利用 ChatGPT 在技术面试中作弊到底有多容易?我们做了个实验来探究 [译]
Michael Mroczka
ChatGPT 正在逐步改变我们熟悉的工作模式。无论是协助小企业处理行政工作,还是为网页开发者编写 React(React)组件,它的实用性不言而喻。
在 interviewing.io,我们对 ChatGPT 如何改变技术面试的方式进行了深入思考。一个关键问题是:ChatGPT 会不会让面试作弊变得更加容易? 想要了解答案,不妨看看这段 45 秒的视频。视频里,一位工程师利用 ChatGPT 精准回答了面试官的问题。
这种作弊软件的初始反响与人们普遍预期的相符:
- Reddit 上的用户称“ChatGPT 标志着编程时代的结束。”
- YouTube 上的用户宣称“软件工程已经结束了,ChatGPT 是终结者。”
- X(原 Twitter)在讨论“ChatGPT 是否将终结编程面试?”
很明显,ChatGPT 能在面试中提供帮助,但我们想深入了解:
- 它能提供多少帮助?
- 作弊并顺利通过面试真的那么容易吗?
- 面试中经常出现的 LeetCode(LeetCode)问题,是否需要企业对其面试流程做出重大调整?
为了找到答案,我们邀请了一些专业面试官和用户参与了一场作弊实验!接下来,我们将分享我们的发现,并解释这对你意味着什么。先给你透露一点:企业需要立即改变他们的面试问题类型。
实验
interviewing.io 是一个供工程师进行面试练习和招聘的平台。工程师通过我们的平台进行模拟面试,而公司则通过我们挑选顶尖人才。我们拥有成千上万的专业面试官,以及数十万工程师使用我们的平台来为面试做准备。1
面试官
我们的面试官来自专业团队,分为三组,每组根据不同的题型进行提问。他们并不知道这个实验和 ChatGPT 或作弊有关。我们向他们解释,这项研究的目的是“探究面试官在提出标准问题与非标准问题时,其决策趋势的可预测性。”
以下是三类面试问题:
-
原版 LeetCode 问题:直接从 LeetCode 选择的问题,由面试官自行决定,且不对问题内容进行任何更改。
例如:按原文提出的 Sort Colors LeetCode 问题。 -
改编版 LeetCode 问题:从 LeetCode 选取的问题,经过修改,虽然与原题相似,但有明显区别。
例如:改编的 Sort Colors 问题,输入部分由原来的三个整数(0,1,2)改为四个整数(0,1,2,3)。 -
原创问题:这类问题不与网络上现有的任何问题直接相关。
例如:给定一个以下格式的日志文件:-<用户名>: <文本> - <贡献分数>- 你需要找出对话中参与度中等的用户。仅考虑贡献分数超过 50% 的用户。假设这类用户数目为奇数,任务是找出他们的贡献分数排名中间的用户。根据给出的文件,正确答案是 SyntaxSorcerer。
LOG FILE STARTNullPointerNinja: "who's going to the event tomorrow night?" - 100%LambdaLancer: "wat?" - 5%NullPointerNinja: "the event which is on 123 avenue!" - 100%SyntaxSorcerer: "I'm coming! I'll bring chips!" - 80%SyntaxSorcerer: "and something to drink!" - 80%LambdaLancer: "I can't make it" - 25%LambdaLancer: "🙁" - 25%LambdaLancer: "I really wanted to come too!" - 25%BitwiseBard: "I'll be there!" - 25%CodeMystic: "me too and I'll brink some dip" - 75%LOG FILE END
要了解更多关于这些问题类型和我们设计实验的细节,请参阅我们提供给参与面试官的 面试官实验指南 文档。
受访者简介
我们的受访者来自于活跃用户群体,他们应邀参加了一项简短的调查。我们挑选的受访者具备以下条件:
- 正在目前的市场中积极寻求工作机会
- 拥有超过 4 年的工作经验,并申请高级职位
- 对于编程时使用“ChatGPT”的熟悉程度评估为中等至高
- 自认为能够在面试中巧妙作弊且不易被察觉
