大语言模型抽象简明指南 [译]

本文作者绘制了一幅涵盖大语言模型(LLMs)及其交互方式抽象框架的图谱,并提出了两种思路体系,帮助理解和分类大语言模型抽象的多种方法与理念。
引言
大语言模型(LLMs)及其它语言模型(LMs)引入了一种新的编程方式。在这种方式中,“指令”不再是单一明确的 API,而变成了类似英语这样的自然语言表述。在这个新兴领域,被称为“提示工程”的专家们,通过巧妙组合关键词、提示格式以及认知模型来编程他们的 LMs,或诱导出它们特定的行为。
过去两年的实践显示,LMs 能够在许多领域带来颠覆性的变革,但它们在无缝融入更大的程序环境时也存在一些局限。这些限制包括对事实和先前交互的不完美记忆、无法可靠遵循逻辑结构、无法与外部环境互动或执行计算任务,以及对提示方式的敏感性。为了克服这些局限,出现了十几种不同的流行框架,它们各自偏好不同的抽象交互方式和 LMs 之间的相互作用。
本文是迄今为止对这些框架最全面的综述,其分类方式比现有讨论更为系统。除了为读者提供一个关于如何抽象化地与 LLMs 交互的框架图谱外,本文还提供了两种组织思路体系,用于探究和理解抽象方法和理念的多样性:
- 语言模型系统接口模型(LMSI),这是一个受到计算机系统和网络中 OSI 模型启发而形成的新型七层抽象体系。它用于分类和层次化近几个月出现的编程和交互框架。这些层次从最高级的抽象层逐渐过渡到整个 LM 抽象堆栈中的最基础层。
- 我们确定的五种 LM 抽象家族 分类,这些家族在我们的审查中显示出执行相似功能的趋势。这些分类大致按照从高层到低层的抽象顺序排列,分组了大致处于相同层次的库。
这两种组织思路体系——语言模型系统接口模型(LMSI)和 LM 抽象家族分类——通过它们对抽象层次的处理方式相互关联。LM 抽象家族的排序大致与 LMSI 模型的抽象层次相对应,尤其是在描述暴露给用户或开发者的细节层面上。例如,在光谱的一端,较低层次的抽象涉及通过 Python 函数直接与 LLM 的参数互动(如在 LMSI 的 神经网络层)。而在另一端,更高层次的抽象则提供了用于生成和优化提示的工具,使得用户可以在不深入理解 LLM 或其底层管道的技术复杂性的情况下,对 LLM 的响应进行递归式的精细调整(如在 LMSI 的 优化层 或 应用层)。
本文的剩余部分可以整体阅读,也可以分段阅读。在第一部分,我们将介绍 LMSI,定义其各层,并尝试展示我们审查的每个 LM 框架如何横跨 LMSI 的不同层次,接着详细描述每个框架。在第二部分,我们将介绍 LM 抽象的五个家族,每个类别大致代表了一种向用户或开发者提供 LM 抽象的方法。我们将深入介绍每个类别所涵盖的内容,并在这部分中详细描述我们审查的大部分框架,包括展示如何使用和与这五个类别中的许多框架互动的代码示例。
LMSI(语言模型系统接口模型)
在研究各种语言模型框架时,我们发现了一个趋势:这些框架可以大致被归类为高级、低级或混合级别的抽象。但在这个背景下,“高级”或“低级”的具体含义一直不够明确,直到我们进一步加以整理。
受计算机系统和网络中的 OSI 模型 启发,我们提出了一个概念:不同的功能层次。这些框架可以关注这些层次,并且重要的是,可以从高到低层次在语言模型库和框架中进行有序组织。总体而言,我们确定了七个操作层次,语言模型框架通常在这些层次上运作并向用户展示。从与语言模型的架构、权重和参数直接互动的最低层次,即“神经网络层”,到最高层次,也就是把启用语言模型的应用程序当作一个黑盒来执行高级用户任务的“用户层”。
我们认为,这些层次不仅有助于组织和分类现有的大型语言模型 (LLM) 抽象框架,还能帮助识别不同的重点和特性在大型语言模型框架中是如何相互独立的。就像 OSI 模型一样,我们希望这种分层能为框架开发者提供清晰的指导,帮助他们在适当的层次上设计自己的抽象概念,从而可能利用其他框架中已经实现的基础设施。这有效地分离了各个关注点,并允许框架将专业知识转移到抽象边界/接口的其他框架上。然而,目前许多框架都集中在特定的层次,有些则覆盖了更广泛的范围,这通常反映了一个宽泛的设计思路,高级抽象可以与低级特性互动,并向开发者展示这种互动。
