现代大语言模型应用架构 [译]
本文将介绍构建您首个大语言模型应用所需了解的一切,以及您今天就能开始探索的潜在问题领域。
我们旨在帮助您实验大语言模型 (Large Language Model),打造个人应用程序,并挖掘未被充分利用的问题空间。因此,我们特邀了 GitHub 的资深机器学习研究员 Alireza Goudarzi 和首席机器学习工程师 Albert Ziegler,共同探讨当前大语言模型应用的最新架构。
本文将深入讲解如何构建您个人的大语言模型应用的五个关键步骤,当前大语言模型应用的新兴架构,以及您可以立即开始探索的问题领域。
构建大语言模型应用的五个关键步骤
在使用大语言模型(LLM)或任何机器学习(ML)模型构建软件时,与传统软件开发有本质的不同。开发者不再仅仅是将源代码编译成二进制来运行命令,而是需要深入理解数据集、嵌入和参数权重,以产生一致且准确的输出。重要的是要认识到,LLM 的输出结果是基于概率的,并不像传统编程那样可预测。
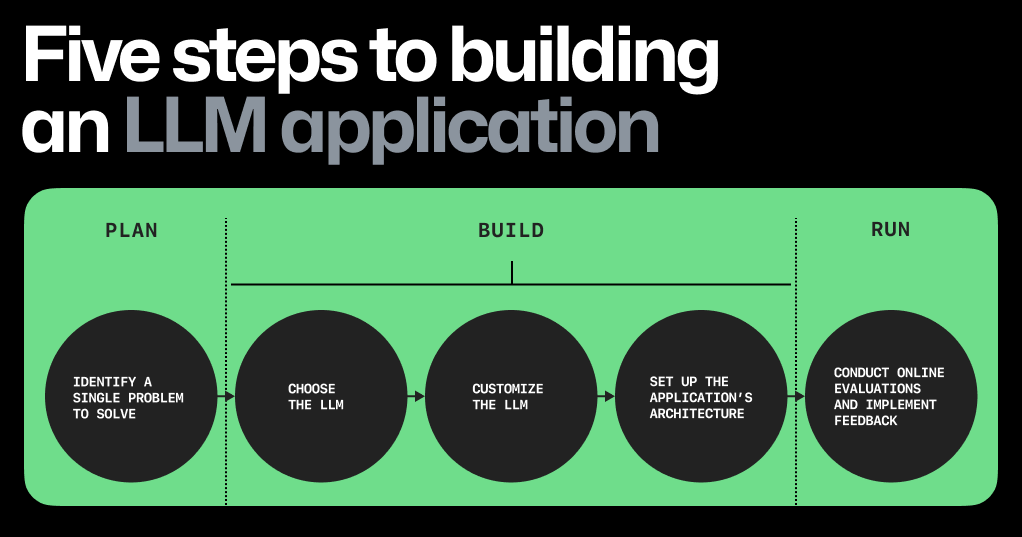
点击图表以放大和保存。
现在,让我们梳理一下今天构建大语言模型应用程序的主要步骤:👇
1. 首先,专注解决一个问题。关键在于找到一个适中的问题:它需要足够具体,让你能快速迭代并取得进展;同时又要足够广泛,以便找到的解决方案能给用户带来惊喜。
比如,GitHub Copilot 团队起初并没有尝试用 AI 解决所有开发者的问题,而是集中精力于软件开发生命周期的一个环节:在集成开发环境 (IDE) 中编写功能代码。
2. 选择合适的大语言模型。通过使用预训练模型来构建大语言模型应用可以节省成本,但关键在于如何挑选合适的模型。以下是一些考虑因素:
- 许可问题。如果你计划将来销售你的大语言模型应用,就必须选择一个得到商业用途授权的 API 模型。这里有一个社区提供的可用于商业的开放大语言模型清单,可供你参考。
- 模型的规模。大语言模型的规模差异巨大,参数数量从 70 亿到 1750 亿不等,像 Ada 这样的模型参数甚至只有 3.5 亿。大多数目前的大语言模型参数量在 70 至 130 亿之间。
