文本分割的五个层次 [译]
Greg Kamradt
在这个教程中,我们将探讨文本分割的五个层次。需要说明的是,这份列表式非官方的。
你是否遇到过这种情形:尝试向 ChatGPT 输入长篇文本,却被告知内容过长?或者你在尝试改善应用程序的长期记忆能力,但似乎效果仍不理想。
要提升语言模型应用的性能,一个非常有效的策略是将大型数据切分为小块。这个过程被称为分割(splitting)或分块(chunking)(这两个术语我们将交替使用)。在多模态领域中,分割同样适用于图像。
这篇文章篇幅较长,但如果你能坚持阅读到最后,我保证你将对分块理论、策略以及进一步学习的资源有一个全面的了解。
文本分割的五个层次
- 第 1 层:字符分割 - 对数据进行简单的静态字符划分。
- 第 2 层:递归字符文本分割 - 基于分隔符列表的递归式分块。
- 第 3 层:文档特定分割 - 针对不同类型文档(如 PDF、Python、Markdown)的特定分块方法。
- 第 4 层:语义分割 - 基于嵌入式路径的分块方法。
- 第 5 层:智能体式分割 - 使用类似智能体的系统来分割文本的实验性方法,适用于你认为 Token 成本接近免费的情况。
- 额外层级: 替代表示分块 + 索引 - 利用原始文本的派生表示形式,以帮助检索和建立索引。
笔记本资源:
- 视频概览 - 本教程的视频演示,详细解说代码实现
- ChunkViz.com - 数据块划分方法的直观可视化展示
- RAGAS - 一种检索评估框架
这个教程是由 Greg Kamradt 用心制作的。遵循 MIT 许可证,我们欢迎任何形式的致谢。
本教程将介绍 LangChain (pip install langchain) 和 Llama Index (pip install llama-index) 中的代码应用。
评估
在评估检索效果时,测试你的数据块划分策略是非常关键的。如果应用的整体性能不佳,那么你如何划分数据块就显得不那么重要了。
评估框架包括:
我不打算为每种方法演示具体的评估,因为成功取决于特定的应用领域。我随意选择的评估可能不适合你的数据。如果你对合作进行各种数据块划分策略的严格评估感兴趣,请联系我们 (contact@dataindependent.com)。
如果从这个教程中你只记住一点,请确保是块分割戒律(The Chunking Commandment)
**块分割戒律:**我们的目标不仅仅是为了划分数据块。更重要的是,我们要以一种便于日后检索和提取价值的格式来整理我们的数据。
第 1 级:字符拆分
字符拆分是文本拆分的最基础方式。它仅仅是把文本切分成 N 个字符的片段,不考虑它们的内容或形式。
虽然这种方法并不适用于任何实际应用,但它是一个良好起点帮助我们理解分割的基本概念。
- 优点: 简单易懂
- 缺点: 过于死板,不考虑文本的结构
需要掌握的概念:
- 块大小 (Chunk Size) - 你想要的每个块包含的字符数,比如 50、100、100,000 等。
- 块重叠 (Chunk Overlap) - 你希望连续块之间重叠的字符数。这是为了尽量不把一个完整的上下文分割成多个部分。这会在不同块间产生重复数据。
首先,让我们找一些样本文本
In [1]:
text = "This is the text I would like to chunk up. It is the example text for this exercise"
接下来,我们手动进行文本拆分
In [4]:
# Create a list that will hold your chunkschunks = []chunk_size = 35 # Characters# Run through the a range with the length of your text and iterate every chunk_size you wantfor i in range(0, len(text), chunk_size):chunk = text[i:i + chunk_size]chunks.append(chunk)chunks
Out [4]:
['This is the text I would like to ch','unk up. It is the example text for ','this exercise']
恭喜你!你刚完成了第一次文本拆分。虽然我们还有很长的路要走,但你已经迈出了第一步。现在感觉自己像不像一个语言模型的使用者呢?
在语言模型领域处理文本时,我们不仅仅处理原始字符串。更常见的是处理文档。文档不仅包含我们关注的文本,还包括额外的元数据,方便之后的筛选和操作。
我们可以把字符串列表转换成文档,但从头开始创建文档可能更有意义。
让我们使用 LangChains 的 CharacterSplitter 来帮我们完成这个任务
In [5]:
from langchain.text_splitter import CharacterTextSplitter
然后我们加载这个文本拆分器。需要特别指定 chunk overlap(块重叠)和 separator(分隔符),否则可能会得到意想不到的结果。接下来我们会详细介绍这些。
In [6]:
text_splitter = CharacterTextSplitter(chunk_size = 35, chunk_overlap=0, separator='', strip_whitespace=False)
接下来,我们可以通过 create_documents 真正地拆分文本。注意,create_documents 需要一个文本列表,所以如果你只有一个字符串(就像我们现在这样),你需要用 [] 把它包起来
In [7]:
text_splitter.create_documents([text])
Out [7]:
[Document(page_content='This is the text I would like to ch'),Document(page_content='unk up. It is the example text for '),Document(page_content='this exercise')]
注意,这次我们得到的是相同的块,但它们被封装在文档中。这样更方便与 LangChain 生态的其他部分协同工作。另外,注意第二块末尾的空白被移除了。这是 LangChain 自动完成的,详见这一行代码。通过设置 strip_whitespace=False 可以避免这个问题。
块重叠 & 分隔符
块重叠 (Chunk Overlap) 使我们的文本块相互融合,块 #1 的末尾和块 #2 的开头将会是相同的内容,依此类推。
这次我将使用 4 个字符的重叠值来设置我的块重叠。
In [8]:
text_splitter = CharacterTextSplitter(chunk_size = 35, chunk_overlap=4, separator='')
In [9]:
text_splitter.create_documents([text])
Out [9]:
[Document(page_content='This is the text I would like to ch'),Document(page_content='o chunk up. It is the example text'),Document(page_content='ext for this exercise')]
请注意,我们的数据块是相同的,但现在第 1 块和第 2 块、第 2 块和第 3 块之间出现了重叠。例如,第 1 块的尾部含有 'o ch',这与第 2 块开头的 'o ch' 相匹配。
为了更好地可视化这一点,我创建了 ChunkViz.com 这个网站来帮助展示这个概念。下面是同一段文本的可视化效果。

注意图中展示的三种不同颜色,以及其中的两个重叠区域。
分隔符(Separators) 指的是您选择用于分割数据的字符序列。例如,如果您希望在 ch 处对数据进行分块,您可以这样设置。
In [14]:
text_splitter = CharacterTextSplitter(chunk_size = 35, chunk_overlap=0, separator='ch')
In [15]:
text_splitter.create_documents([text])
Out [15]:
[Document(page_content='This is the text I would like to'),Document(page_content='unk up. It is the example text for this exercise')]
Llama Index
在数据分块和索引过程中 Llama Index 提供了极大的灵活性。他们默认提供的节点关系功能,可以在之后的数据检索中发挥重要作用。
我们来看一下他们的句子分割器。这个分割器在功能上与字符分割器类似,但在默认设置下,它会按照句子进行分割。
In [16]:
from llama_index.text_splitter import SentenceSplitterfrom llama_index import SimpleDirectoryReader
加载您的分割器
In [17]:
splitter = SentenceSplitter(chunk_size=200,chunk_overlap=15,)
加载您的文档
In [18]:
documents = SimpleDirectoryReader(input_files=["../data/PaulGrahamEssayMedium/mit.txt"]).load_data()
创建您的节点。节点(Nodes)与文档相似,但包含了更多的关系数据。
In [21]:
nodes = splitter.get_nodes_from_documents(documents)
现在,让我们来看一个节点的例子
In [22]:
nodes[0]
Out [22]:
TextNode(id_='6ef3c8f2-7330-42f2-b492-e2d76a0a01f5',embedding=None,metadata={'file_path': '../data/PaulGrahamEssayMedium/mit.txt', 'file_name': 'mit.txt', 'file_type': 'text/plain', 'file_size': 36045, 'creation_date': '2023-12-21', 'last_modified_date': '2023-12-21', 'last_accessed_date': '2023-12-21'},excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'],excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'],relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='b8b090da-5c4d-40cf-8246-44dcf3008aa8', node_type=<ObjectType.DOCUMENT: '4'>,metadata={'file_path': '../data/PaulGrahamEssayMedium/mit.txt', 'file_name': 'mit.txt', 'file_type': 'text/plain', 'file_size': 36045, 'creation_date': '2023-12-21', 'last_modified_date': '2023-12-21', 'last_accessed_date': '2023-12-21'},hash='203cdcab32f6aac46e4d95044e5dce8c3e2a2052c2d172def021e0724f515e36'), <NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='3157bde1-5e51-489e-b4b7-f80b74063ea9', node_type=<ObjectType.TEXT: '1'>,metadata={},hash='5ebb6555924d31f20f1f5243ea3bfb18231fbb946cb76f497dbc73310fa36d3a')},hash='fe82de145221729f15921a789c2923659746b7304aa2ce2952b923f800d2b85d',text="Want to start a startup? Get funded by\nY Combinator.\n\n\n\n\nOctober 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school. I think there will increasingly be a third option:\nto start your own startup. But how common will that be?I'm sure the default will always be to get a job, but starting a\nstartup could well become as popular as grad school. In the late\n90s my professor friends used to complain that they couldn't get\ngrad students, because all the undergrads were going to work for\nstartups.",start_char_idx=2, end_char_idx=576,text_template='{metadata_str}\n\n{content}',metadata_template='{key}: {value}',metadata_seperator='\n')
可以看到,Llama Index 的节点中包含了丰富的关系数据。我们稍后会详细讨论这些内容,现在我们不急于深入。
基本的字符分割可能只适用于少数应用场景,或许正适合您的需求!