下面的列表详细描述了每个层次,而表 1 则展示了最近框架对特定层次的重视程度,以星号表示。
- 神经网络层 — 直接操作和访问语言模型的架构、权重和解码组件。
- 提示层 — 通过 API、手动聊天或其他界面输入文本到语言模型,这个过程可能对文本输入或输出没有限制。
- 提示约束层 — 对不同类型或组别的提示施加规则或结构(比如通过模板),或对输出进行约束和验证。
- 控制层 — 在框架中支持条件控制、循环、分派等控制流功能。
- 优化层 — 基于特定指标优化语言模型或语言模型系统的某些方面。
- 应用层 — 在更低层次上构建的库、工具和应用程序代码,提供一些可配置的通用解决方案。
- 用户层 — 人机交互层,应用程序直接响应人类指令,执行由语言模型驱动的任务。
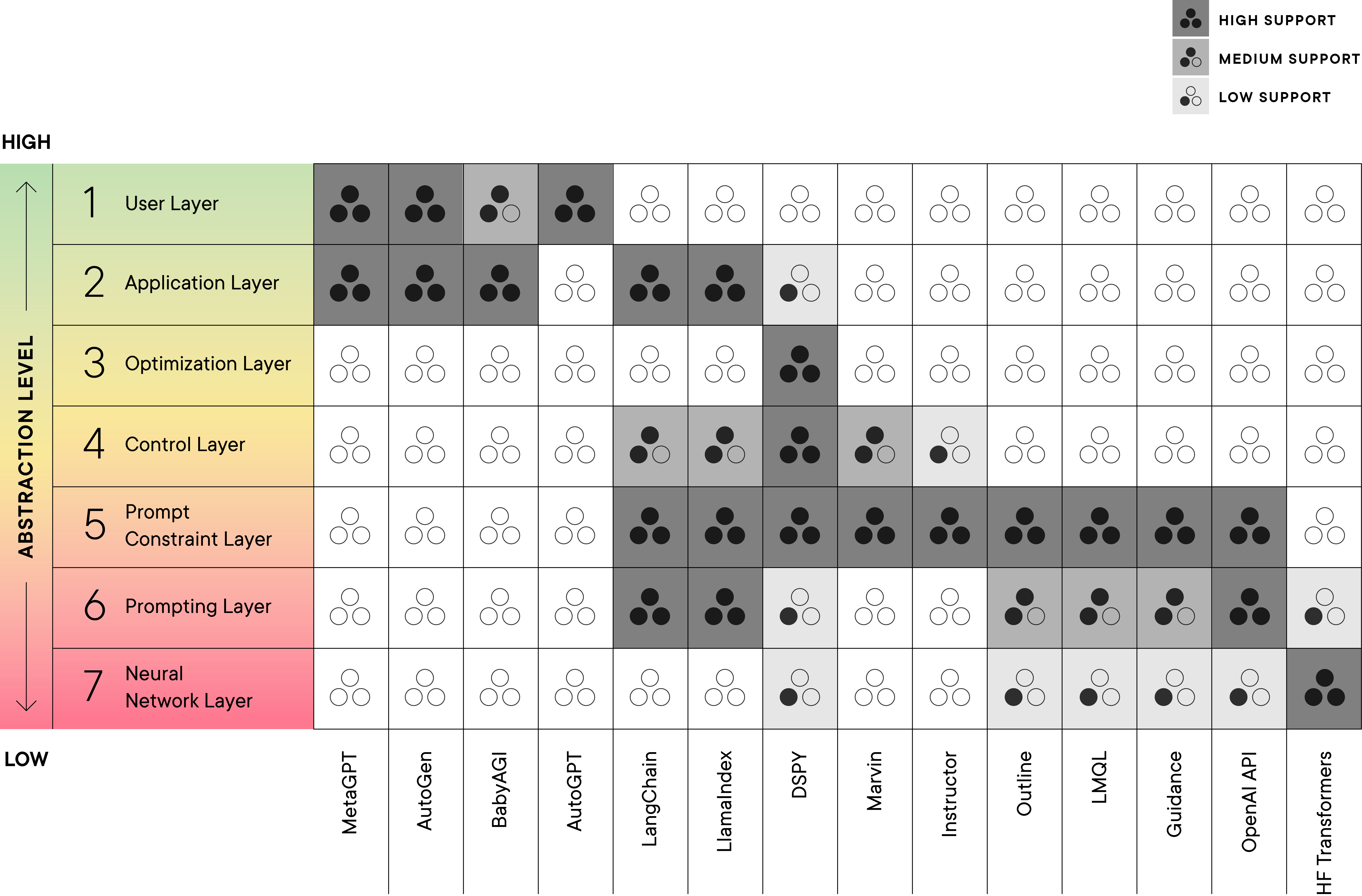
表 1 (点击展开。)
大语言模型框架的五大类别
在我们的评估中,我们发现了一些执行相似功能的库类别。与其单独按抽象顺序描述每个框架,我们更倾向于将它们分类,这些类别大致对应于同一种 LMSI 架构层次,并按照逐渐增加的抽象顺序进行呈现。
第一个框架类别专注于受控生成(例如 Guidance 和 LMQL)。这些框架允许用户设定格式要求和大语言模型输出的其他限制(如通过正则表达式),这对于构建围绕大语言模型的可靠系统至关重要。在此基础上,基于模式的生成框架(如 OpenAI 的函数调用模式和 Marvin)让用户可以定义类型级的输出结构(例如,使用 Pydantic 架构)。利用架构和自然语言“签名”的强大抽象概念,由 DSPy 领衔的框架专注于大语言模型程序的编译,围绕将程序(其中大语言模型调用是一种基本元素)编译成自动生成的、高质量的提示链。这种编译驱动策略不同于预封装模块的提示工程工具(如 LangChain 和 LlamaIndex),这些工具集成了一系列生成和解析提示的工具,以及一些基本的原语,用于将生成的回应与其他大语言模型调用或环境调用相连接,实现与大语言模型的更深入交互。然而,这些工具的核心仍然基于手动制定的提示工程技术。在最高层面上,我们探讨了最具雄心的开放式智能体框架(如 AutoGPT 和 MetaGPT)和多智能体聊天范式(如 CAMEL 和 AutoGEN 所展示的)。
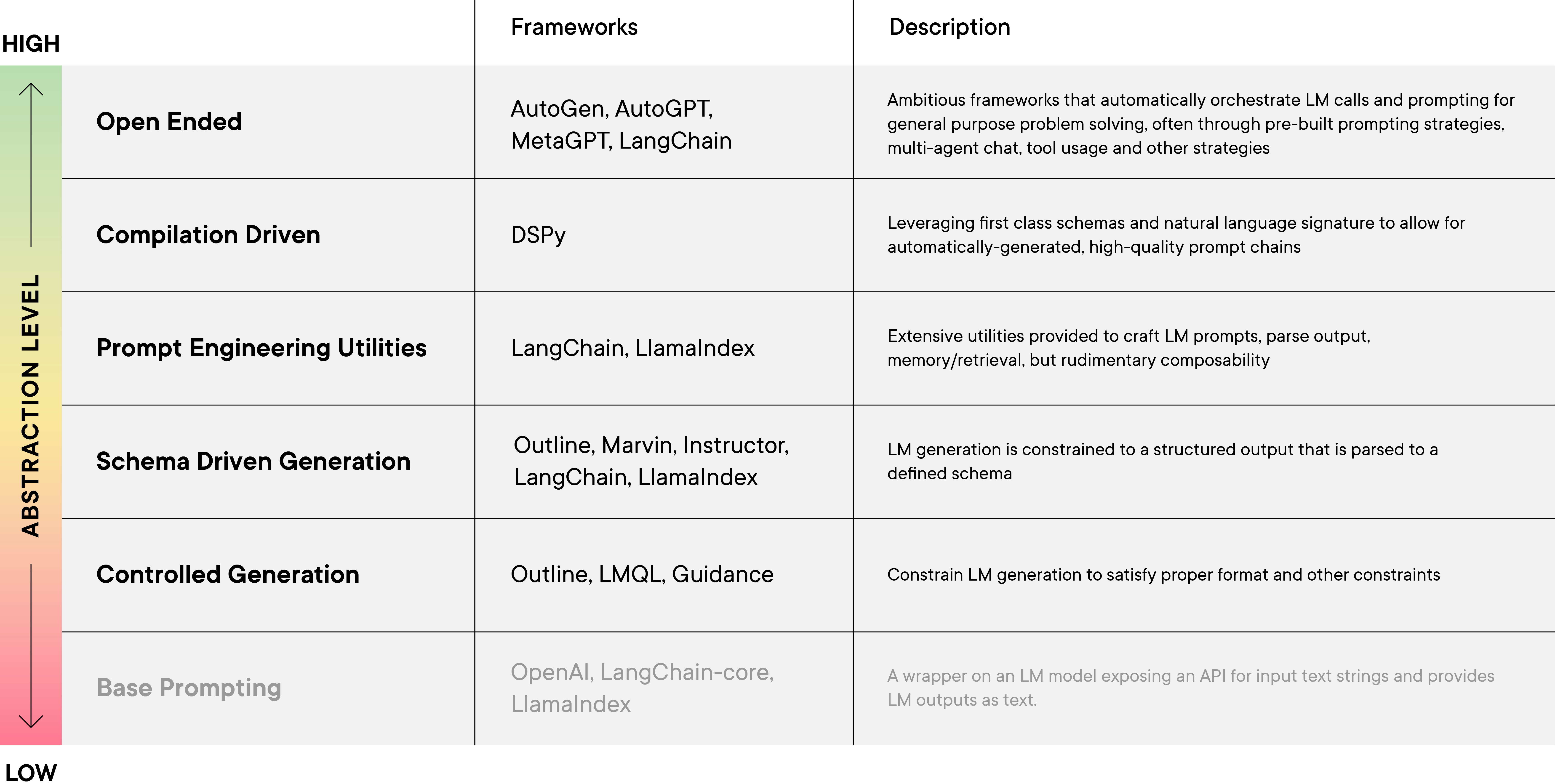
表 2(大语言模型框架的五大类别。注释:我们将最底层的“基础提示”以灰色显示,并不将其计入我们的分类,因为它仅是对大语言模型基本的文本输入/输出行为的简单封装,没有更进一步的抽象。点击放大。)
0) 基础提示
我们在是否将最基本的层次——基础提示——包含在我们的大语言模型框架分类中犹豫不决。基础提示是在大语言模型抽象框架出现之前的最先进水平。
基础提示实际上是指用户在没有任何额外框架的情况下,一直能够使用的大语言模型或 API。可以将其视为对不同大语言模型最基本接口(文本输入、文本输出)的简单包装。这是 OpenAI(及其他提供商)API 以及 LangChain-core 包中的一些主要抽象的核心。对于某些应用而言,这种最原始的形式已经足够灵活,能够创建手工制作的提示或构建更高级的抽象概念。
1) 受控生成
大语言模型 (LLMs) 以一种基于统计概率却不完全确定的方式来补全文本。这意味着大语言模型的回应可能不是固定不变的,这使得将它们融入其他工作流程变得有些复杂。为此,一些专门的库通过使用基于模板或限制的受控生成技术来解决这一问题,如 Outlines、Guidance 和 LMQL 所示。这些库使用模板引擎,其中的模板设计了带有“填空”部分的提示语,供大语言模型填充。这些大语言模型生成的内容能够绑定到模板的变量上,并被嵌入到后续的生成内容中,从而引导输出结果。这些库还支持对输出内容施加限制,如只包含特定子集、遵循特定架构或控制长度等。LMQL 利用大语言模型的解码部分来实现这种过滤机制,而 Outlines 则调整了大语言模型处理 Token 概率的能力,以支持输出限制。这些框架通常涵盖从神经网络层到提示约束层的范围。