通过这样的筛选,我们主要关注那些有可能在面试中作弊、有这方面动机且对 ChatGPT 和编码面试较为熟悉的人群。
我们明确告诉受访者,在面试中必须使用 ChatGPT,并以此来测试他们利用 ChatGPT 作弊的能力。 同时,我们也强调他们不应依靠自身技能通过面试,而是主要依赖 ChatGPT。
总计,我们进行了 37 场面试,其中有效的有 32 场(有 5 场因参与者未按要求执行而被排除):
- 11 场采用了“原版 LeetCode”的方式
- 9 场进行了适当的“改编版 LeetCode”
- 12 场实施了“原创面试题”
需要声明的是,由于我们的平台支持匿名性,因此面试仅包含音频而无视频。我们采用匿名方式是为了给用户创造一个无压力的学习环境,让他们可以在不受评判的情况下从失败中迅速学习。这固然对用户有益,但我们也认识到,实验中缺乏视频使得面试的真实性降低。在现实中的面试,你将面对镜头,且岗位岌岌可危,这会增加作弊的难度——但并非完全杜绝(如果你有不同看法,可以看看上面提到的 TikTok!)。
面试结束后,面试官和受访者均需填写一份结束后的调查问卷。我们询问受访者在面试中使用 ChatGPT 遇到的困难,并多次征询面试官对面试的看法,以了解有多少面试官会标记面试存在问题,并报告他们察觉到作弊行为。
面试结束后受访者的调查问卷
面试结束后面试官的调查问卷
对于这次实验的结果,我们并没有预设期望。但如果有一半的作弊者成功通过面试,那将对我们整个行业提供深刻的启示。
结果
在排除了那些未按指示行事的参与者的访谈后2,我们得到了以下发现。作为对照,我们参考了候选人在研究之外的 interviewing.io 模拟面试中的表现,即 53% 的成功率3。值得注意的是,我们平台上的大部分模拟面试都是 LeetCode 风格的题目,这很符合现实,因为这正是诸如 FAANG 这样的公司常常提出的问题类型。我们稍后将再次提及这一点。

相较于我们平台的平均水平和“原创”问题,“原版”LeetCode 问题的成功率明显更高。而“原版”和“改编”问题之间的成功率差异并不显著。与其他组别相比,“原创”问题的成功率明显偏低。
“原版 LeetCode”问题
不出所料,“原版 LeetCode”组的表现最为出色,有 73% 的面试被成功通过。面试者反馈,他们从 ChatGPT 获得了完美的解决方案。
对于这一组别,面试后调查中最引人注目的评论如下——我们认为这充分揭示了许多面试官的心态:
“要判断候选人是否因为真正擅长而轻松应对问题,还是因为之前遇到过这个问题,这是一个难题。通常,我会在问题中加入一两个特别的变化,以此来分辨两者的差异。”
一般情况下,这位面试官会用一个稍加改动的问题来深入挖掘,以获得更多信息。接下来,我们来看看“改编”问题组,探究面试官在问题中加入变化后是否确实能够获取更多有效信息。
“改编版 LeetCode”问题
需要注意的是,这一组面试者可能遇到了 LeetCode 上的标准问题,但这些问题经过了特殊修改,使其在网络上难以找到直接答案。这就意味着,ChatGPT 无法直接提供这些问题的答案。因此,面试者在这种情况下更多地依赖于 ChatGPT 真正的问题解决能力,而非单纯重复 LeetCode 上的教程内容。
正如我们所预期的,这一组的面试结果与“原版 LeetCode”组相差不大,67% 的候选人顺利通过了面试。实际上,两组之间的差异在统计上并不显著,也就是说,“改编版 LeetCode”问题与“原版 LeetCode”问题在实质上是相同的。这表明 ChatGPT 能够轻松应对对问题的轻微改动。不过,面试者们确实注意到,要想让 ChatGPT 解决这些修改过的问题,需要提供更多的引导。正如一位面试者所描述:
“直接从 LeetCode 上摘取的问题对 ChatGPT 来说毫无难度。但是稍微变化一下的后续问题,要让 ChatGPT 作出回答就显得更为困难。”
“原创”问题
正如预期,提出“原创”问题的面试组通过率最低,仅有 25% 的候选人通过了面试。这个比率不仅显著低于其他两个组,甚至比对照组(即那些没有作弊、面对 LeetCode 风格问题的候选人)的表现还要差!当候选人面对完全原创的问题时,他们的表现甚至不如他们在不作弊的情况下。
值得注意的是,这一数字在最初的计算中略高一些,但在我们详细回顾了原创问题后,我们发现了一个之前未曾预料到的问题类型,这微妙地导致了更高的通过率。为了了解这个问题的具体内容,请阅读下面标题为“面试官们:立即改变你们所提的问题!”的部分。
没有面试官发现有作弊行为!