第 2 级:递归字符文本切分
现在,我们来探索一个更高层次的复杂性。
第 1 级的方法存在一个问题:我们完全忽视了文档的结构,只是单纯按固定字符数量进行切分。
递归字符文本切分器能够解决这一问题。通过它,我们可以设定一系列的分隔符来切分文档。
你可以在这里查看 LangChain 默认的分隔符。让我们逐一了解这些分隔符:
- "\n\n" - 双换行符,通常用于标记段落结束
- "\n" - 换行符
- " " - 空格
- "" - 单个字符
我不太清楚为什么句号(".")没有被列入其中。可能是因为句号不是一个普遍适用的分隔符吗?如果你有所了解,欢迎告诉我。
这个切分器就像是瑞士军刀,适用于快速搭建初步应用。如果你不确定从哪个切分器开始,这个是个不错的选择。
我们来试一试:
In [23]:
from langchain.text_splitter import RecursiveCharacterTextSplitter
然后加载一段较长的文本:
In [24]:
text = """One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear.Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor's, you don't get half as many customers. You get no customers, and you go out of business.It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]"""
现在创建我们的文本切分器:
In [25]:
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 65, chunk_overlap=0)
In [28]:
text_splitter.create_documents([text])
Out [28]:
[Document(page_content="One of the most important things I didn't understand about the"),Document(page_content='world when I was a child is the degree to which the returns for'),Document(page_content='performance are superlinear.'),Document(page_content='Teachers and coaches implicitly told us the returns were linear.'),Document(page_content='"You get out," I heard a thousand times, "what you put in." They'),Document(page_content='meant well, but this is rarely true. If your product is only'),Document(page_content="half as good as your competitor's, you don't get half as many"),Document(page_content='customers. You get no customers, and you go out of business.'),Document(page_content="It's obviously true that the returns for performance are"),Document(page_content='superlinear in business. Some think this is a flaw of'),Document(page_content='capitalism, and that if we changed the rules it would stop being'),Document(page_content='true. But superlinear returns for performance are a feature of'),Document(page_content="the world, not an artifact of rules we've invented. We see the"),Document(page_content='same pattern in fame, power, military victories, knowledge, and'),Document(page_content='even benefit to humanity. In all of these, the rich get richer.'),Document(page_content='[1]')]
你会发现现在有更多的文本块以句号结尾。这是因为这些文本块可能是段落的末尾,切分器首先会寻找双换行符来切分段落。
在段落被切分之后,切分器会根据文本块的大小再次进行切分。如果文本块过大,它会使用下一个分隔符进行切分,依此类推。
对于这种长度的文本,我们可以使用更大的分隔符来切分。
In [29]:
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 450, chunk_overlap=0)text_splitter.create_documents([text])
Out [29]:
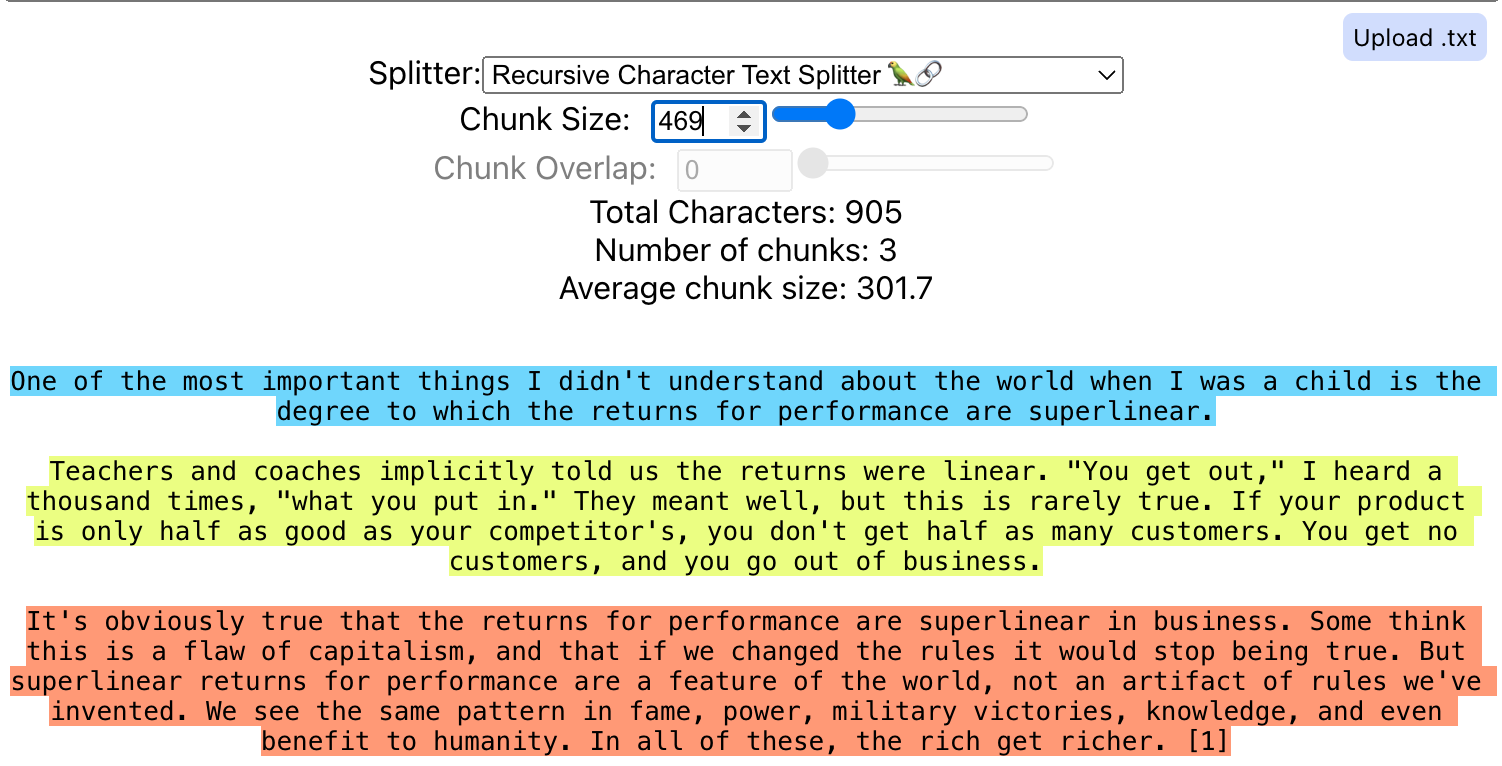
[Document(page_content="One of the most important things I didn't understand about the world when I was a child is the degree to which the returns for performance are superlinear."),Document(page_content='Teachers and coaches implicitly told us the returns were linear. "You get out," I heard a thousand times, "what you put in." They meant well, but this is rarely true. If your product is only half as good as your competitor\'s, you don\'t get half as many customers. You get no customers, and you go out of business.'),Document(page_content="It's obviously true that the returns for performance are superlinear in business. Some think this is a flaw of capitalism, and that if we changed the rules it would stop being true. But superlinear returns for performance are a feature of the world, not an artifact of rules we've invented. We see the same pattern in fame, power, military victories, knowledge, and even benefit to humanity. In all of these, the rich get richer. [1]")]
对于这段文本,使用 450 作为分隔符可以完美切分段落。即使将分隔符改为 469,也能得到相同的效果。这是因为切分器内置了一定的缓冲空间和弹性,使得文本块能够自动对齐到最近的分隔符。
我们来直观地看一下:
哇,你已经顺利进入了第二级,真是太棒了!我们正取得连续的进展。如果你对这些内容感兴趣,我会定期向邮件订阅者发送我正在进行的项目更新。想要第一手资讯的话,可以在这里订阅。
第 3 级:特定文档的分割策略
随着我们在处理文档类型的方法上更进一步,这里我们不仅仅局限于处理普通的文本文件(如 .txt)。当你遇到包含图片、PDF 或代码片段的文档时,该怎么办呢?