@lmql.querydef meaning_of_life():'''lmql# top-level strings are prompts"Q: What is the answer to life, the \universe and everything?"# generation via (constrained) variables"A: [ANSWER]" where \len(ANSWER) < 120 and STOPS_AT(ANSWER, ".")# results are directly accessibleprint("LLM returned", ANSWER)# use typed variables for guaranteed# output format"The answer is [NUM: int]"# query programs are just functionsreturn NUM'''# so from Python, you can just do thismeaning_of_life() # 42
查看原始代码 lmql.py 由 GitHub 提供 ❤ 支持。
LMQL 程序采用一种特定领域的语言(DSL),这种语言是以 Python 为基础进行扩展的(请参见示例 1)。在这种语言中,顶层字符串可能包含用方括号表示的“空缺”,并可以附加类型注释。这些字符串被用于完成编程任务,而附加的约束则通过 where 语句来表示。LMQL 引入了一种积极且部分的评估方法,这种方法能够谨慎地预测特定生成操作是否能满足给定的约束条件。利用这种评估方法,LMQL 能够创建一个针对特定模型的 Token 掩码,这有助于在解码过程中优化搜索空间。
Outline 也有类似的功能,它能够利用正则表达式有效地引导文本生成,同时支持 LMQL 中的许多约束。在其内部,Outline 把神经文本生成过程视为有限状态机中状态的转换。它在模型的词汇库上建立索引,并通过调整模型在 Token 上的概率来确保生成文本的结构。此外,该库还包含许多其他功能,比如使用 Jinjia 模板语言进行提示生成,或利用 json 和 Pydantic 进行对象类型和架构的约束。
然而,在 LMQL 的情况下,像 GPT-3 和 GPT-4 这样的托管服务可能无法直接访问大语言模型的解码部分。此外,这些库中使用的某些“填空”策略可能更适合于那些专为文本补全设计的大语言模型,而不是像 GPT-4 这样的用于对话的模型。
2) 模式驱动生成
在控制性生成的方法中,一种更细致的抽象是模式驱动生成。在这个方法中,语言模型 (LM) 和它的编程环境界限被预设的模式或某种对象规范语言(通常是 JSON)所限制。这与引导和LMQL不同,后者要求用户明确指定 JSON 的结构及其内容限制以获得 JSON 输出。相较于传统的控制性生成,模式驱动的方式更容易融入现有的编程逻辑中。但是,对生成内容的控制可能相对有限。这类库属于“约束提示层”,因为遵循特定模式是限制语言模型输出的一种方式。
在 Outlines 的其他库中,如 Marvin 和 Instructor,以及最近的 LangChain 和 Llamaindex,这一步骤被进一步抽象化。用户可以使用数据验证库 Pydantic 来定义数据结构,作为特定语言模型的输出模式(这是一种“模型层抽象”)。这些库在内部将模式转化为自然语言指令,通过预设提示来引导语言模型按照正确的、可解析的格式输出。不过,对于 Marvin 和 Instructor 来说,它们还支持利用底层大语言模型提供商(如 OpenAI)的高级功能,比如通过函数调用来确保输出的可解析性。OpenAI 新推出的 JSON 模式也预计将被这些库采用,以降低输出不可解析的风险。