我们通常认为,模型的参数越多,其学习新知识和预测能力就越强。但小型模型性能的提升正在挑战这一看法。小型模型通常运行更快、成本更低,而它们在预测质量上的进步,使其成为与那些大名鼎鼎但可能超出许多应用范围的模型的有力竞争者。
- 模型性能考量。在你开始利用微调和上下文学习等技术定制大语言模型前,先评估模型在速度、效率和一致性方面生成期望输出的能力。衡量模型性能时,你可以采用离线评估方法。
3. 定制大语言模型。训练大语言模型意味着构建用于深度学习的支架和神经网络。定制预训练的大语言模型则涉及将其调整以适应特定任务,例如围绕特定主题生成文本或按特定风格编写。下文将重点介绍这方面的技术。为了让预训练的大语言模型满足你的特殊需求,你可以尝试上下文学习、基于人类反馈的强化学习(RLHF)或微调。
- 上下文学习,有时也称为提示工程,指的是在查询模型时提供具体指示或示例,指导模型根据上下文生成相关输出的过程。
上下文学习的方法多种多样,包括提供示例、调整查询方式,或添加描述你的总体目标的句子。
- 强化学习和人类反馈 (RLHF) 涉及为预训练的大语言模型 (大语言模型) 设立一个奖励模型。这个模型的任务是预测用户是否会接受或拒绝模型的输出。奖励模型从中学习到的知识会反馈给原始的大语言模型,使其根据用户的接受程度调整输出。
RLHF 的一大优势是它不依赖于传统的监督学习,因此能够接受更多样的输出结果。在充分的人类反馈下,大语言模型能够识别到,如果用户有 80% 的可能性接受某个输出,那么生成这样的输出就是合理的。想亲自试试吗?可以查看这些 包括代码库的 RLHF 相关资源。
- 微调 (Fine-tuning) 是指将模型生成的输出与一个特定的、已知的输出进行比较的过程。举个例子,你知道“汤太咸了”这句话所表达的情绪是负面的。要评估大语言模型,你可以将这句话输入模型,并询问它将情绪标记为正面还是负面。如果模型错误地将其标记为正面,你就需要调整模型的参数,然后再次进行测试,看它是否能正确地将情绪识别为负面。
