的 int8 内核用于矩阵乘法和注意力。不同于通常采用的“训练后量化(post-training quantization)”技术,我们直接在 int8 精度下训练我们的模型,消除了训练和服务不匹配的风险,同时显著提高了训练效率。量化训练本身是一个复杂的话题,我们将在后续文章中详细讨论。
共建未来
高效推理对于扩展 AI 系统并将其无缝集成到我们的日常生活中至关重要。综上所述,以上讨论的创新实现了前所未有的效率,并将推理成本降低到使大规模服务大语言模型(LLMs)变得更加容易的水平。与我们在 2022 年末刚开始时相比,我们的服务成本减少了 33 倍。今天,如果我们使用领先的商业 API 来服务我们的流量,成本将至少比我们自己的系统高出 13.5 倍。
然而,这仅仅是个开始。在 Character.AI,我们很高兴能继续打造一个由大语言模型(LLMs)驱动创新并提升全球每个人体验的未来。加入我们 (Join us),踏上这段令人兴奋的旅程,继续推动 AI 可能性的极限。一起创造一个高效且可扩展的 AI 系统处于每次互动核心的未来。