import instructorfrom openai import OpenAIfrom pydantic import BaseModel# This enables response_model keyword# from client.chat.completions.createclient = instructor.patch(OpenAI())class UserDetail(BaseModel):name: strage: intuser = client.chat.completions.create(model="gpt-3.5-turbo", response_model=UserDetail,messages=[{"role": "user", "content": "Extract Jason is 25 years old"}])assert isinstance(user, UserDetail)assert user.name == "Jason"assert user.age == 25
查看原始文件instructor.py 由 GitHub 爱心托管
例如,Instructor 就是一个替代的 OpenAI API 客户端,它接受使用 Pydantic定义的响应模型,如(示例 2)所示。它的实现支持三种查询语言模型的模式:json、函数调用和工具使用,每一种都对应 OpenAI 支持的 API。Instructor 内置了一些提示,用于指导语言模型理解模式和输出格式,从而辅助解析过程。
在 LangChain 中,则支持更复杂的重试解析器,以应对在验证过程中偶尔出现的错误。但这里的输出不是通过 OpenAI 的函数调用 API 实现的,而是通过更自然的语言指令来进行。
llm = OpenAI(temperature =0)class Action(BaseModel):action: str = Field(description="action to take")action_input: str = Field(description="input to the action")parser = PydanticOutputParser(pydantic_object=Action)# the parser provides natural language formatting instruction for use in LLM.# The process is centered around prompts.prompt = PromptTemplate(template="Answer the user query.\n{format_instructions}\n{query}\n",input_variables=["query"],partial_variables={"format_instructions": parser.get_format_instructions()})prompt_value = prompt.format_prompt(query="who is leo di caprios gf?")model_response = model(prompt_value.to_string())# the parsing aspect and the querying aspect is detached in LangChainparsed_model = parser.parse(model_response)# if the parsing process results in an exception, users could use the retry parser that internally appends the parsing error and prompts the LM to retry it againretry_parser = RetryWithErrorOutputParser.from_llm(parser=parser, llm=llm)retry_parser.parse_with_prompt(model_response, prompt_value)view raw
