提示工程的基本理念以及如何将这些理念应用于提升大语言模型的性能 [译]
这里介绍了提示工程的基本理念以及如何将这些理念应用于提升大语言模型 (LLM) 的性能...
大语言模型的接口:大语言模型广受欢迎的一个重要原因在于,其文本到文本的接口极其简单,用户可以轻松使用。在早期,使用深度学习解决一个任务通常需要对模型进行微调,通过数据训练使其掌握解决该任务的方法。而且,这些模型大都只专注于单一任务。但是,大语言模型具备了通过文本提示解决多种问题的能力,这种在上下文中的学习能力使得原本复杂的问题解决方式转变为自然语言的形式!
“提示工程是一门新兴学科,专注于开发和优化提示,以便在各种应用和研究主题中高效利用语言模型 (LM)。” - 引自 [1]
什么是提示工程?大语言模型的简单化使其使用变得更加普及。无需成为数据科学家或机器学习工程师 (MLE),只要你懂得英语(或其他任何你选择的语言),你就可以利用大语言模型解决复杂的问题!不过,使用大语言模型解决问题的成效很大程度上依赖于提供的文本提示。因此,提示工程——一种通过实验不同的提示来优化大语言模型性能的实证科学——已经变得极为流行,并带来了许多创新技术和最佳实践。
提示词的组成部分:虽然激发大语言模型的方式多种多样,但大多数方法都包含几个共同的组成部分:
- 输入数据:大语言模型预期要处理的实际数据(例如,进行翻译或分类的句子,需要总结的文档等)。
- 示例:提示中包括的正确输入 - 输出对的具体实例。
- 指令:模型应给出的输出的文本描述。
- 标签:用于在提示中构建结构的标签或格式化元素。
- 上下文:提供给大语言模型的额外信息。
如下图所示,我们看到一个示例,其中一个单独的提示整合了上述所有组件,用于句子分类。

上下文窗口:在预训练阶段,大语言模型 (LLM) 会处理固定长度的输入序列。这种序列长度的设定最终定义了模型的“上下文长度”,也就是模型能处理的最长序列。如果输入的文本序列远超这一固定长度,模型可能无法预测其行为,从而输出错误的结果。不过,有一些方法如 Self-Extend [2] 或位置插值 (positional interpolation) [3] 可以扩展模型的上下文窗口。