对于这些情况,我们之前的两个级别的处理方式可能并不适用,因此我们需要寻找一个新的解决策略。
这个级别的重点是让你的数据分割策略能够适应不同的数据格式。下面让我们通过几个实例来展示这一点。
处理 Markdown、Python 和 JS 文件的分割器,基本上与“递归字符”分割器类似,但使用的分隔符不同。
你可以在这里查看 LangChains 的所有文档分割器工具,以及 Llama Index 的相关工具(包括用于HTML、JSON 和 Markdown的工具)。
Markdown
你可以在这里查看 Markdown 文档的分隔符。
分隔符包括:
\n#{1,6}- 根据新行后跟标题(H1 到 H6)来分割```\n- 代码块\n\\*\\*\\*+\n- 水平线\n---+\n- 水平线\n___+\n- 水平线\n\n双新行\n- 新行" "- 空格""- 字符
In [30]:
from langchain.text_splitter import MarkdownTextSplitter
In [32]:
splitter = MarkdownTextSplitter(chunk_size = 40, chunk_overlap=0)
In [33]:
markdown_text = """# Fun in California## DrivingTry driving on the 1 down to San Diego### FoodMake sure to eat a burrito while you're there## HikingGo to Yosemite"""
In [34]:
splitter.create_documents([markdown_text])
Out [34]:
[Document(page_content='# Fun in California\n\n## Driving'),Document(page_content='Try driving on the 1 down to San Diego'),Document(page_content='### Food'),Document(page_content="Make sure to eat a burrito while you're"),Document(page_content='there'),Document(page_content='## Hiking\n\nGo to Yosemite')]
注意这种分割方式倾向于按 Markdown 的章节来划分。然而,这种方法并不完美。例如,有时候你会发现有些分割块中仅包含单个词语“there”。在处理小尺寸的数据块时,你可能会遇到这种情况。
Python
可以在这里查看 Python 代码分割器的详情链接。
分割器使用的标记:
\nclass- 首先识别类\ndef- 然后是函数\n\tdef- 缩进的函数\n\n- 双新行,表示较大的分隔\n- 新行,用于分隔代码行" "- 空格,分隔代码中的单词或标记""- 字符,每个字符作为单独元素
接下来,让我们看看如何加载并使用这个代码分割器。
代码执行情况如下:
In [35]:
from langchain.text_splitter import PythonCodeTextSplitter
In [36]:
python_text = """class Person:def __init__(self, name, age):self.name = nameself.age = agep1 = Person("John", 36)for i in range(10):print (i)"""
In [37]:
python_splitter = PythonCodeTextSplitter(chunk_size=100, chunk_overlap=0)
In [38]:
python_splitter.create_documents([python_text])
执行结果 [38]:
[Document(page_content='class Person:\n def __init__(self, name, age):\n self.name = name\n self.age = age'),Document(page_content='p1 = Person("John", 36)\n\nfor i in range(10):\n print (i)')]
可以看到,类定义被完整地保留在一个文档中(这是好的),然后代码的其余部分在第二个文档中(也可以接受)。
我在实际操作中调整了代码块的大小,才得到这样清晰的分割效果。你可能也需要针对你的代码进行类似的调整,这就是为什么使用评估来确定最优代码块大小非常关键。
JS
JavaScript 的处理与 Python 非常相似。具体的分隔符可以在这里找到。
分隔符如下:
\nfunction- 标记函数声明的开始\nconst- 用于声明常量\nlet- 用于声明块级变量\nvar- 用于变量声明\nclass- 标记类定义的开始\nif- 标记 if 语句的开始\nfor- 用于 for 循环\nwhile- 用于 while 循环\nswitch- 用于 switch 语句\ncase- 在 switch 语句中使用\ndefault- 也在 switch 语句中使用\n\n- 表示文本或代码中较大的分隔\n- 分隔代码或文本的行" "- 分隔代码中的单词或标记""- 使每个字符成为一个单独元素
代码执行情况如下:
In [39]:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language
In [40]:
javascript_text = """// Function is called, the return value will end up in xlet x = myFunction(4, 3);function myFunction(a, b) {// Function returns the product of a and breturn a * b;}"""
In [41]:
js_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.JS, chunk_size=65, chunk_overlap=0)
In [42]:
js_splitter.create_documents([javascript_text])
执行结果 [42]:
[Document(page_content='// Function is called, the return value will end up in x'),Document(page_content='let x = myFunction(4, 3);'),Document(page_content='function myFunction(a, b) {'),Document(page_content='// Function returns the product of a and b\n return a * b;\n}')]
带有表格的 PDF
接下来的内容会更有挑战性。
PDF 是在语言模型应用中极为普遍的数据格式。它们经常包含了重要信息的表格。
这可能包括财务数据、研究内容、学术论文等。
用基于字符的分隔符来切分表格并不可靠。我们需要尝试其他方法。想要更深入了解这方面,我推荐阅读 Lance Martin's 在 LangChain 上发布的 教程。
我将介绍一种文本处理方法。Mayo 也展示了一种 GPT-4V 方法,这种方法通过视觉手段而非文本来提取表格。你可以 In 这里 了解更多。
一个非常方便的方式是使用 Unstructured,这是一个旨在使数据适配大语言模型的专用库。
In [43]:
import osfrom unstructured.partition.pdf import partition_pdffrom unstructured.staging.base import elements_to_json
我们来加载这个 PDF 并对其进行解析。这是来自 Salesforce 的财务报告 的一个 PDF。
In [44]:
filename = "static/SalesforceFinancial.pdf"# Extracts the elements from the PDFelements = partition_pdf(filename=filename,# Unstructured Helpersstrategy="hi_res",infer_table_structure=True,model_name="yolox")
Some weights of the model checkpoint at microsoft/table-transformer-structure-recognition were not used when initializing TableTransformerForObjectDetection: ['model.backbone.conv_encoder.model.layer4.0.downsample.1.num_batches_tracked', 'model.backbone.conv_encoder.model.layer2.0.downsample.1.num_batches_tracked', 'model.backbone.conv_encoder.model.layer3.0.downsample.1.num_batches_tracked']- This IS expected if you are initializing TableTransformerForObjectDetection from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).- This IS NOT expected if you are initializing TableTransformerForObjectDetection from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
让我们来看看解析出来的内容
In [45]:
elements
Out [45]:
[<unstructured.documents.elements.NarrativeText at 0x2b6dc2dd0>,<unstructured.documents.elements.NarrativeText at 0x2b6dc2e10>,<unstructured.documents.elements.NarrativeText at 0x2b6dc1850>,<unstructured.documents.elements.NarrativeText at 0x2b6dc1a50>,<unstructured.documents.elements.NarrativeText at 0x2b6dc1c10>,<unstructured.documents.elements.NarrativeText at 0x2b6dc1dd0>,<unstructured.documents.elements.NarrativeText at 0x2b6dc20d0>,<unstructured.documents.elements.NarrativeText at 0x2b6dc0210>,<unstructured.documents.elements.Table at 0x2b6dc02d0>,<unstructured.documents.elements.NarrativeText at 0x2b5e30850>,<unstructured.documents.elements.Text at 0x2b69abe90>,<unstructured.documents.elements.Text at 0x2b69cc9d0>]
这些只是未经结构化处理的数据,我们可以查看所有内容,但我更想关注它解析出的表格。
In [46]:
elements[-4].metadata.text_as_html
Out [46]:
'<table><thead><th>Revenue)</th><th>Guidance $7.69 - $7.70 Billion</th><th>Guidance $31.7 - $31.8 Billion</th></thead><tr><td>Y/Y Growth</td><td>~21%</td><td>~20%</td></tr><tr><td>FX Impact?)</td><td>~($200M) y/y FX</td><td>~($600M) y/y FX®</td></tr><tr><td>GAAP operating margin</td><td></td><td>~3.8%</td></tr><tr><td>Non-GAAP operating margin)</td><td></td><td>~20.4%</td></tr><tr><td>GAAP earnings (loss) per share</td><td>($0.03) - ($0.02)</td><td>$0.38 - $0.40</td></tr><tr><td>Non-GAAP earnings per share</td><td>$1.01 - $1.02</td><td>$4.74 - $4.76</td></tr><tr><td>Operating Cash Flow Growth (Y/Y)</td><td></td><td>~21% - 22%</td></tr><tr><td>Current Remaining Performance Obligation Growth (Y/Y)</td><td>~15%</td><td></td></tr></table>'
尽管这个表格看起来有些乱,但因为它是 HTML 格式的,大语言模型能够比用制表符或逗号分隔的方式更容易地处理它。你可以将这段 HTML 复制到在线的 HTML 查看器 中,看到它被重新组织的样子。

太棒了,Unstructured 成功地帮我们提取了表格。虽然它不是完美无缺的,但这个团队一直在不断升级他们的工具。
重要点提示: 后来在我们对数据块进行语义搜索时,直接从表格中匹配嵌入可能会比较困难。开发者常用的做法是,在提取了表格之后,对其进行关键信息提取。然后对这些关键信息的总结进行嵌入。如果这个总结的嵌入与你的搜索目标匹配,那么就可以把原始表格交给你的大语言模型处理。
多模态(文本 + 图像)
现在,让我们深入探索多模态文本分割这一领域。这是一个充满活力的领域,其最佳实践方法仍在不断演变。我会介绍一个由 Lance Martin 和他的 LangChain 团队推广的流行方法。你可以在这里查阅他们的源代码。如果你找到了更好的方法,不妨与大家分享!