查看原始文件langchain.py 由 GitHub 爱心托管
在 (示例 3) 中,我们深入探讨了 LangChain 的解析和重试机制。这个例子突出展示了 LangChain 在字符串和提示操作方面的重点关注,并展现了他们提供的一些实用且灵活的工具。
在处理输出数据的结构之外,一些编程库还针对与大语言模型 (LLM) 的交互引入了功能性架构(也称为 功能级抽象)。它们允许程序员使用自然语言来标注函数的 架构 或 签名,从而表达函数的核心目的。这种做法最早出现在 2023 年初的 DSP 项目中,该项目是后来 DSPy 框架的前身。在 DSP 中,用户可以简单地定义函数输入和输出的类型(例如:“Question, Thoughts -> Answer”),这包括了对参数的人类易懂的描述和相关前缀。这些输入和输出类型的组合构成了一个 DSP 模板,可以用来生成一个可调用的 Python 函数。Marvin 近期通过其“AI Function”进一步简化了这种模式,程序员可以注明输入输出类型及函数说明,这些信息将用于根据运行时的输入生成提示,并从大语言模型中提取答案。
@ai_fndef generate_recipe(ingredients: list[str]) -> list[str]:"""From a list of `ingredients`, generates acomplete instruction set to cook a recipe."""generate_recipe(["lemon", "chicken", "olives", "coucous"])generate_recipe.prompt("I need a recipe using Lemon Chicken Olives and Coucous")
view rawmarvin.py 由 GitHub ❤ 托管
(示例 4) 介绍了 Marvin AI 的函数功能。在这个例子中,被标注的函数会在运行时被捕获,其 Python 类型签名、描述和输入都会被送入大语言模型来提取输出。类型提示在这里起到确保类型安全的校验作用。这种方法还允许以自然语言的方式调用函数。
在 DSPy 中,开发者也可以用类似的方式指定 自然语言签名,来声明性地定义大语言模型需要解决的特定(子)任务,这是根据对整体任务以及输入输出字段的描述而生成的。
class BasicQA(dspy.Signature):"""Answer questions with short factoid answers."""question = dspy.InputField()answer = dspy.OutputField(desc="often between 1 and 5 words")# Define the predictor.generate_answer = dspy.Predict(BasicQA)# Call the predictor on a particular input.pred = generate_answer(question=dev_example.question)# Or use the Short Handqa = dspy.Predict("question -> answer")qa(question="Where is Guaraní spoken?")