微调可以让大语言模型在特定任务上变得更加精确,但这种方法依赖于耗时的监督学习。简而言之,每个输入样本都需要一个标记有确切答案的输出,以便将实际输出与标准输出进行比较,并据此调整模型参数。正如前文所述,与微调相比,RLHF 的优势在于它不需要精确的标签。
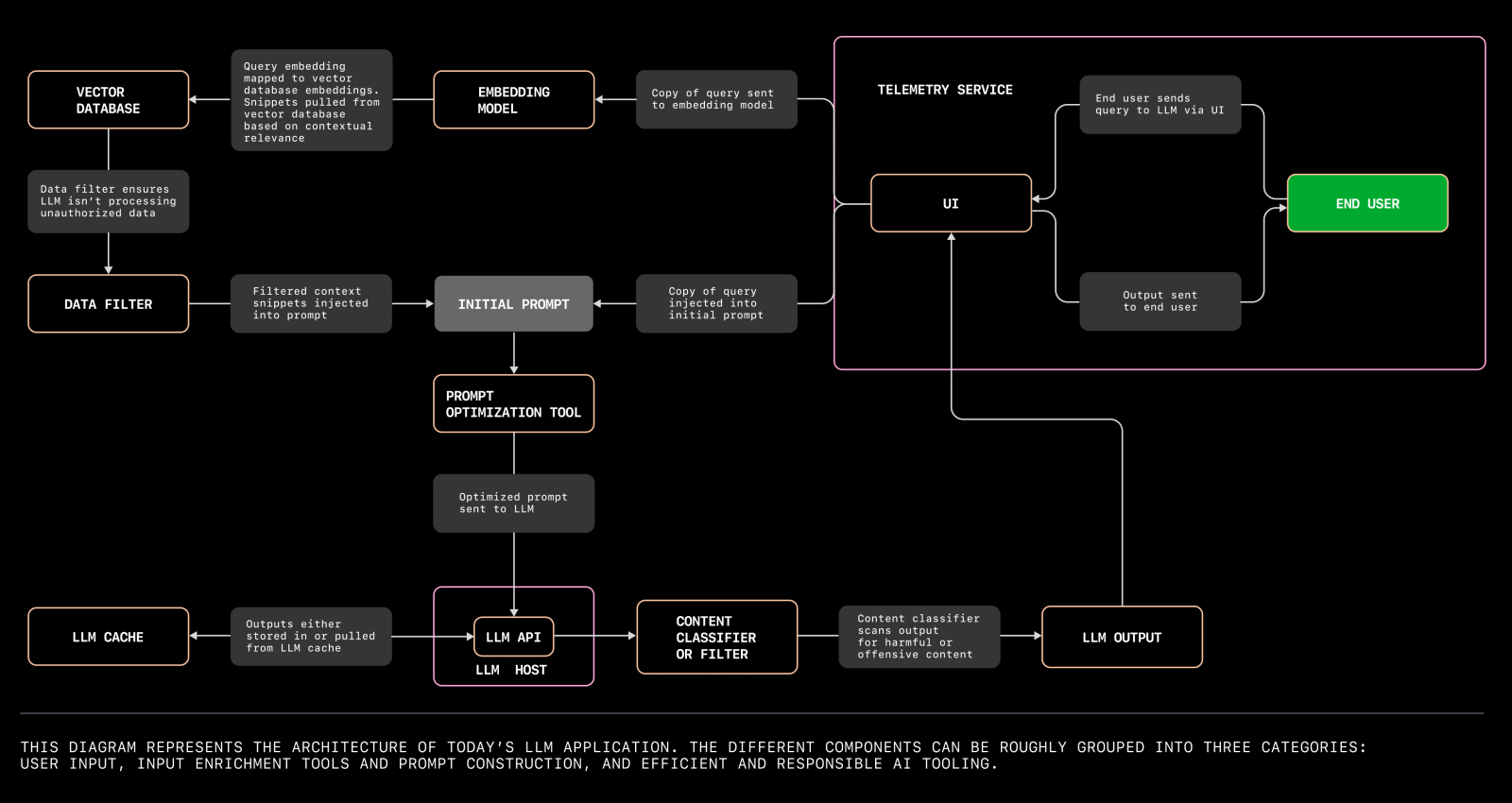
4. 构建应用的架构。搭建大语言模型应用时,你需要的各种组件大致可以分为三类:
- 用户输入,包括用户界面 (UI)、大语言模型和应用托管平台。
- 输入增强和提示构建工具,涵盖了数据源、嵌入模型、向量数据库、提示构建与优化工具以及数据过滤器。
- 高效且负责任的 AI 工具,包括大语言模型的缓存、内容分类器或过滤器,以及一个用于评估大语言模型应用输出的遥测服务。
5. 对你的应用进行在线评估。所谓“在线评估”,是指在用户交互过程中对大语言模型的性能进行评价。例如,GitHub Copilot 的在线评估通过计算接受率(开发者接受系统提供的代码补全的频率)和保留率(开发者对接受的代码补全进行修改的频率和程度)来进行。
大语言模型应用的新兴架构
我们来深入探讨大语言模型应用的架构。以我们的朋友 Dave 的经历为例,他在世界杯观赛派对当天遭遇了 Wi-Fi 断线的状况。幸运的是,一个基于大语言模型 (LLM) 的智能助手帮助他及时修复了 Wi-Fi,使得他能够观看比赛。
利用这个案例以及上方的图解,我们将逐步解析大语言模型应用的用户操作流程,以及搭建这样一个应用所需要的各种工具。👇
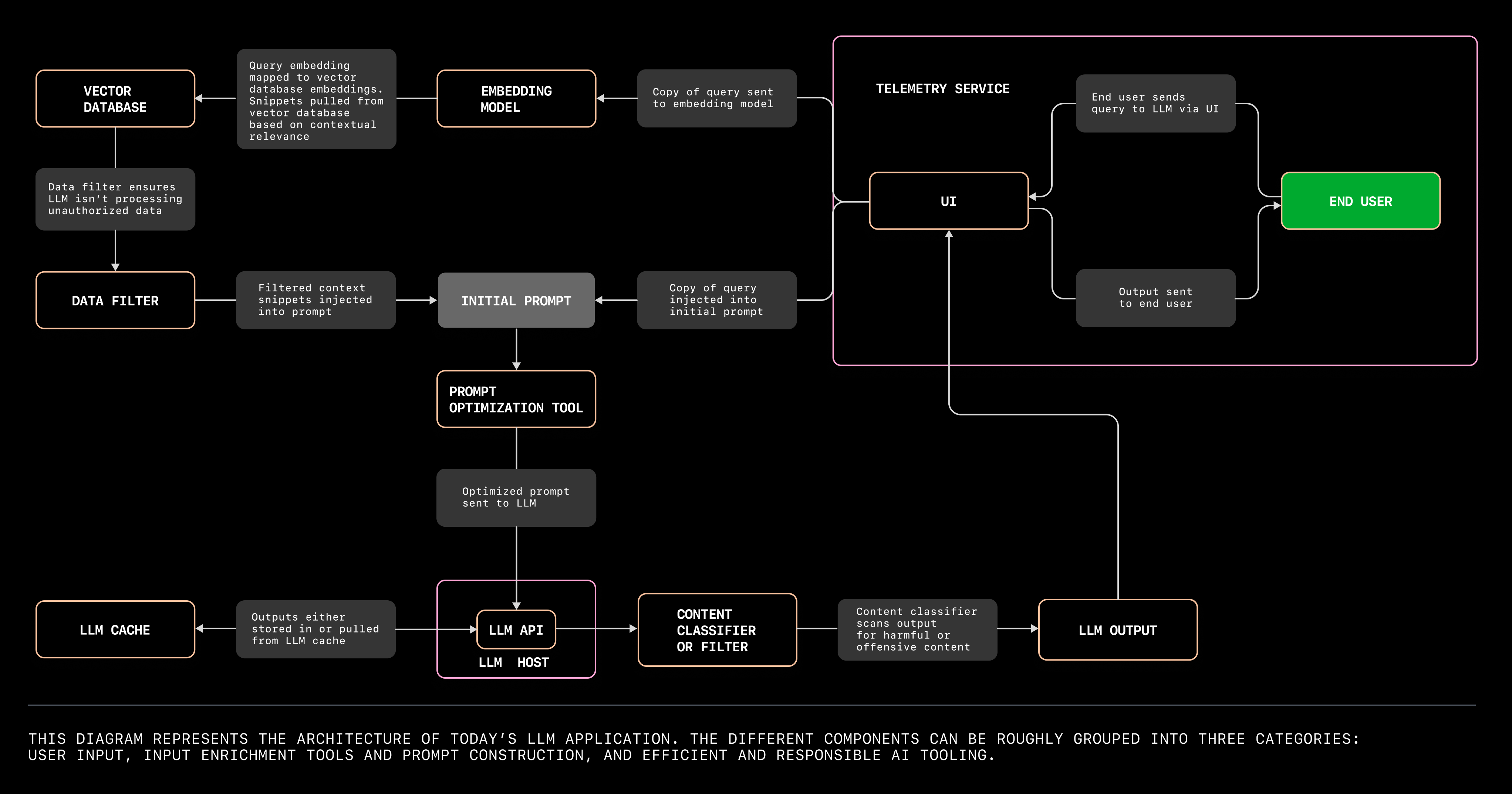
点击图表以放大查看并保存。
用户输入工具
当 Dave 的 Wi-Fi 出现问题时,他致电互联网服务提供商 (ISP),接听的是一位由大语言模型 (LLM) 驱动的助理。助理询问 Dave 的紧急情况,Dave 回答:“我的电视原本连接着 Wi-Fi,但我不小心碰到了柜子,Wi-Fi 设备掉落了!现在我们连比赛都看不了。”
为了使 Dave 能与 LLM 进行交互,我们需要四种工具:
- LLM API 和宿主:LLM 应用是在本地机器上运行还是在云端?对于 ISP 这样的服务提供商来说,通常会选择云端托管,以应对像 Dave 这样的大量呼叫。Vercel 和早期项目如 jina-ai/rungpt 提供了云原生的解决方案,用于部署和扩展 LLM 应用。
如果你想自己动手制作一个 LLM 应用以进行实验,将模型部署在个人设备上可能更节省成本,因为你不需要每次实验都支付云环境的启动费用。在 GitHub Discussions 上,你可以找到关于类似 LLaMA 模型的硬件要求的讨论,两个相关讨论可以在这里和这里查看。
- 用户界面 (UI):Dave 的键盘实际上就是用户界面,但要让 Dave 通过键盘从选项菜单切换到紧急服务线路,用户界面需要包含一个路由工具。
- 语音到文本转换工具:接着,Dave 的语音查询需要通过一个在后台运行的语音到文本转换工具来处理。
输入增强与提示构建工具
让我们再看看 Dave 的例子。大语言模型 (LLM) 能够分析 Dave 话语中的词序列,识别出这是一个 IT 类的投诉,并给出相应的回应。这得益于大语言模型接受了包含 IT 支持文档在内的整个互联网语料库的训练。
输入增强工具 的目的是以一种能够让大语言模型提供最有用回应的方式来整理和包装用户的查询。
-
向量数据库 是存储嵌入或索引高维向量的地方。通过提供额外信息来进一步增强用户查询的上下文,它提高了大语言模型给出有用回应的可能性。
例如,如果大语言模型助手可以访问公司的投诉搜索引擎,并且这些投诉及解决方案以嵌入形式存储在向量数据库中,那么大语言模型助手就不仅利用互联网上的 IT 支持文档,还会使用与 ISP 客户问题相关的特定文档信息。
-
但要从向量数据库中检索与用户查询相关的信息,我们需要一个嵌入模型来将查询转换成嵌入。由于向量数据库中的嵌入以及 Dave 的查询都被转换成高维向量,这些向量能够捕捉自然语言的语义和意图,而非仅限于其语法结构。
这里是一些 开源文本嵌入模型 的链接。OpenAI 和 Hugging Face 也提供了嵌入模型。
Dave 的上下文化查询会是这样的:
// 注意以下相关信息。注意颜色和闪烁模式。// 注意以下相关信息。// 以下是来自 Dave Anderson,IT 支持专家的 IT 投诉。回答 Dave 的问题应作为 ISP 对其客户提供卓越支持的一个示例。*Dave: 哦,太糟糕了!今天是大比赛日。我的电视连接到了我的 Wi-Fi,但我不小心碰到柜台,Wi-Fi 盒子掉下来摔坏了!现在我们看不了比赛了。
这些提示不仅把 Dave 的问题定位为 IT 投诉,还引入了公司投诉搜索引擎中的相关上下文,包括常见的互联网连接问题及其解决方案。
MongoDB 最近推出了 Vector Atlas Search 的公开预览版,这是一款能够在 MongoDB 中索引高维向量的工具。此外,Qdrant、Pinecone 和 Milvus 也提供了免费或开源的向量数据库服务。
- 数据过滤器 的作用是确保大语言模型 (LLM) 不处理那些未经授权的数据,比如个人身份信息。像 amoffat/HeimdaLLM 这类初期项目就在努力确保 LLM 只能访问那些得到授权的数据。
- 然后,提示优化工具 会帮助把用户的查询需求和所有相关背景结合起来。也就是说,这个工具会帮助判断哪些背景信息嵌入更加重要,并决定这些信息应该如何排序,以便让 LLM 能够给出最符合背景的回答。这一过程在机器学习领域被称为提示工程,即通过一系列算法来创建一个提示。(值得一提的是,这与用户自行进行的提示工程不同,后者通常被称为上下文学习)。
像 langchain-ai/langchain 这样的提示优化工具能帮你为用户编写提示。如果你不使用这些工具,那么就需要自己开发一套算法,从向量数据库中提取嵌入信息,捕获相关背景片段,并对它们进行排序。如果你选择这种方式,可以利用 GitHub Copilot Chat 或 ChatGPT 来帮忙。
了解 GitHub Copilot 团队是如何运用 Jaccard 相似度 来确定哪些背景信息最符合用户查询需求的方法 >
高效且负责任的 AI [工具]
为了防止 Dave 在等待大语言模型 (LLM) 助手回应时变得更加沮丧,LLM 能迅速从缓存中获取答案。如果 Dave 失控了,我们可以利用内容分类器确保 LLM 应用不会做出相应的反应。此外,遥测服务还会分析 Dave 与界面的互动,帮助开发者基于他的行为优化用户体验。
