把大语言模型封装成桌面应用 [译]
2023 年 12 月 10 日 by Bruce MacDonald
最近,我一直忙于开发 Ollama,因此投入了大量时间研究如何在本地系统上运行大语言模型(大语言模型),并探索如何将它们封装进应用程序。一般而言,大部分桌面应用程序只要求用户输入 OpenAI API 密钥,或者从源代码编译 Python 项目即可集成大语言模型。尽管这些方法在理论上可行,但对于许多用户来说,它们的技术门槛仍然较高。我追求的是用户能够一键下载并立即运行的应用程序。
项目计划
这是我设定的初步目标:
- 一键式下载与启动。
- 无需额外依赖。
- 应用文件体积最小化。
- 设计简单的大语言模型版本控制与分发系统。
- 兼容所有主流操作系统。
- 利用本地运行的优势,如访问本地文件系统。
- 用户无需调整任何设置,大语言模型在他们的系统上即插即用。
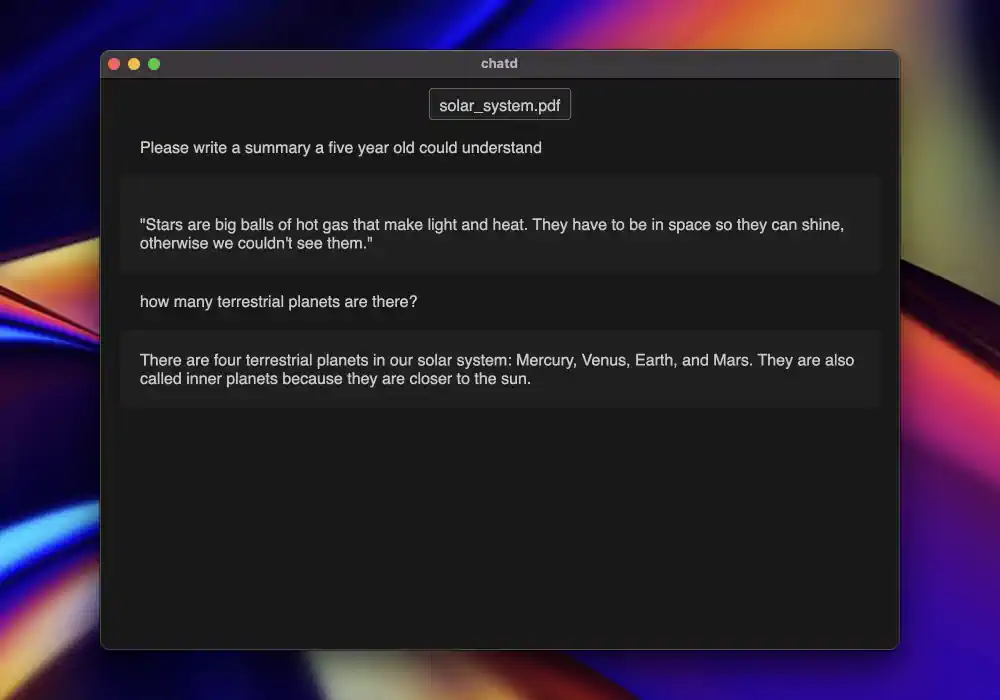
- 为高级用户提供更多选项,比如能够替换和定制应用中的大语言模型 。针对这些目标,我决定开发一个名为“chatd”的桌面应用,用户可以通过它与自己的文档进行交流。虽然这是一个常见的大语言模型应用场景,但目前还缺乏针对非技术型终端用户的简易选择。此外,该应用还可以便捷地访问文件系统。
为了保持项目的简洁性,我希望所有的代码都能整合在一个能够部署到任何操作系统上的应用中。这使得我只能在 Electron 和 Tauri 中二选一。基于对生态系统的熟悉度,我最终选择了 Electron。
架构
{kind=link}
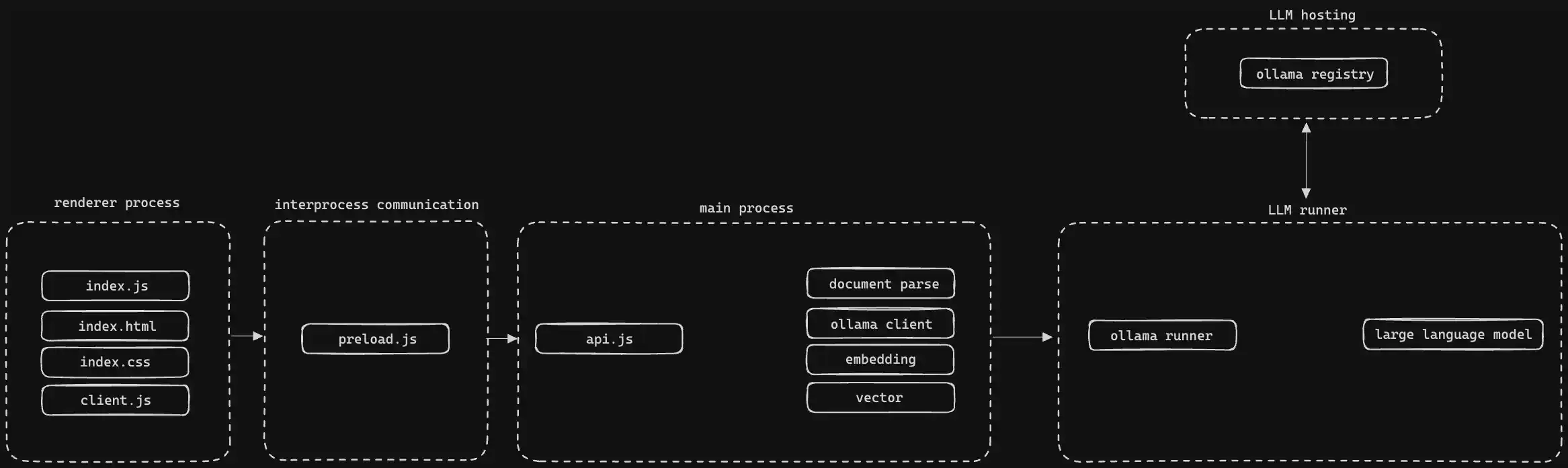
项目包括四个主要部分:渲染、进程间通信、主进程和大语言模型运行器。
渲染和进程间通信
应用的渲染部分使用了标准的 HTML、CSS 和 JavaScript。用户的操作需要处理时,数据会通过进程间通信发送到主进程,这允许执行可访问宿主系统的代码。
主进程