[47]:
#!pip3 install "unstructured[all-docs]"from typing import Anyfrom pydantic import BaseModelfrom unstructured.partition.pdf import partition_pdf
首先我们需要一个 PDF 文件作为实验材料。这个文件取自于一个关于视觉指令调整的论文。

[48]:
filepath = "static/VisualInstruction.pdf"
[49]:
# Get elementsraw_pdf_elements = partition_pdf(filename=filepath,# Using pdf format to find embedded image blocksextract_images_in_pdf=True,# Use layout model (YOLOX) to get bounding boxes (for tables) and find titles# Titles are any sub-section of the documentinfer_table_structure=True,# Post processing to aggregate text once we have the titlechunking_strategy="by_title",# Chunking params to aggregate text blocks# Attempt to create a new chunk 3800 chars# Attempt to keep chunks > 2000 chars# Hard max on chunksmax_characters=4000,new_after_n_chars=3800,combine_text_under_n_chars=2000,image_output_dir_path="static/pdfImages/",)
你可以在 static/pdfImages/ 目录中找到我们解析出的图像。
仅仅将图像保存在文件夹中是不够的,我们需要对其进行进一步处理!虽然这部分内容稍微超出了文本分割的范畴,但让我们来看看如何利用这些图像。
常用的做法包括利用多模态模型来对图像进行总结,或者直接用图像来完成特定任务。有些人则是提取图像嵌入(例如使用 CLIP)。
为了激发你进一步探索,我们来尝试生成图像摘要。我们将使用 GPT-4V 模型。你也可以在这里探索其他模型。
[50]:
from langchain.chat_models import ChatOpenAIfrom langchain.schema.messages import HumanMessageimport osfrom dotenv import load_dotenvfrom PIL import Imageimport base64import ioload_dotenv()
Out [50]:
True
今天我们将使用 gpt-4-vision 模型
[51]:
llm = ChatOpenAI(model="gpt-4-vision-preview")
我将创建一个简便的函数,帮助将图像从文件格式转换成 base64 编码,这样我们就能将它传送给 GPT-4V 模型
[52]:
# Function to convert image to base64def image_to_base64(image_path):with Image.open(image_path) as image:buffered = io.BytesIO()image.save(buffered, format=image.format)img_str = base64.b64encode(buffered.getvalue())return img_str.decode('utf-8')image_str = image_to_base64("../RetrievalTutorials/static/pdfImages/figure-15-6.jpg")
接下来,我们将图像输入到大语言模型中
[54]:
chat = ChatOpenAI(model="gpt-4-vision-preview",max_tokens=1024)msg = chat.invoke([HumanMessage(content=[{"type": "text", "text" : "Please give a summary of the image provided. Be descriptive"},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{image_str}"},},])])
模型返回的摘要将被储存到我们的向量数据库中。之后在进行检索时,我们会利用这些嵌入来进行语义搜索。
[55]:
msg.content
Out [55]:
'The image shows a baking tray with pieces of food (likely cookies or some baked goods) arranged to loosely resemble the continents on Earth as seen from space. The arrangement is not geographically accurate but is a playful representation, with irregular shapes intended to mimic the continents. Above the tray is a caption that reads, "Sometimes I just look at pictures of the earth from space and I marvel at how beautiful it all is." This caption adds a humorous twist, as the viewer is not looking at the Earth from space but at a whimsical, terrestrial creation that is meant to evoke the image of our planet.'

嗯,看起来这个结果是合理的!