(示例 5) 展示了 DSPy 如何利用自然语言签名来创建遵循特定签名的由大语言模型驱动的函数。
3) 编译大语言模型程序
大语言模型的功能实现方案,在一个广阔的搜索空间中有多种可能,这取决于很多因素,比如提供的示例是少样本还是零样本,使用的提示策略是什么(比如“思维链”),是否引用了外部数据源(如 RAG),或者是采用了多步骤处理方法(例如“程序式思维”)。在 Marvin 中,这些方案通常是固定的,开发者只能使用内置的标准解决方案。然而,在 DSPy 中,情况就不同了。这里的自然语言签名与查询策略是分开的,这意味着用户要使用某个签名,就得声明一个带有这个签名的模块。此外,这些模块还可以选择性地添加一些示例(或“演示”)。DSPy 还提供了一些高级模块,如 ChainOfThought(思维链)、ProgramOfThought(程序式思维)、MultiChainComparison(多链对比)和 ReAct(反应),这些模块可以将各种提示或互动策略应用到任意 DSPy 签名上,而不需要手动设计提示语。
# Define the predictor. Notice we're just changing the class. The signature BasicQA is unchanged.generate_answer_with_chain_of_thought = dspy.ChainOfThought(BasicQA)# Call the predictor on the same input.pred = generate_answer_with_chain_of_thought(question=dev_example.question)# Print the input, the chain of thought, and the prediction.print(f"Question: {dev_example.question}")print(f"Thought: {pred.rationale.split('.', 1)[1].strip()}")print(f"Predicted Answer: {pred.answer}")
接着在(示例 5)之后,(示例 6)显示了,仅通过更换驱动签名的模块,就可以轻松改变提示策略。
DSPy 模块的组合使用方式,就像 PyTorch 那样,采用了“定义 - 执行”的接口,使得用户可以自由搭建任意的处理流程。DSPy 中的一个重要概念是能够“编译”一个处理流程,通过选择指令/提示、演示,甚至是微调等超参数来进行优化。这一优化过程是通过一种特殊的策略,称为“teleprompter”(电视提词器),来实现的。一个典型的例子是 BootstrapFewShot teleprompter,它从少量输入中引导出示例(注意这里并不严格要求有输出),并加入到模块的处理流程中。这种 teleprompter 会在输入上运行流程,并选择符合某些自定义启发式规则的演示来进行优化。
from dspy.teleprompt import BootstrapFewShotclass GenerateAnswer(dspy.Signature):"""Answer questions with short factoid answers."""context = dspy.InputField(desc="may contain relevant facts")question = dspy.InputField()answer = dspy.OutputField(desc="often between 1 and 5 words")class RAG(dspy.Module):def __init__(self, num_passages=3):super().__init__()self.retrieve = dspy.Retrieve(k=num_passages)self.generate_answer = dspy.ChainOfThought(GenerateAnswer)def forward(self, question):# DSPy Modules are define-by-run and can support arbitary code in its forward functioncontext = self.retrieve(question).passagesprediction = self.generate_answer(context=context, question=question)return dspy.Prediction(context=context, answer=prediction.answer)# Validation logic: check that the predicted answer is correct.# Also check that the retrieved context does actually contain that answer.def validate_context_and_answer(example, pred, trace=None):answer_EM = dspy.evaluate.answer_exact_match(example, pred)answer_PM = dspy.evaluate.answer_passage_match(example, pred)return answer_EM and answer_PM# Set up a basic teleprompter, which will compile our RAG program.teleprompter = BootstrapFewShot(metric=validate_context_and_answer)# Compile!compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