主进程主要处理文档(顺便说一句,希望有人能为通用文档处理开发一个标准的 JavaScript 库),然后将提取出的数据发送给 transformers.js。transformers.js 是 Hugging Face 维护的一个库,它可以让我们在浏览器中使用 ONNX 运行时来运行模型,速度非常快。由于我还没有找到合适的内存向量数据库,因此我选择将向量数据存储在内存中。
大语言模型运行器
在处理了所有这些信息之后,我选择使用 Ollama 来打包和分发应用中的大语言模型。目前,大多数用户将 Ollama 作为独立应用程序运行,并向其发送查询,但也可以直接将其整合到你的桌面应用中。我为每个操作系统的相应版本添加了 Ollama 可执行文件,并编写了一些 JavaScript 代码来管理这些可执行文件。
这种方式非常方便,因为我不仅可以借助 Ollama 作为一个可靠的大语言模型运行系统,还可以通过它来分发大语言模型,而无需将其包含在 Electron 应用包内。如果将大语言模型直接打包进 Electron 应用,将导致巨大的初始下载体积(超过 4GB),并限制用户只能使用我在 chatd 中内置的模型。此外,通过使用 Ollama 的分发系统,我可以在不发布新应用版本的情况下更新或修改模型。我只需对模型进行更改,将其推送到 ollama.ai 注册表,用户在下次启动应用时就会自动更新。
利用 Ollama 还使得用户体验保持简单,同时也为高级用户提供了更换应用程序中大语言模型的可能性。早期采用本地大语言模型的用户(以及我互动过的 Ollama 用户)对于如何运作非常感兴趣,并希望能够使用最新的模型保持领先。尽管 Ollama 被集成到了 chatd 中,但如果检测到 Ollama 已在运行,它会提供额外的设置选项,允许用户根据自己的需求配置 chatd 并更换模型。这也意味着,如果用户已经拥有了模型,就无需重复下载。
成果
我向一些不属于典型 ChatGPT 用户群体的朋友展示了 chatd,他们对此反应热烈。看到 AI 能在他们的电脑上本地运行,对他们来说简直是惊喜,他们很快意识到了赋予这个本地聊天机器人访问文件的巨大潜力。我期待着进一步优化这一体验,并希望我们能够见证桌面应用程序让大语言模型变得更加简单易用的新浪潮。
你可以在这里查看 chatd 项目:chatd.ai