探索这一领域有许多方法(更多信息请查看附加部分),所以不要局限于我介绍的方式 - 动手尝试吧。
第 4 级:语义分块
你有没有觉得,我们使用一个固定的全局常量来定义数据块的大小,这种做法有些奇怪?更让人困惑的是,我们目前的数据块分割方式似乎并未考虑到数据内容的实际含义。
这个想法并非只有我一个人有

肯定有更好的解决方式 - 让我们一起探索一下。
Embeddings(嵌入)能够表达字符串的语义含义。虽然它们单独使用时效果有限,但将它们与其他文本的 Embeddings 进行对比,我们就能开始理解不同数据块之间的语义关系。我想深入探讨这一特性,尝试利用 Embeddings 找出语义上相似的文本群。
我的假设是:在语义上相似的数据块应该被归类在一起。
我尝试了几种方法:
- 分层聚类与位置奖励 - 我试验了使用句子嵌入进行的分层聚类。但因为选择了按句子分割,遇到了一个问题:在一个长句之后的短句可能会改变整个数据块的含义。因此,我引入了位置奖励机制,如果句子彼此相邻,那么它们更有可能形成一个集群。这种方法效果尚可,但调整参数的过程既漫长又不理想。
- 寻找连续句子间的分割点 - 我接着尝试了一种步行法。从第一句话开始,获取其嵌入,然后与第二句进行比较,以此类推。我在寻找嵌入距离较大的“分割点”。如果距离超过了一定阈值,我就认为这标志着新的语义段落的开始。最初我尝试对每个句子进行嵌入,但结果太过混乱。因此,我改为每三句话(一个窗口)进行嵌入,然后去掉第一句,加上下一句。这种方法效果稍好。
我在这里展示的是方法 #2 - 它虽然不是完美的解决方案,但确实是一个很好的探索起点。我非常希望听到你的意见,了解你认为如何可以进一步改进它。
首先,我们来加载一篇文章进行尝试。为了控制使用的 token 数量,我这里只选用了一篇文章。
我们将使用 Paul Graham 的 MIT 作文 作为示例。
In [56]:
with open('../data/PaulGrahamEssayMedium/mit.txt') as file:essay = file.read()
然后,我打算将整篇文章分割成单句。我会以句号、问号和感叹号作为分割标记。虽然还有更精确的分割方法,但目前这种方式简单且效率高。
In [57]:
import re# Splitting the essay on '.', '?', and '!'single_sentences_list = re.split(r'(?<=[.?!])\s+', essay)print (f"{len(single_sentences_list)} senteneces were found")
317 senteneces were found
但仅仅是句子列表有时会让添加新数据变得复杂。因此,我决定将其转化为字典列表(List[dict]),每个句子作为一个键值对。这样,我们就可以开始为每个句子添加更多数据。
In [58]:
sentences = [{'sentence': x, 'index' : i} for i, x in enumerate(single_sentences_list)]sentences[:3]
Out [58]:
[{'sentence': '\n\nWant to start a startup?', 'index': 0},{'sentence': 'Get funded by\nY Combinator.', 'index': 1},{'sentence': 'October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school.','index': 2}]
现在我们已经准备好句子列表,接下来,我想尝试将相邻的句子合并,以此减少干扰,更好地捕捉连续句子之间的关系。
我们来创建一个函数,便于之后重复使用。buffer_size 这个参数可以自定义,你可以根据需要选择窗口的大小。记住这个数值,它在后续步骤中很重要。目前我先设置 buffer_size 为 1。
In [60]:
def combine_sentences(sentences, buffer_size=1):# Go through each sentence dictfor i in range(len(sentences)):# Create a string that will hold the sentences which are joinedcombined_sentence = ''# Add sentences before the current one, based on the buffer size.for j in range(i - buffer_size, i):# Check if the index j is not negative (to avoid index out of range like on the first one)if j >= 0:# Add the sentence at index j to the combined_sentence stringcombined_sentence += sentences[j]['sentence'] + ' '# Add the current sentencecombined_sentence += sentences[i]['sentence']# Add sentences after the current one, based on the buffer sizefor j in range(i + 1, i + 1 + buffer_size):# Check if the index j is within the range of the sentences listif j < len(sentences):# Add the sentence at index j to the combined_sentence stringcombined_sentence += ' ' + sentences[j]['sentence']# Then add the whole thing to your dict# Store the combined sentence in the current sentence dictsentences[i]['combined_sentence'] = combined_sentencereturn sentencessentences = combine_sentences(sentences)
In [61]:
sentences[:3]
Out [61]:
[{'sentence': '\n\nWant to start a startup?','index': 0,'combined_sentence': '\n\nWant to start a startup? Get funded by\nY Combinator.'},{'sentence': 'Get funded by\nY Combinator.','index': 1,'combined_sentence': '\n\nWant to start a startup? Get funded by\nY Combinator. October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school.'},{'sentence': 'October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school.','index': 2,'combined_sentence': 'Get funded by\nY Combinator. October 2006(This essay is derived from a talk at MIT.)\nTill recently graduating seniors had two choices: get a job or go\nto grad school. I think there will increasingly be a third option:\nto start your own startup.'}]
注意到第二句话(索引为 #1)现在的 combined_sentence 字段包含了第一句和第三句。
现在,我打算获取合并句子的向量表示(embeddings),以此来计算三个句子组合之间的距离,并找出分割点。我会使用 OpenAI 提供的向量表示。
In [62]:
from langchain.embeddings import OpenAIEmbeddingsoaiembeds = OpenAIEmbeddings()
接下来,我们来批量获取这些句子的向量表示,这样会更快。
In [63]:
embeddings = oaiembeds.embed_documents([x['combined_sentence'] for x in sentences])
此时,我们已经获得了一系列向量表示,接下来需要把它们加入我们的字典列表中。
In [64]:
for i, sentence in enumerate(sentences):sentence['combined_sentence_embedding'] = embeddings[i]
好极了,接下来是最激动人心的部分,我们将检查连续两个向量表示之间的余弦距离,以确定分割点。我们将在字典中添加一个新的键值 'distance_to_next'。
In [66]:
from sklearn.metrics.pairwise import cosine_similaritydef calculate_cosine_distances(sentences):distances = []for i in range(len(sentences) - 1):embedding_current = sentences[i]['combined_sentence_embedding']embedding_next = sentences[i + 1]['combined_sentence_embedding']# Calculate cosine similaritysimilarity = cosine_similarity([embedding_current], [embedding_next])[0][0]# Convert to cosine distancedistance = 1 - similarity# Append cosine distance to the listdistances.append(distance)# Store distance in the dictionarysentences[i]['distance_to_next'] = distance# Optionally handle the last sentence# sentences[-1]['distance_to_next'] = None # or a default valuereturn distances, sentences
接下来,我们从各个句子中提取出距离值,然后将这些值也添加进去。
In [67]:
distances, sentences = calculate_cosine_distances(sentences)
让我们看看距离数组的样子。
In [68]:
distances[:3]
Out [68]:
[0.08087857007785526, 0.027035058720847993, 0.04685817747375054]
这些不过是一些看起来乏味的数字而已。我们不妨将它们绘制出来。
In [70]:
import matplotlib.pyplot as pltplt.plot(distances);
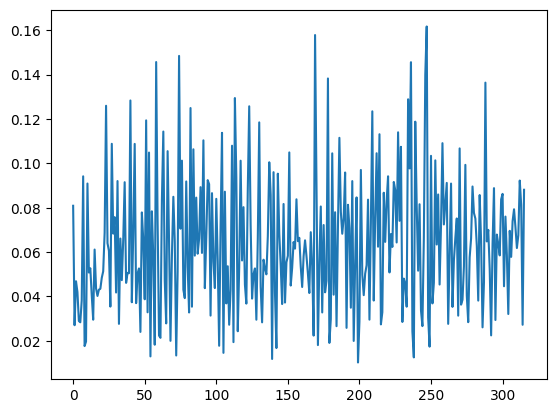
看,真有意思!可以看到距离较小的区段和距离较大的区域。最吸引人的是那些分布较为散乱的异常点。
划分文章有很多方法,但我选择将超过距离 95 百分位的点作为分割点。这是我们唯一需要设置的参数。
接下来,我会制作一个最终的可视化展示。想要了解更多关于迭代制作和总体概览,请观看相关视频。
我们来看看最终划分出的文本块。
In [83]:
import numpy as npplt.plot(distances);y_upper_bound = .2plt.ylim(0, y_upper_bound)plt.xlim(0, len(distances))# We need to get the distance threshold that we'll consider an outlier# We'll use numpy .percentile() for thisbreakpoint_percentile_threshold = 95breakpoint_distance_threshold = np.percentile(distances, breakpoint_percentile_threshold) # If you want more chunks, lower the percentile cutoffplt.axhline(y=breakpoint_distance_threshold, color='r', linestyle='-');# Then we'll see how many distances are actually above this onenum_distances_above_theshold = len([x for x in distances if x > breakpoint_distance_threshold]) # The amount of distances above your thresholdplt.text(x=(len(distances)*.01), y=y_upper_bound/50, s=f"{num_distances_above_theshold + 1} Chunks");# Then we'll get the index of the distances that are above the threshold. This will tell us where we should split our textindices_above_thresh = [i for i, x in enumerate(distances) if x > breakpoint_distance_threshold] # The indices of those breakpoints on your list# Start of the shading and textcolors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']for i, breakpoint_index in enumerate(indices_above_thresh):start_index = 0 if i == 0 else indices_above_thresh[i - 1]end_index = breakpoint_index if i < len(indices_above_thresh) - 1 else len(distances)plt.axvspan(start_index, end_index, facecolor=colors[i % len(colors)], alpha=0.25)plt.text(x=np.average([start_index, end_index]),y=breakpoint_distance_threshold + (y_upper_bound)/ 20,s=f"Chunk #{i}", horizontalalignment='center',rotation='vertical')# # Additional step to shade from the last breakpoint to the end of the datasetif indices_above_thresh:last_breakpoint = indices_above_thresh[-1]if last_breakpoint < len(distances):plt.axvspan(last_breakpoint, len(distances), facecolor=colors[len(indices_above_thresh) % len(colors)], alpha=0.25)plt.text(x=np.average([last_breakpoint, len(distances)]),y=breakpoint_distance_threshold + (y_upper_bound)/ 20,s=f"Chunk #{i+1}",rotation='vertical')plt.title("PG Essay Chunks Based On Embedding Breakpoints")plt.xlabel("Index of sentences in essay (Sentence Position)")plt.ylabel("Cosine distance between sequential sentences")plt.show()
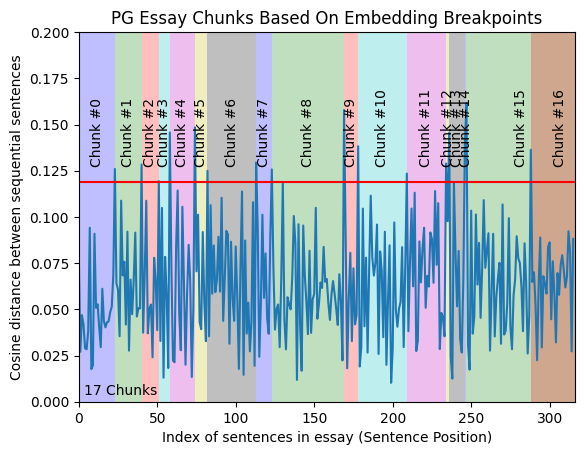
好了,通过可视化分散了我们的注意力之后,现在需要将这些句子组合成文本块。
考虑到我们的分割点是 [23, 40, 51...],我打算将第一个块设定为从 0 到 22,因为在第 23 句时距离有了显著的增加。
In [123]:
# Initialize the start indexstart_index = 0# Create a list to hold the grouped sentenceschunks = []# Iterate through the breakpoints to slice the sentencesfor index in indices_above_thresh:# The end index is the current breakpointend_index = index# Slice the sentence_dicts from the current start index to the end indexgroup = sentences[start_index:end_index + 1]combined_text = ' '.join([d['sentence'] for d in group])chunks.append(combined_text)# Update the start index for the next groupstart_index = index + 1# The last group, if any sentences remainif start_index < len(sentences):combined_text = ' '.join([d['sentence'] for d in sentences[start_index:]])chunks.append(combined_text)# grouped_sentences now contains the chunked sentences
接下来,我们手动检查一些文本块,确保它们看起来合理。
In [129]:
for i, chunk in enumerate(chunks[:2]):buffer = 200print (f"Chunk #{i}")print (chunk[:buffer].strip())print ("...")print (chunk[-buffer:].strip())print ("\n")
Chunk #0Want to start a startup? Get funded byY Combinator. October 2006(This essay is derived from a talk at MIT.)Till recently graduating seniors had two choices: get a job or goto grad school. I think...]About a month into each fundingcycle we have an event called Prototype Day where each startuppresents to the others what they've got so far. You might thinkthey wouldn't need any more motivation.Chunk #1They're working on theircool new idea; they have funding for the immediate future; andthey're playing a game with only two outcomes: wealth or failure. You'd think that would be motivation enough. A...e tell people not to? For the same reason that the probablyapocryphal violinist, whenever he was asked to judge someone'splaying, would always say they didn't have enough talent to makeit as a pro.
我想再强调一点,这只是对一种尚未成熟的方法的探索。要确保这种方法适合您的应用场景,应当通过 RAG 评估进行测试。
至于这种方法的块大小或块间重叠,我这里并没有过多考虑。但如果需要的话,您可以对较大的块进行递归拆分。
您有什么改进意见吗?请通过这个链接告诉我!您还可以通过这个链接提前了解相关内容。
第 5 级:策略性分块
进一步深入第 4 级 - 我们能否指导一个大语言模型 (LLM) 如同人类一样完成这项任务?
人类如何开始进行分块的呢?
嗯……让我思考一下,如果是我,该如何将文档划分为各个独立且在语义上相近的部分?
- 我会准备一张草稿纸或记事本
- 从文章顶端开始阅读,并默认第一部分为一个独立分块(因为目前还未分块)
- 接着逐句审视文章,判断每个新句子或段落是否归入首个分块,若不适合,则创建新的分块
- 持续这个过程,直至文章尾端。
哇!稍等 - 这其实是一个我们可以尝试的伪代码。详见我在这里的调侃。
我曾犹豫是否应该严格限制自己只使用文档的原始文本,还是可以采用其派生形式。考虑到前者过于严苛,我选择了探索使用命题的方法。这是一个新颖的概念(参见研究论文),能够从一段原始文本中提炼出独立的陈述。
例如:Greg 去了公园。他喜欢散步 > ['Greg 去了公园。', 'Greg 喜欢散步']
现在开始操作:
In [86]:
from langchain.output_parsers.openai_tools import JsonOutputToolsParserfrom langchain_community.chat_models import ChatOpenAIfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain.chains import create_extraction_chainfrom typing import Optional, Listfrom langchain.chains import create_extraction_chain_pydanticfrom langchain_core.pydantic_v1 import BaseModelfrom langchain import hub
我们将通过一个精心设计的提示,来从LangHub提取命题,LangChain 提供了一个专门的提示库。
你可以在这里查看具体的命题提示。
我选择使用 gpt-4 作为 LLM,因为在这里我们注重效果而不是速度或成本。
In [87]:
obj = hub.pull("wfh/proposal-indexing")llm = ChatOpenAI(model='gpt-4-1106-preview', openai_api_key = os.getenv("OPENAI_API_KEY", 'YouKey'))
随后,我将使用 langchain 创建一个可执行程序,它能够将提示与 LLM 结合起来运行。
In [88]:
# use it in a runnablerunnable = obj | llm
可执行程序的输出是一个类似于 json 的字符串结构。我们需要从中提取出句子。我发现 LangChain 的示例提取过程颇具挑战,因此我选择手动使用一个 pydantic 数据类进行操作。这个过程仍有改善空间。
首先创建你的类,然后将其加入到提取链中。
In [89]:
# Pydantic data classclass Sentences(BaseModel):sentences: List[str]# Extractionextraction_chain = create_extraction_chain_pydantic(pydantic_schema=Sentences, llm=llm)
接着,我们将这一过程封装成一个函数,该函数将返回一个命题列表。
In [90]:
def get_propositions(text):runnable_output = runnable.invoke({"input": text}).contentpropositions = extraction_chain.run(runnable_output)[0].sentencesreturn propositions
现在,去寻找你想要处理的文本。
In [91]:
with open('../data/PaulGrahamEssayMedium/superlinear.txt') as file:essay = file.read()
接下来,你需要决定发送给命题生成器的内容。提示中的示例大约有 1000 个字符长。因此,你可以根据自己的情况进行实验。这不是另一个分块决策,只需选择一个合理的长度并尝试。
我选择使用段落作为输入。
In [92]:
paragraphs = essay.split("\n\n")
我们来看看有多少个
In [93]:
len(paragraphs)
Out [93]:
53
演示中展示这么多显得过多,我只演示前几个作为示例。
In [96]:
essay_propositions = []for i, para in enumerate(paragraphs[:5]):propositions = get_propositions(para)essay_propositions.extend(propositions)print (f"Done with {i}")
Done with 0Done with 1Done with 2Done with 3Done with 4
我们来看一下这些命题是什么样子
In [97]:
print (f"You have {len(essay_propositions)} propositions")essay_propositions[:10]
You have 26 propositions
Out [97]:
['The month is October.','The year is 2023.','I was a child at some past time.','At that past time, I did not understand something important about the world.','The important thing I did not understand is the degree to which the returns for performance are superlinear.','Teachers and coaches implicitly told us the returns were linear.','Teachers and coaches meant well.',"The statement 'You get out what you put in' was heard a thousand times by the speaker.","The statement 'You get out what you put in' is rarely true.","If your product is only half as good as your competitor's product, you do not get half as many customers."]