查看原始文件dspy-compile.py 由 GitHub 提供支持
(示例 7) 展示了 DSPy 编译流程的工作原理。在 DSPy 中,编译通常需要一个训练数据集(注意:测试数据集并非必需),一个验证指标(即 validate_context_and_answer 函数),以及一个提示工具,如本例中的 BootstrapFewShot。不同的提示工具提供不同的优化策略,以及在成本和质量上的不同平衡点。得益于 DSPy 的模块化设计,可以方便地替换不同的提示工具,而不需要大幅更改基础架构。
与其他技术相比,基于编译的系统有几个明显的优点,如能够在不修改底层签名的情况下更换不同的提示策略,并通过优化提升性能。然而,要充分利用编译的优势,需要处理相当复杂的基础架构,并且必须理解 DSPy 系统的底层原理。对于那些需要大量与大型语言模型环境互动的项目,或者不需要太多优化的简单项目来说,目前可能还难以采纳这一系统。
4) 智能提示工具
与 DSPy 不同,LangChain 和 LlamaIndex 等库采取了另一种方法。它们通过提供大量预制模块,为使用大型语言模型的程序提供了现成的解决方案。这些库通常具备丰富的功能,更依赖智能提示技术,并专注于几种特定的与大型语言模型的互动模式。例如,LangChain 包含了管理提示模板、输出解析、内存管理和模型集成等多种工具。
LangChain 还提供了一些预设的抽象工具,利用这些工具可进行更复杂的与大型语言模型和外部环境的互动。Agent 和 Chain 等抽象工具,是通过 LangChain 的特定领域语言:LangChain 表达式语言 (LCEL) 来定义的,这些工具增强了现有工具的功能和可重用性,使其能够解决更复杂的任务。一般来说,LCEL 允许用户定义一组工具或行动,让大型语言模型与外部环境互动,并通过预设的提示和输出解析器来协调这些行动,决定如何调用这些工具,并将智能体的结果传递到下一轮的智能体循环中。LangChain 提供了丰富的预设提示和输出解析器(例如 ReAct、Chain-of-Thoughts、self-ask 等),帮助开发者快速搭建适用于多种场景的复杂智能体系统。然而,LCEL 主要是对简单智能体循环的一种轻量级的语法增强,尽管这些组件是可定制的,但目前它们并未提供比原生实现更高级的功能,智能体循环的交互模式也相对固定。
# the prompt is pulled from the LangSmith Hub which hosts many different promptsprompt = hub.pull("hwchase17/self-ask-with-search")llm = OpenAI(temperature=0)# provide the LM with useful toolssearch = SerpAPIWrapper()tools = Tool( name="Intermediate Answer", func=search.run, description="useful for when you need to ask with search")]llm_with_stop = llm.bind(stop=["\nIntermediate answer:"])agent = ({"input": lambda x: x["input"],# Use some custom observation_prefix/llm_prefix for formatting"agent_scratchpad": lambda x: format_log_to_str( x["intermediate_steps"],observation_prefix="\nIntermediate answer: ",llm_prefix="",), }| prompt| llm_with_stop| SelfAskOutputParser())agent_executor.invoke({"input": "What is the hometown of the reigning men's U.S. Open champion?"})
这个例子展示了当实施 自问 (Self-Ask) 提示策略时,LCEL 是如何被应用的。示例中的 agent 变量展示了使用 LCEL 将提示的替换内容(即第一个元素)、提示本身、所用的大语言模型 (LM) 和输出解析器结合在一起的过程。这个提示(链接可见此处)中有多个演示案例,大语言模型在其中提出了一系列中间问题,并包含“input”和“agent_scratchpad”两个占位字段用于内容替换。输出解析器会分析生成的文本序列,寻找诸如“Follow up:”或“So the final answer is:”这样的关键词,并根据生成内容选择不同的 AgentActions,以决定是调用哪个工具或是否已经得出最终结果。在这个过程中,程序员需要控制每个循环中的提示替换,通过替换输入并使用 format_log_to_str 函数,根据中间步骤生成适当的文本,再将其加入到 scratchpad(即把工具返回的所有中间问题和答案加入到提示中)。在这种情况下,尽管提示、替换、大语言模型和输出解析器看似是独立的模块,各有其接口和职责,但 LangChain 的设计却让它们之间产生了许多相互依赖,有时这些依赖关系记录不完整(有所漏洞)。因此,当使用 LCEL 构建智能体时,可重用的组件可能受限于它们与其他组件的紧密依赖关系,这些依赖通常只用文本表达,没有用 Python 类型明确表示,这进一步增加了复杂性。