在我们的实验中,面试官并不知情:被面试者其实被暗中要求作弊。回想一下,每次面试结束后,我们都会让面试官填写一份问卷,询问他们对候选人评估的信心有多强。
结果显示,面试官对自己的评估非常自信,有 72% 的面试官对他们的招聘决定持肯定态度。 其中一位面试官对某位面试者的表现印象深刻,甚至建议邀请这位面试者成为平台的面试官!
“这位候选人表现出色,对亚马逊 L6(相当于谷歌 L5)级别的软件工程师知识有深刻理解……甚至可以考虑让他/她成为 interviewing.io 的面试官或导师。”
仅凭一次面试就给出这么高评价,似乎有些过头了!
我们早就了解到,工程师很难准确评估自己的表现,因此,面试官同样高估了他们提出问题的有效性,这并不令人意外。
在那 28% 对自己招聘决策不自信的面试官中,我们询问了他们的原因。他们的答案分布如下:
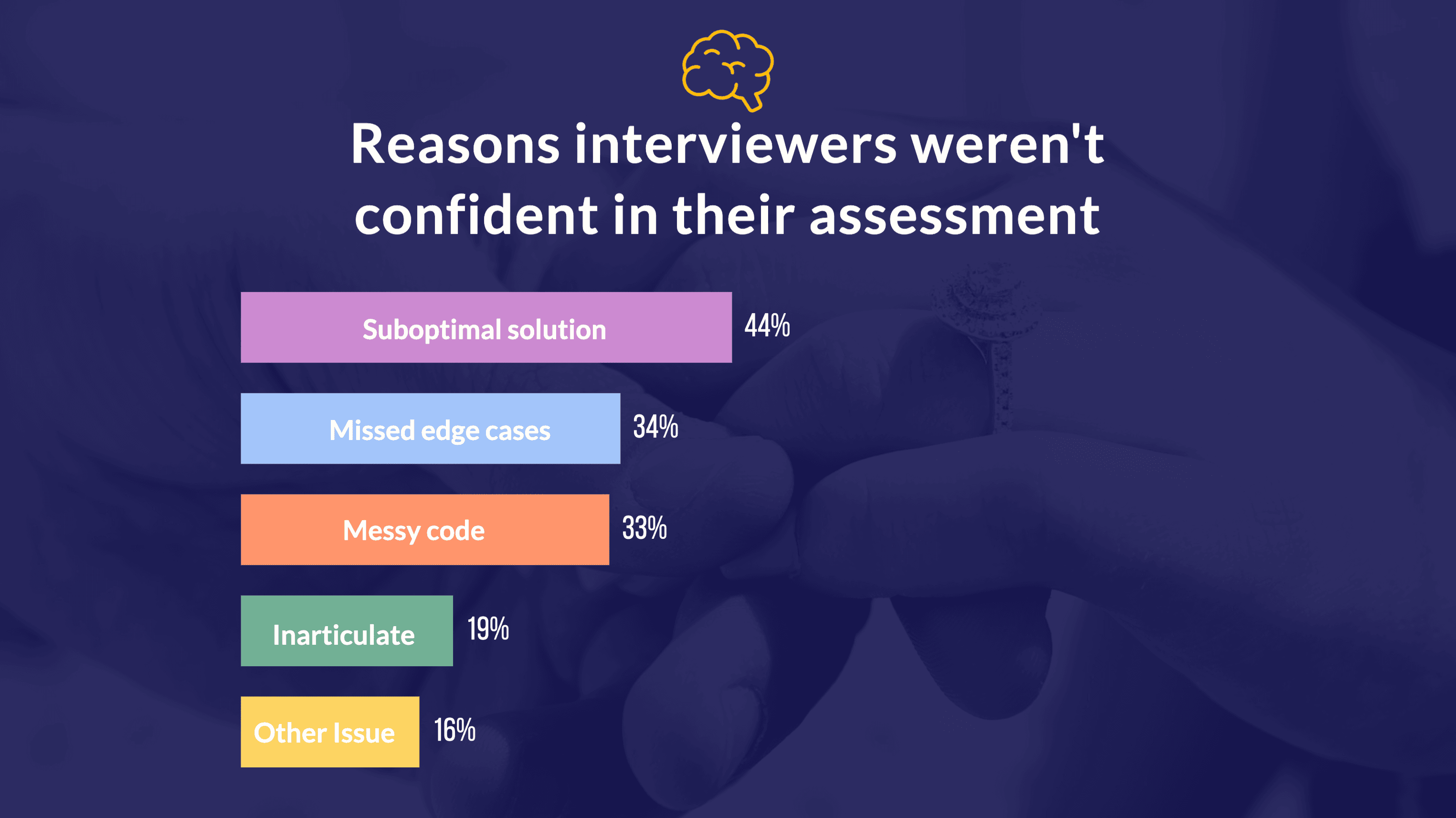
注意,他们并未提及作弊问题!
