探索检索和评估相关上下文的挑战 [译]
Leonie Monigatti
利用 Ragas, TruLens 和 DeepEval 对一年级阅读理解练习进行上下文相关性评估的案例研究
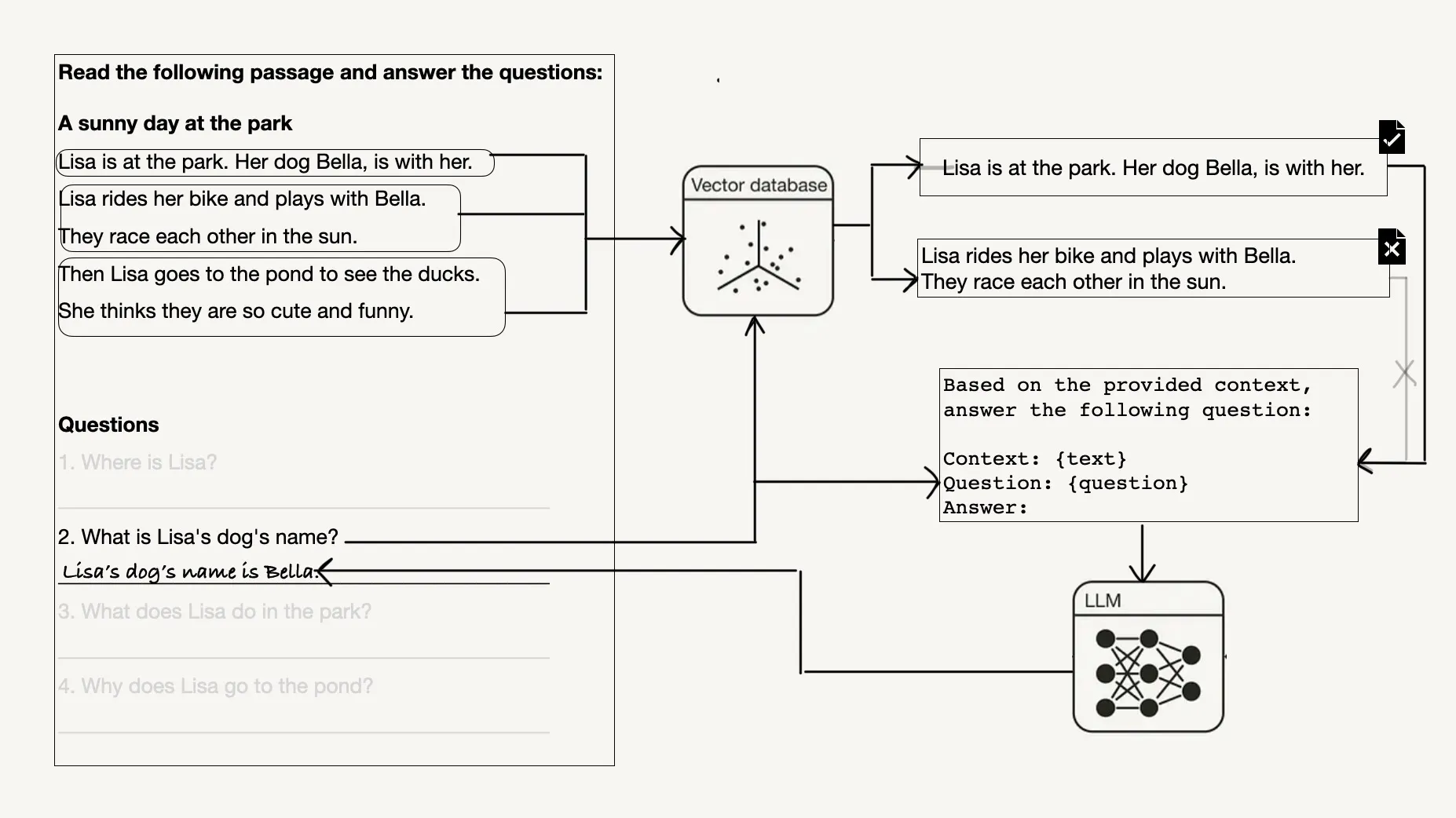
一个用于探讨上下文相关性的一年级阅读理解练习示例
在你的检索增强生成(RAG)系统中,如何有效地挑选与用户输入相关的上下文至关重要。但是,寻找恰当的上下文不仅充满挑战,如何精准评估上下文的相关性也是一大难题。
本文将通过一年级的文本理解练习为例,深入分析寻找和评估相关上下文的挑战。
text = """Lisa is at the park. Her dog Bella, is with her.Lisa rides her bike and plays with Bella. They race each other in the sun.Then Lisa goes to the pond to see the ducks.She thinks they are so cute and funny."""questions = ["Where is Lisa?","What is Lisa's dog's name?","What does Lisa do in the park?","Why does Lisa go to the pond?"]