你会发现,这些命题看起来像普通的句子,但实际上是能独立表达意思的陈述。例如,原文中有句话是:“They meant well, but this is rarely true.”如果这句话单独作为一个分块,大语言模型就无法理解其含义。‘他们’指的是谁?什么事情很少是真的?但这些信息都已经在命题中表达了。
现在进入精彩部分,我们需要一个系统来分析每个命题,并判断它应该是现有内容的一部分还是需要形成一个新的内容块。
这个过程的伪代码已经展示在上面了 - 我在视频中也对这段代码进行了解说,如果你想看我现场讲解,请确保观看视频。
如果你已经下载了这个代码库,那么脚本也可以在其中找到。
In [98]:
# mini script I madefrom agentic_chunker import AgenticChunker
In [99]:
ac = AgenticChunker()
接下来,我们把这些命题输入系统。完整的列表很长,我这里只处理其中的一小部分。
这个方法虽然慢且成本高,但我们来看看它的效果。
你可以在创建分块器时设置ac = AgenticChunker(print_logging=False)来关闭打印语句。
In [100]:
ac.add_propositions(essay_propositions)
Adding: 'The month is October.'No chunks, creating a new oneCreated new chunk (51322): Date & TimesAdding: 'The year is 2023.'Chunk Found (51322), adding to: Date & TimesAdding: 'I was a child at some past time.'No chunks foundCreated new chunk (a6f65): Personal HistoryAdding: 'At that past time, I did not understand something important about the world.'Chunk Found (a6f65), adding to: Personal HistoryAdding: 'The important thing I did not understand is the degree to which the returns for performance are superlinear.'No chunks foundCreated new chunk (4a183): Performance & Returns RelationshipAdding: 'Teachers and coaches implicitly told us the returns were linear.'Chunk Found (4a183), adding to: Performance & Returns RelationshipAdding: 'Teachers and coaches meant well.'No chunks foundCreated new chunk (0f9c7): Education & Mentoring PracticesAdding: 'The statement 'You get out what you put in' was heard a thousand times by the speaker.'Chunk Found (4a183), adding to: Misconceptions in Performance Returns RelationshipAdding: 'The statement 'You get out what you put in' is rarely true.'Chunk Found (4a183), adding to: Effort vs. Reward DynamicsAdding: 'If your product is only half as good as your competitor's product, you do not get half as many customers.'No chunks foundCreated new chunk (e6a13): Product Quality & Customer AcquisitionAdding: 'You get no customers if your product is only half as good as your competitor's product.'Chunk Found (e6a13), adding to: Product Quality & Customer AcquisitionAdding: 'You go out of business if you get no customers.'Chunk Found (e6a13), adding to: Product Quality & Customer RetentionAdding: 'The returns for performance are superlinear in business.'Chunk Found (4a183), adding to: Performance Returns & Effort RelationshipAdding: 'Some people think the superlinearity in business is a flaw of capitalism.'Chunk Found (4a183), adding to: Effort vs. Reward DynamicsAdding: 'Some people think if the rules were changed, superlinear returns for performance in business would stop being true.'Chunk Found (4a183), adding to: Superlinear Returns in Performance & BusinessAdding: 'Superlinear returns for performance are a feature of the world.'Chunk Found (4a183), adding to: Effort vs. Reward: Superlinearity in Performance & BusinessAdding: 'Superlinear returns for performance are not an artifact of rules that humans have invented.'Chunk Found (4a183), adding to: Superlinear Returns on Performance in Various ContextsAdding: 'The same pattern of superlinearity is seen in fame.'Chunk Found (4a183), adding to: Superlinear Returns & Their ImplicationsAdding: 'The same pattern of superlinearity is seen in power.'Chunk Found (4a183), adding to: Superlinear Returns in Performance & SocietyAdding: 'The same pattern of superlinearity is seen in military victories.'Chunk Found (4a183), adding to: Superlinearity in Performance Across DomainsAdding: 'The same pattern of superlinearity is seen in knowledge.'Chunk Found (4a183), adding to: Superlinear Returns in Performance and SocietyAdding: 'The same pattern of superlinearity is seen in benefit to humanity.'Chunk Found (4a183), adding to: Superlinearity in Effort, Reward, and Various DomainsAdding: 'In all of these areas, the rich get richer.'Chunk Found (4a183), adding to: Effort vs. Reward Dynamics Across DomainsAdding: 'You cannot understand the world without understanding the concept of superlinear returns.'Chunk Found (4a183), adding to: Superlinear Returns in Performance & SocietyAdding: 'If you are ambitious, you definitely should understand the concept of superlinear returns.'Chunk Found (4a183), adding to: Superlinear Returns Across Various DomainsAdding: 'Understanding the concept of superlinear returns will be the wave you surf on if you are ambitious.'Chunk Found (4a183), adding to: Understanding Superlinear Returns & Their Impact
很好,看起来生成了几个内容块。让我们来看看它们
In [101]:
ac.pretty_print_chunks()
You have 5 chunksChunk #0Chunk ID: 51322Summary: This chunk contains information about specific dates and times, including months and years.Propositions:-The month is October.-The year is 2023.Chunk #1Chunk ID: a6f65Summary: This chunk contains reflections on someone's childhood and their understanding of the world during that time.Propositions:-I was a child at some past time.-At that past time, I did not understand something important about the world.Chunk #2Chunk ID: 4a183Summary: This chunk explores the concept of superlinear returns across different fields, challenging the notion of linear rewards and emphasizing its significance for understanding success dynamics and ambition.Propositions:-The important thing I did not understand is the degree to which the returns for performance are superlinear.-Teachers and coaches implicitly told us the returns were linear.-The statement 'You get out what you put in' was heard a thousand times by the speaker.-The statement 'You get out what you put in' is rarely true.-The returns for performance are superlinear in business.-Some people think the superlinearity in business is a flaw of capitalism.-Some people think if the rules were changed, superlinear returns for performance in business would stop being true.-Superlinear returns for performance are a feature of the world.-Superlinear returns for performance are not an artifact of rules that humans have invented.-The same pattern of superlinearity is seen in fame.-The same pattern of superlinearity is seen in power.-The same pattern of superlinearity is seen in military victories.-The same pattern of superlinearity is seen in knowledge.-The same pattern of superlinearity is seen in benefit to humanity.-In all of these areas, the rich get richer.-You cannot understand the world without understanding the concept of superlinear returns.-If you are ambitious, you definitely should understand the concept of superlinear returns.-Understanding the concept of superlinear returns will be the wave you surf on if you are ambitious.Chunk #3Chunk ID: 0f9c7Summary: This chunk contains information about the intentions and behaviors of educators and mentors.Propositions:-Teachers and coaches meant well.Chunk #4Chunk ID: e6a13Summary: This chunk discusses the consequences of inferior product quality on business viability and customer base.Propositions:-If your product is only half as good as your competitor's product, you do not get half as many customers.-You get no customers if your product is only half as good as your competitor's product.-You go out of business if you get no customers.
太棒了,如果我们想要准确获取这些内容块,我们可以提取一个包含它们的字符串列表。这些命题会被连接在同一个字符串中
In [102]:
chunks = ac.get_chunks(get_type='list_of_strings')
In [103]:
chunks
Out [103]:
['The month is October. The year is 2023.','I was a child at some past time. At that past time, I did not understand something important about the world.',"The important thing I did not understand is the degree to which the returns for performance are superlinear. Teachers and coaches implicitly told us the returns were linear. The statement 'You get out what you put in' was heard a thousand times by the speaker. The statement 'You get out what you put in' is rarely true. The returns for performance are superlinear in business. Some people think the superlinearity in business is a flaw of capitalism. Some people think if the rules were changed, superlinear returns for performance in business would stop being true. Superlinear returns for performance are a feature of the world. Superlinear returns for performance are not an artifact of rules that humans have invented. The same pattern of superlinearity is seen in fame. The same pattern of superlinearity is seen in power. The same pattern of superlinearity is seen in military victories. The same pattern of superlinearity is seen in knowledge. The same pattern of superlinearity is seen in benefit to humanity. In all of these areas, the rich get richer. You cannot understand the world without understanding the concept of superlinear returns. If you are ambitious, you definitely should understand the concept of superlinear returns. Understanding the concept of superlinear returns will be the wave you surf on if you are ambitious.",'Teachers and coaches meant well.',"If your product is only half as good as your competitor's product, you do not get half as many customers. You get no customers if your product is only half as good as your competitor's product. You go out of business if you get no customers."]
好极了,现在我们可以将这些内容用于您的检索评估。
额外层级:替代性的数据表现形式
到目前为止,我已经展示了如何将你的原始文本分块处理(第 5 级我处理得稍微有点发散)。
但如果你的原始文本不是为你的任务最佳的数据表现形式,该怎么办呢?
比如,当你在聊天信息上进行语义搜索时,原始的聊天信息可能缺少足够的上下文来实现有效的嵌入。或许尝试对一段对话的总结进行语义搜索会更有效。或者搜索那些聊天可能回答的假设性问题呢?