多数对招聘决策存疑的面试官明确指出了他们的不确定因素,主要涉及次优解、忽略边缘情况、代码混乱或沟通不畅等。我们特别设置了“其他问题”类别,想看看是否有面试官会因怀疑应聘者作弊而表示担忧。但深入了解后,我们发现的仅是一些小问题,比如“个性不合”或“编码速度需加快”。
面试官不仅有机会指出作弊行为,在面试过程中还被额外提示了三次,注意观察并报告任何其他担忧,包括自由回答的文本框和几个多选题,用来阐述他们的顾虑。
当面试者因不理解 ChatGPT 的回应而表现不佳时,面试官通常将其归因于缺乏练习,而非作弊。例如,有面试官认为候选人的问题解决能力尚可,但指出他们的思考和边缘情况处理需要更细致。
“候选人似乎没准备好应对任何 LeetCode 题目。”
“候选人的解题方法不够清晰,他们过早进入编码阶段。”
“候选人连最基础的 LeetCode 编程题都没准备好应对。”
“候选人在整体解决问题能力上表现不错,但在编程速度和识别关键边界情况方面还需提速。”
那么,是谁报告了对作弊的担忧?又是谁真的被发现了呢?
结果出人意料:没有任何一个面试官提到对候选人作弊的担忧!