- LLM 缓存 能存储之前的回应。这意味着对于相同的问题(比如 Dave 并不是第一个遇到网络故障的人),LLM 可以直接从缓存中取得类似问题的答案,而不必重新生成。这样做能减少等待时间、计算成本和建议的不确定性。
你可以尝试使用 zilliztech/GPTcache 等工具来缓存应用的回应。
- 内容分类器或过滤器 可以阻止自动助手做出有害或冒犯性的回应(尤其是在面对用户的愤怒时)。
工具如 derwiki/llm-prompt-injection-filtering 和 laiyer-ai/llm-guard 尽管还在初期阶段,但已在努力解决这一问题。
- 遥测服务 使你能够实时了解应用在真实用户中的表现。一个负责任且透明地监控用户行为(比如他们接受或修改建议的频率)的服务,能提供宝贵的数据,帮你改进应用,使其更加实用。
比如,OpenTelemetry 是一个开源框架,它为开发者提供了一种标准化的方法来收集、处理和导出遥测数据,适用于开发、测试、分阶段部署和生产环境。
了解 GitHub 如何利用 OpenTelemetry 来评估 Git 的性能 >
太棒了!🥳 你的 LLM 助手成功解答了 Dave 的所有疑问。他的路由器现已正常工作,他已经准备好参加自己的世界杯观看派对了。任务完成!
大语言模型在现实世界中的影响
正在寻找创新灵感或探索的新问题领域?这里有一些正在进行的项目,展示了大语言模型应用和模型如何在真实世界中发挥作用。
- NASA 和 IBM 最近将最大的地理空间 AI 模型开源了,目的是为了让更多人能够接触 NASA 的地球科学数据。这一举措旨在加快对气候变化影响的发现和理解。
- 可以了解一下约翰霍普金斯应用物理实验室是如何设计一款对话型 AI 代理的。这个 AI 代理能够用简洁的英语,根据既定的护理程序为没有受过专业训练的士兵提供医疗指导。
- 例如Duolingo和Mercado Libre等公司正在利用GitHub Copilot帮助更多人免费学习外语,并分别推动拉丁美洲电子商务的普及化。