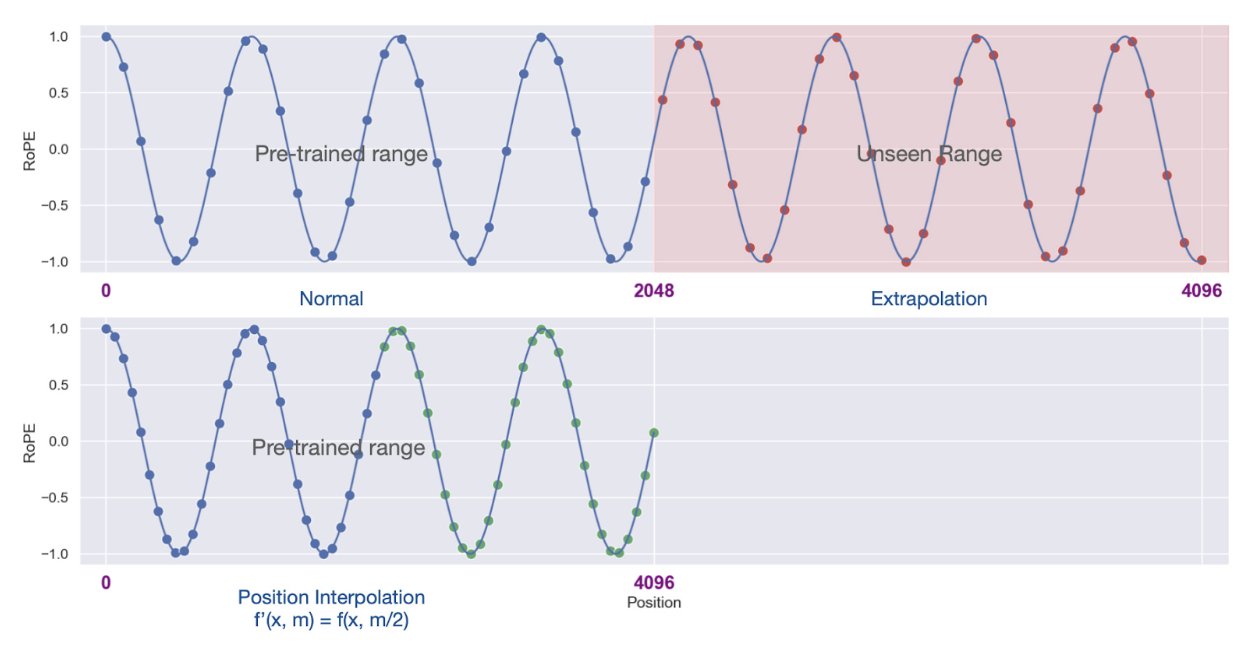
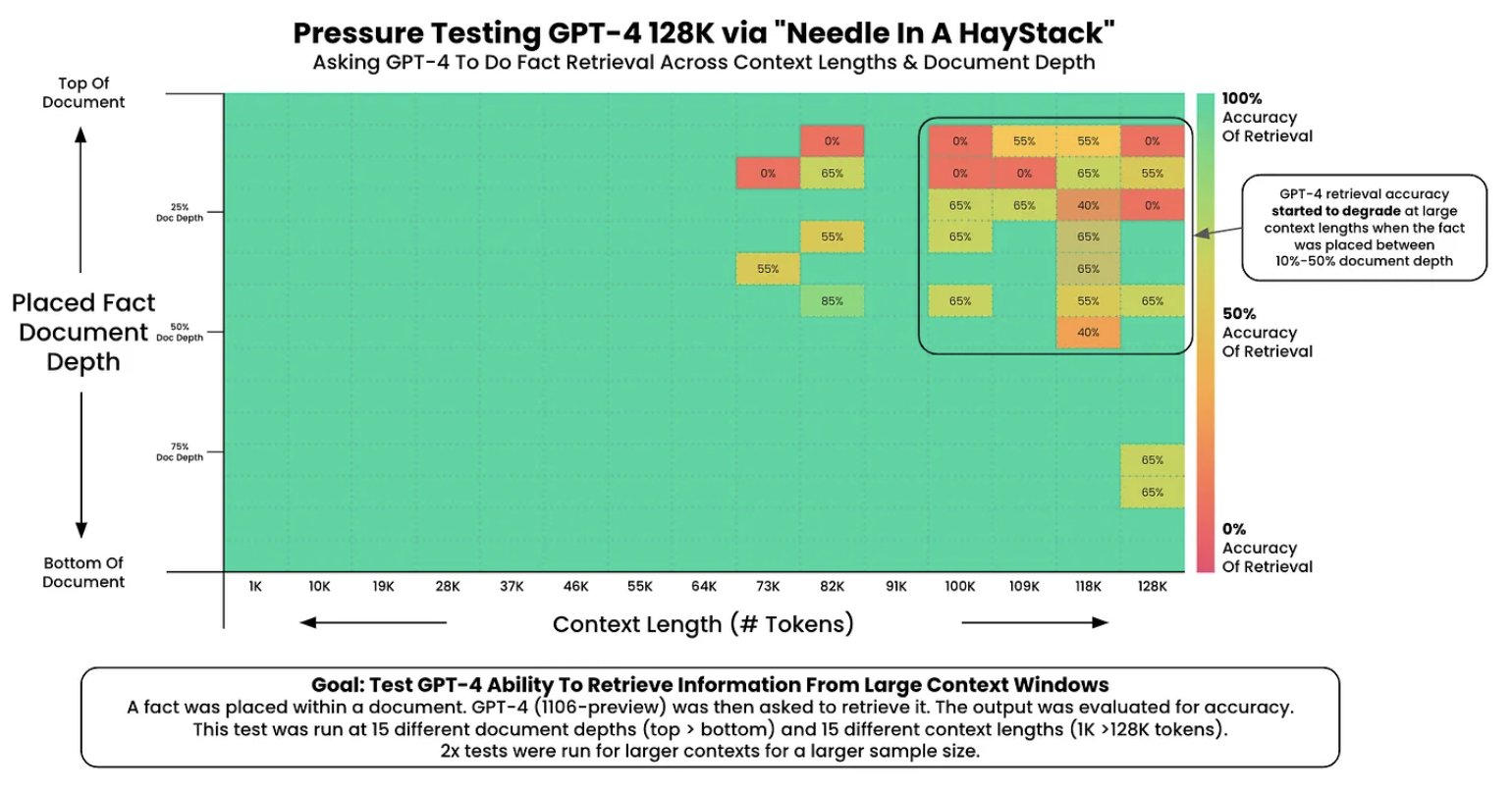
近期的大语言模型研究强调了建立较长的上下文窗口的重要性,这使得模型可以在每个提示中处理更多信息,如更多案例或更广泛的上下文。但并非所有大语言模型都能完美地关注其上下文。大语言模型利用长上下文窗口的能力,通常通过“针对干草堆测试” (needle in the haystack test) [4] 来评估,该测试包括:
- 将一个随机事实嵌入上下文中;
- 要求模型找出这个事实;
- 在不同上下文长度及事实的上下文位置重复此测试。
这类测试通常会展示出一个类似下图的情况(摘自 [4]),在这里我们可以直观地看到上下文窗口存在的问题。
我的提示工程策略:根据使用的模型不同,提示工程的细节有很大的差异。尽管如此,一些基本原则常常对引导这一过程大有裨益:
- 实证非常关键:提示工程的首步是建立一套可靠的评估体系(如通过测试案例、人工评价或用大语言模型作为裁判),这样可以方便地监测对提示策略所做的调整。
- 基础先行:开始的提示应尽量简单,不宜立即使用连锁思维等复杂技巧。首先应使用最基本的提示,逐步增加其复杂度,通过性能变化来判断是否真的需要更多复杂性。
- 明确具体:在制定提示时,要尽量避免含糊其辞,直接明确地描述你期望大语言模型输出的内容。
- 利用示例:如果难以具体描述期望的输出,可以加入一些示例到提示中。这些示例通过提供具体案例来帮助消除歧义。
- 避免不必要的复杂性:虽然有时复杂的提示策略是解决问题所需(比如处理多步推理任务),但我们应谨慎考虑是否真的需要。通过实证评估来确定这种复杂性是否必须。
综上所述,我个人的提示工程策略包括:i) 构建一个高效的评估体系;ii) 从简单的提示开始;iii) 根据需要逐步增加复杂度,以实现预期的性能水平。