我们惊讶地发现,面试官们并未报告任何对作弊的怀疑。而且,面试者们普遍自信他们的作弊行为没有被发觉。有 81% 的面试者表示他们不担心被发现,13% 的人认为可能已经引起了面试官的怀疑,但仅有 6% 的参与者觉得面试官对他们作弊有所怀疑。
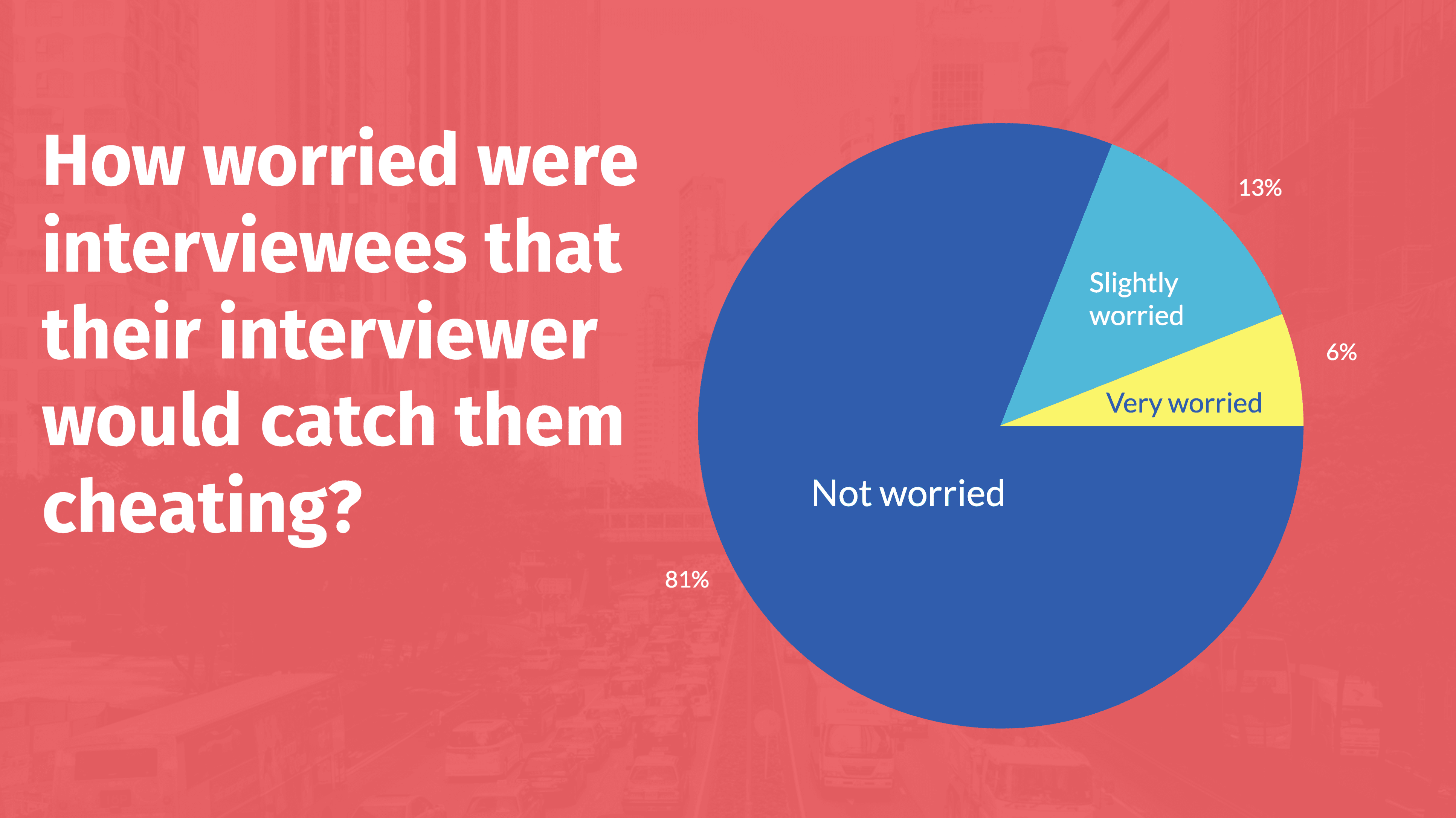
大部分面试者确信他们的作弊行为未被察觉
那些担心被发现的候选人在面试后的调查分析中确实收到了一些面试官的不同寻常的评价,但他们并未被直接怀疑作弊。总的来说,大多数候选人认为自己成功地掩饰了作弊行为 —— 而事实也确实如此!
公司:立刻改变你们的提问方式!
这些结果明显地指出,公司必须立即开始提出量身定做的问题,否则将面临候选人在面试中作弊的高风险(最终导致无法从面试中获取有效信息)!
ChatGPT 已经让照搬照抄的问题变得过时;依赖这些问题的人将不自觉地将他们的招聘过程交给偶然。在本就复杂的招聘过程中再加上作弊的担忧,无疑是雪上加霜。如果你所在的公司还在使用现成的 LeetCode 问题,请内部分享这篇文章!