这就是分块和拆分技术开始深入索引领域的时刻。进行索引意味着你正在为你的数据在数据库或知识库中的表示方式做出选择。
这实际上是一个与检索相关的话题,但它和分块技术息息相关,值得一提。
我们快速看一下开发者们喜欢用来表示数据的几种流行的替代方法。尝试的方法有无穷无尽,我们这里只讨论四种:
- 多向量索引 - 当你对非原始文本派生的向量进行语义搜索时使用的方法
- 摘要 - 对你的文本块进行总结
- 假设性问题 - 特别适用于作为知识库的聊天消息
- 子文档 - 父文档的检索工具
- 基于图的分块 - 将原始文本转化为图形结构
摘要
与其嵌入原始文本,不如嵌入对原始文本的摘要,这样信息更为集中、丰富。
In [104]:
import uuidfrom langchain.chat_models import ChatOpenAIfrom langchain.prompts import ChatPromptTemplatefrom langchain_core.documents import Documentfrom langchain_core.output_parsers import StrOutputParserfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain.retrievers.multi_vector import MultiVectorRetrieverfrom langchain.storage import InMemoryByteStorefrom langchain.embeddings import OpenAIEmbeddingsfrom langchain.vectorstores import Chroma
以我们的“超线性论文”为例。我将其分为几个大块:
In [105]:
with open('../data/PaulGrahamEssayMedium/superlinear.txt') as file:essay = file.read()splitter = RecursiveCharacterTextSplitter(chunk_size=4000, chunk_overlap=0)docs = splitter.create_documents([essay])print (f"You have {len(docs)} docs")
You have 6 docs
启动一个自动总结的程序:
In [106]:
chain = ({"doc": lambda x: x.page_content}| ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}")| ChatOpenAI(max_retries=0)| StrOutputParser())
然后获取这些摘要:
In [107]:
summaries = chain.batch(docs, {"max_concurrency": 5})
看一个例子:
In [108]:
summaries[0]
Out [108]:
"The document discusses the concept of superlinear returns, which refers to the idea that the rewards for performance are not linear but rather grow exponentially. The author explains that this understanding is crucial in navigating the world and achieving success. They provide examples of superlinear returns in various areas such as business, fame, power, and military victories. The document also highlights two fundamental causes of superlinear returns: exponential growth and thresholds. The author emphasizes the importance of focusing on growth rate rather than absolute numbers in order to achieve exponential growth. They mention Y Combinator's encouragement of this approach for startups. The document concludes by discussing the lack of natural understanding and customs surrounding exponential growth and the limited historical instances of it."
接下来,我们会创建一个向量库(存储向量和摘要)和一个文档库(存储原始文档):
In [109]:
# The vectorstore to use to index the child chunksvectorstore = Chroma(collection_name="summaries", embedding_function=OpenAIEmbeddings())# The storage layer for the parent documentsstore = InMemoryByteStore()id_key = "doc_id"# The retriever (empty to start)retriever = MultiVectorRetriever(vectorstore=vectorstore,byte_store=store,id_key=id_key,)doc_ids = [str(uuid.uuid4()) for _ in docs]
你需要从摘要列表中生成文档,并在其元数据中加入文档 ID。这样可以将摘要与原始文档关联起来,让你知道哪个摘要对应哪个原文。
In [110]:
summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]})for i, s in enumerate(summaries)]
然后将这些文档添加到你的向量库和文档库中。添加到向量库时,也会为这些文档生成相应的嵌入。
In [111]:
# Adds the summariesretriever.vectorstore.add_documents(summary_docs)# Adds the raw documentsretriever.docstore.mset(list(zip(doc_ids, docs)))
如果你愿意,你也可以将原始文档添加到向量库中。记得添加文档 ID,以便将所有内容关联起来。
In [ ]:
# for i, doc in enumerate(docs):# doc.metadata[id_key] = doc_ids[i]# retriever.vectorstore.add_documents(docs)
好了,完成了所有这些工作之后,让我们来尝试一下搜索。如果你运行下面的代码,你会在摘要嵌入上进行搜索,但返回的将是原始文档。
In [113]:
# retriever.get_relevant_documents(query="the concept of superlinear returns, which refers to the idea that the returns for performance are not linear")
假设性问题
您可以基于原始文档提出一系列假设性问题。想了解更多,可以参考 LangChain 的实现方案。
这在处理如聊天记录这类稀疏非结构化数据时特别有用。
比如,您想开发一个机器人,它利用 Slack 对话作为信息源。直接对这些原始聊天记录进行语义搜索可能效果不佳。但如果您能根据这些对话内容生成一些假设性问题,当有新问题出现时,这些问题就能帮助您更准确地找到答案。
实现这一功能的代码与生成摘要的代码类似,不同之处在于,您需要让大语言模型 (LLM) 生成的是假设性问题,而不是摘要。
父文档检索器 (PDR)
父文档检索器的理念与前两者相似,即在数据的多种表现形式上进行语义搜索。
PDR 的核心思想是,小片段的数据更容易在语义上与潜在的查询内容匹配。但这些小片段可能缺乏足够的上下文。因此,我们不直接将这些小片段交给大语言模型,而是选择包含这些小片段的更大的父片段进行处理。这样一来,您就能得到一个包含更丰富上下文的大片段。
您可以 In LangChain 的官网 查看相关实现。
如果您想深入了解,请访问 FullStackRetrieval.com 查阅完整教程。
我还想简单介绍一下 Llama Index 中的 HierarchicalNodeParser 和 AutoMergingRetriever。HierarchicalNodeParser 会将文档拆分成不同大小的块(这会造成一些重叠,但这正是其目的)。结合 AutoMergingRetriever 的使用,您可以轻松实现复杂的信息检索。具体操作指南请见 这里。
接下来,让我们来看看如何进行文档拆分。由于我们选择了 128 作为一个块的大小,因此会产生许多小块。
接着,我们来探索一个小块末端的关系网络。
您可以看到,每个小块都有它的来源、前一个、下一个和父节点。更多关于这些关系的详细信息,可以 In Llama Index 的文档 中找到。
图结构
如果您的数据中充满了各种实体、关系和联系方式,图结构或许非常适合您。
以下是一些选项:
- Diffbot
- InstaGraph - 由 Yohei 开发
由于篇幅原因,我这里将重点介绍 LangChain 支持的 Diffbot 版本。您需要从 Diffbot 获取一个 API 密钥
In [119]:
# !pip3 install langchain langchain-experimental openai neo4j wikipediafrom langchain_experimental.graph_transformers.diffbot import DiffbotGraphTransformerdiffbot_nlp = DiffbotGraphTransformer(diffbot_api_key=os.getenv("DIFFBOT_API_KEY", 'YourKey'))
In [120]:
text = """Greg is friends with Bobby. San Francisco is a great city, but New York is amazing.Greg lives in New York."""docs = [Document(page_content=text)]
In [121]:
graph_documents = diffbot_nlp.convert_to_graph_documents(docs)
In [122]:
graph_documents
Out [122]:
[GraphDocument(nodes=[Node(id='Greg', type='Person', properties={'name': 'Greg'}),Node(id='Bobby', type='Person', properties={'name': 'Bobby'}),Node(id='http://www.wikidata.org/entity/Q1384', type='Location', properties={'name': 'New York'})],relationships=[Relationship(source=Node(id='Greg', type='Person'),target=Node(id='Bobby', type='Person'),type='SOCIAL_RELATIONSHIP',properties={'evidence': 'Greg is friends with Bobby.'}),Relationship(source=Node(id='Greg', type='Person'),target=Node(id='http://www.wikidata.org/entity/Q1384', type='Location'), type='PERSON_LOCATION', properties={'evidence': 'Greg lives in New York.', 'isCurrent': 'true'}), Relationship(source=Node(id='Greg', type='Person'), target=Node(id='http://www.wikidata.org/entity/Q1384', type='Location'), type='PERSON_LOCATION', properties={'evidence': 'Greg lives in New York.', 'isCurrent': 'true'})], source=Document(page_content='\nGreg is friends with Bobby. San Francisco is a great city, but New York is amazing.\nGreg lives in New York. \n'))]
总结
恭喜您完成了本视频的学习。视频的目标是向您介绍数据块理论,简要提到信息检索,并激励您在自己的数据上应用这些方法。
我非常欢迎您分享对这段代码、视频的看法,或者讨论您在工作中是如何应用这些知识的。您可以通过 twitter 或电邮 (contact@dataindependent.com) 与我交流。