在 提示工程 (Prompt Engineering) 领域,LangChain 和 LlamaIndex 为文本提示工程的执行提供了增强功能。除了基于替换的方法外,LangChain 还支持一些 提示优化 (Prompt Optimization) 技术,这包括选择有效示例或调整各种“超参数”等。LangChain 还配备了示例选择器,它们利用相似性(可能源自向量数据库)或简单的度量,比如 n-gram 重叠,来筛选出可能提高整体性能的示例子集。不过,这一过程独立于大语言模型和提示策略本身之外。此外,示例选择器为了挑选出有益的示例子集,需要大量已完整标注的示例。
LangChain 作为一个以提示为核心的框架,还开发了一个托管提示的生态系统,即 LangSmith 平台。在这个平台上,用户可以托管并与他人共享提示。当这些提示与 LCEL 以及 LangChain 的 Agent 和 Chain 抽象结合使用时,可以通过重用提示来驱动有趣的大语言模型互动模式。
5) 开放式智能体与多智能体管道
在最后一节中,我们将开放式智能体和多智能体聊天一起分类,因为它们在智能体系统层面上运作,共享了一些框架特性。
i) 开放式智能体与自动化流程
LangChain 不仅提供了预制的实用工具集,还包括了可直接使用的智能体流程或“链条”。这些链条能够运行复杂的大语言模型查询,并采用多种提示策略。但是,与 AutoGPT 等其他框架相比,LangChain 缺少那些可以链接外部工具的预设流程。与之形成对比的是,AutoGPT 等框架更专注于创建几乎不需要人工干预就能解决任务的智能体系统。这些系统内置了一些常用工具(如计算器、网络访问功能、文件访问等),以及一系列固定的提示,这些提示引导大语言模型完成既定任务,并且包含了短期和长期记忆的模型。虽然这些工具可以针对特定需求进行定制,但它们并不支持轻松扩展或与其他程序的灵活集成。不过,这种开箱即用的方案也因其直接扩展了基础大语言模型,并整合了多种工具以高效完成任务而显得方便。
在这一领域,还有一个值得关注的工具是 MetaGPT。MetaGPT 的特点在于,它能够根据仅一行的需求输入,自动生成程序、研究文档等。在其内部,MetaGPT 为不同的大语言模型互动环境指定了多种角色,如软件工程师、项目经理、架构师和质量保证人员。这些角色都有各自固定的提示和内置功能,可以直接使用。MetaGPT 还内嵌了一套标准操作流程,用来模拟一个虚构公司的运作,以此来协调不同角色之间的合作。你还可以通过添加新角色和定义其提示、功能以及如何融入标准操作流程来扩展 MetaGPT。这有点类似于 AutoGPT 中的插件机制。
BabyAGI 同样致力于利用大语言模型自动完成一系列任务。它主要是通过可用的执行智能体来安排任务分解为子任务,以及规划子任务的完成方式。
ii) 多智能体聊天
AutoGen 和 MetaGPT 是两个领先的框架,它们主要用于处理多个角色和特性不同的智能体之间的聊天和通信。在 AutoGen 中,核心构成是包裹着大语言模型(LMs)的智能助理和 UserProxyAgents,后者可以执行代码或与人类互动,使智能体能够与外界环境进行交流。为了实现多智能体之间的互动,还可以使用 GroupChatManager 来管理它们之间的交流方式。因此,通过组合不同的智能体及其互动方式,这个库能够支持多样的对话模式。而 MetaGPT 则有所不同。表面上,它是一个自动执行 AI 任务的工具,但其核心则提供了一个多智能体的抽象层。从概念上讲,MetaGPT 包括一个标准操作流程(SOP)和多个角色(类似于 AutoGen 中的智能体)。这个 SOP 指导了不同角色如何相互协作,并分配具体的子任务。框架还提供了一个共享知识和上下文的全球环境,其中每个角色可以选择关注与其相关的知识部分。
结论
近月来,LLM 编程抽象领域有了显著进展,催生了许多流行的框架。我们提出了一个 7 层抽象模型来分类这些库,并概述了我们观察到的关注点的分离。接下来,我们从内在和外在特征的角度探讨了五大类框架。它们的内在特征包括易于扩展性、保证输出稳定性的功能,以及如何与其他库和框架互动。而外在特征则涉及社区和生态系统方面,如可复用的提示策略,或基于框架开发的用于更专业任务的库。为了全面展示这些最新框架,我们在表 3 中列出了它们的工具/库/生态系统、可靠性、性能、可移植性和可扩展性,并在图 2 中进一步解释了表中的一些术语。
我们希望本文能帮助开发者和框架设计师更清晰地了解现有工作。

表 3 (点击放大)
图 2 - 表 3 中提到的术语解析
实用工具、软件库及其生态
- 这个软件库提供了哪些实用工具或工具?是否有社区资源可供使用?
可靠性
- 该框架如何确保基于大语言模型 (LM) 驱动的程序结果更为可信?
性能
- 在成本、速度或生成内容的质量方面,这个框架的表现如何?
可移植性
- 把这个库集成到现有编程工作流程中有多容易?
可扩展性
- 扩展这个库的功能容易吗?
内置提示模板
- 提示模板,是框架中内置的用于完成特定任务的字符串模板,例如指示 LM 按照特定格式输出。
内置交互模式
- 如 RAG、ReAct、思维链等策略,已直接内嵌在框架中。内置交互模式是指预先定义好、随时可用的结构、功能或模板。
社区推动的提示与工具
- 存在一个由社区主导的积极行动,旨在将提示和工具集成进特定的框架中
重试机制
- 如果结果不满意,重新生成部分输出
验证机制
- 根据特定标准(通常是一个模式)来验证生成的输出是否符合要求
输出约束
- 基于特定标准限制输出,以避免产生任何格式错误或不理想的结果
模型层抽象
- 将 LM 的输出视为一种数据模型,该模型遵循某些预设的模式
函数级抽象化
- 将 LM 视为编程环境中的一种可调用功能,这个功能有明确定义的输入和输出参数