采用定制问题不仅能防止作弊。它还能筛选出那些仅仅背诵了大量 LeetCode 答案的候选人(正如你所见,我们的定制问题的通过率显著低于控制组)。此外,它也能显著提升候选人的面试体验,从而使他们更愿意加入你的团队。我们之前曾进行过一个分析,探讨什么让优秀的面试官突出。不出所料,提问的质量是成功的关键之一,我们评分最高的面试官通常都是那些喜欢提出定制问题的人!在我们的研究中,问题的质量对于候选人是否愿意继续与公司合作至关重要。这比公司的品牌影响力更重要,品牌力虽然有助于吸引候选人,但一旦进入面试流程,问题质量的重要性就远超品牌力。
正如我们的面试者所说:
“总是能遇到不仅仅是纯算法的问题,感觉很棒。”
“我喜欢这个问题——它将一个相对简单的算法问题(构建和遍历树)增添了更多深度。我还很欣赏面试官将问题与[Redacted]的实际产品联系起来,这让它看起来不再是个玩具问题,而是更像一个实际问题的简化版。”
“这是我在这个平台上遇到的最棒的问题之一。它是少数几个看似能应用于真实场景且基于真实(或潜在真实)商业挑战的问题之一。它还巧妙地结合了复杂性、效率和阻碍等挑战。”
对于决定转向更多定制问题的公司,这里有一个细微但重要的建议。你可能会想直接拿现成的 LeetCode 问题,稍微改动一下措辞或外在形式。这看起来是个简便方法,因为显然比从头开始设计问题要容易。但遗憾的是,这样做并不有效。
正如我们之前所说,在这次实验中,我们发现并不是所有看似定制的问题都真的是定制的。有些问题看上去很特别,实际上却与 LeetCode 上的某个现有问题如出一辙。要想在面试中提出真正有挑战性的问题,仅仅对已有问题稍作改动是不够的。 你需要设计出既有独特输入又有独特输出的问题,这样才能有效地防止 ChatGPT 识别出来!
面试官提出的问题都是保密的,所以我们不能公开实验中具体使用的问题。但是,我们可以给你举一个例子来说明问题所在。以下是一个表面上看似定制,实际上却很容易被 ChatGPT 破解的问题:
For her birthday, Mia received a mysterious box containing numbered cardsand a note saying, "Combine two cards that add up to 18 to unlock your gift!"Help Mia find the right pair of cards to reveal her surprise.Input: An array of integers (the numbers on the cards), and the target sum (18).arr = [1, 3, 5, 10, 8], target = 18Output: The indices of the two cards that add up to the target sum.In this case, [3, 4] because index 3 and 4 add to 18 (10+8).
你看出问题所在了吗?尽管这个问题一开始看起来像是特制的,但它的目标实际上和著名的 TwoSum 问题一模一样,即寻找两个数的和等于给定目标。输入和输出完全相同,这个问题唯一的“定制”之处仅在于添加的背景故事。
考虑到这个问题与众多已知问题一致,ChatGPT 能够轻松应对那些即使加了独特故事但输入和输出 与已知问题相同的问题,并不让人意外。所以,当面对这样既有独特故事又与已知问题在输入和输出上完全相同的问题时,ChatGPT 往往能够表现出色。
如何创造出真正优秀的原创问题
我们发现,一个极有效的方法是,与你的团队一起开启一个共享文档,每当有人解决了他们认为有趣的问题,无论多么微小,都在上面随手做个简单记录。这些笔记不必详尽,但它们可以成为你们独创面试问题的灵感源泉,让候选人对贵公司的日常有所了解。把这些零散的想法转变成面试问题需要深思熟虑和细致的努力——你需要精简掉很多细节,并将问题的核心简化成候选人不需花费太多工作/准备就能理解的形式。你可能还需要对这些自创问题进行几次修改,才能让它们完善——但这样做的收益是巨大的。
我们要明确一点,我们并不是反对在技术面试中使用数据结构与算法(DS&A)。DS&A 问题之所以名声不佳,是因为一些面试官表现不佳,以及公司懒惰地重复使用与工作无关的 LeetCode 问题,其中很多都是质量不高的。但在优秀面试官的引导下,这些问题非常有力且实用。如果你采用上面的方法,你就能够设计出既有实际应用基础,又能激发候选人兴趣的新颖数据结构与算法问题,让他们对你们的工作充满期待。
此外,这还将推动整个行业的发展。在今天的面试过程中,靠背诵大量 LeetCode 问题来获得优势是不可接受的,同样,面试环境变得如此艰难以至于作弊看似成了一个理性选择,这也是不应该的。解决之道在于雇主需要付出更多努力,来设计出更好的面试问题。让我们共同努力,改善这一现状。
求职者的真话
各位积极求职的朋友们,请留意!现在,有些求职者开始利用 ChatGPT 在面试中作弊了。特别是那些会问 LeetCode 编程题的公司(不幸地,这样的公司很多),使用 ChatGPT 的人可能暂时占到了一些便宜。
我们现在正处于一个转变期,很多公司的招聘流程还没能适应这一变化。但很快,他们要么彻底改变用法,不再直接出 LeetCode 那样的题目(这对整个行业都是好事),要么重新采用面对面的现场面试(这样作弊就几乎不可能了),或者两者都会发生。
面对已经很艰难的求职环境,现在还得担心其他候选人作弊,这的确很让人烦恼。但我们无法支持大家去作弊以求所谓的“公平竞争”。
事实上,那些试图在面试中利用 ChatGPT 的人发现,面试变得更加困难了,他们不得不在回答问题的同时还要应对 AI。
举个例子,有位面试者在回答了一个完美的问题后,却在解释时间复杂性时支支吾吾。面试官对此感到困惑,因为那位面试者在努力解释他们是如何得出那个错误的时间复杂性的(其实是 ChatGPT 偷偷告诉他的)。
虽然在这项研究中没有人被发现作弊(他们都关闭了摄像头),但对许多技术熟练的候选人来说,作弊仍然是个挑战,这一点从视频中可以看出。
抛开伦理不谈,作弊本身就是个难题,既压力山大又不容易实施。相比之下,我们建议大家把精力投入到实际的练习中,这对你在公司改变招聘流程后的表现会更有帮助。我们希望,ChatGPT 的出现能成为推动行业面试标准转变的催化剂,从刷题和背诵转向真正的工程能力测试。

Michael Mroczka
Michael Mroczka,前谷歌软件工程师,是 interviewing.io 中最受欢迎的导师之一,专注于提供个性化辅导。他有十年的辅导经验,亲自帮助了超过 100 名工程师加入谷歌等顶尖科技公司。他曾在职业生涯初期获得多家科技公司的聘请,现在热衷于分享他的技术面试技巧。
他还为 interviewing.io 撰写技术文章(包括这篇),并是《高级工程师系统设计面试指南》(A Senior Engineer's Guide to the System Design Interview) 的合著者之一。
我们特别感谢 Dwight Gunning 和 Liz Graves 在这次实验中的帮助。当然,还要向所有参与本次采访的面试官和应试者表示衷心的感谢!
脚注
-
要在我们平台担任面试官,必须具备至少 4 年的面试经验,并且曾代表 FAANG 或与 FAANG 类似的公司进行过至少 20 次面试。 ↩
-
我们不得不排除了五次面试,因为它们并未有效利用 ChatGPT。其中在两次面试中,面试者对问题已经熟悉,选择了自行解决;另一次面试中,面试者选择独自尝试问题,没有使用 ChatGPT,这违背了我们的指导。最后两次则是使用了一些特殊的面试题,这些题目存在一些具体问题,我们将在文章后面进行说明。 ↩
-
这个通过率高于实际情况。我们认为这主要由两个因素造成:一是自我选择的用户群体,这些积极准备面试的用户具有某种程度的特异性;二是很多用户在与人面对面练习前,会先自行进行练习。 ↩