值得一提的是,最先进的大语言模型如 gpt-3.5-turbo 能够轻松处理这种仅六句话的一年级练习,前提是你提供了完整的文本作为上下文。
from openai import OpenAIopenai = OpenAI()for question in questions:prompt_template = f"""Based on the provided context, answer the following question:Context: {text}Question: {question}Answer:"""response = openai.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content": prompt_template},],temperature=0,)print(f"Question: {question}\nAnswer: {response.choices[0].message.content}\n")
Question: Where is Lisa?Answer: Lisa is at the park.Question: What is Lisa's dog's name?Answer: Lisa's dog's name is Bella.Question: What does Lisa do in the park?Answer: In the park, Lisa rides her bike, plays with her dog Bella, races with Bella in the sun, and goes to the pond to see the ducks.Question: Why does Lisa go to the pond?Answer: Lisa goes to the pond to see the ducks because she thinks they are cute and funny.
但在实际的 RAG 系统中,你可能需要处理更庞大的文件,这些文件不可能完整地作为上下文传递给大语言模型。这个简单的练习旨在展示在 RAG 系统中检索部分面临的核心思想和挑战。
文档分块技术
在处理文档时,首要考虑的是如何将其分割成更小的信息片段。虽然不断出现的新型大语言模型 (LLM) 宣称能够处理更广泛的上下文,使得 RAG 看似将成为过去式,但诸如“Lost in the Middle: How Language Models Use Long Context”的研究却显示,如果直接将整篇文档输入到大语言模型中,反而可能削弱其解答问题的能力。
例如,在回答“Lisa 在哪里?”这个问题时,你实际上只需要知道“Lisa 在公园。”这样的简短信息,文档中的其他内容对解答这个问题并无帮助。
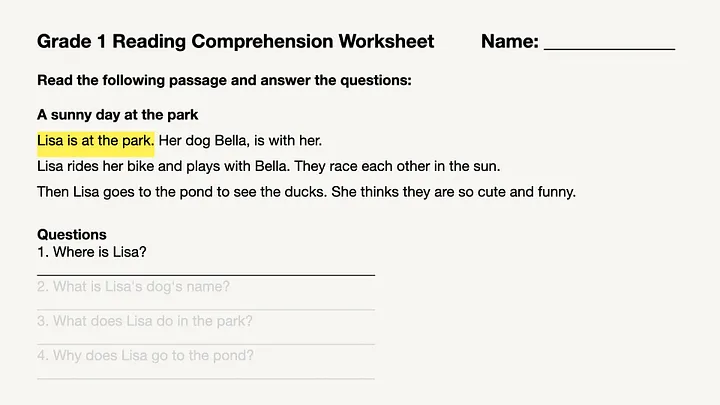
对于 RAG,一种基本的分块技术是按句子来切分文档。
然而,简单地将整个文档拆分成单独的句子并不总是最佳选择,因为有时候这样得到的上下文信息太少。以“Lisa 的狗叫什么名字?”为例,虽然“她的狗 Bella, 和她一起。”这一句包含了所需的名字信息,但这一句独立存在时无法明确“她”是指谁。在这种情况下,更理想的做法是选择两个句子的更大块大小,例如:“Lisa 在公园。她的狗 Bella, 和她一起。”
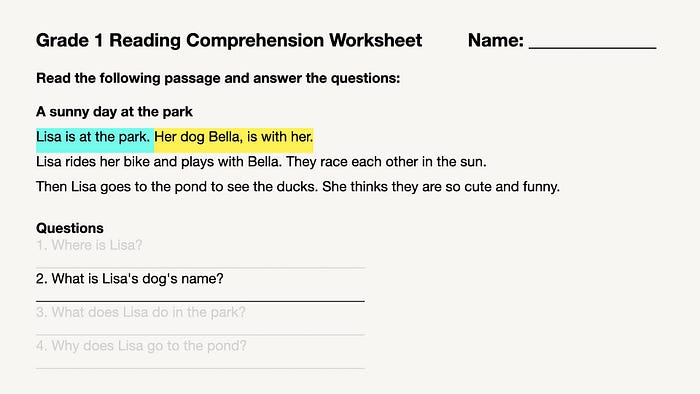
如你所见,调整块大小是提升你的 RAG 系统表现的一个关键参数。更多相关的调整策略,可以参见我的生产就绪的 RAG 应用调优指南。
此外,已经出现了更先进的数据块划分和检索策略。例如,在“句子窗口检索”(sentence window retrieval) 技术中,一个文档被分解为独立的句子,但是这些句子会与更大的上下文窗口一同存储,并在检索后用这个窗口替换单个句子,从而提供更丰富的上下文信息。
正如你所看到的,有许多不同的技术可以用来分割你的文档。例如 LangChain 和 LlamaIndex 等流行的框架提供了各种即用型的数据块划分策略。然而,什么才是最佳的数据块划分策略?这本身就是一个值得深入探讨的课题,因为可采取的方法多种多样。
幸运的是,你不需要完善分块步骤,正如我们所见,像 gpt-3.5-turbo 这样的最新大语言模型能够处理包含不相关信息的更广泛上下文。例如,在本例中,仅将文本分为每两句一块可能就已足够。
幸运的是,你无需完善分块步骤,因为我们看到,像
gpt-3.5-turbo这样的最新大语言模型能够处理含有不相关信息的更广泛的上下文。
检索
构建 RAG 管道时,一个关键问题是:应检索多少块内容?
例如,问题“Lisa 的狗叫什么名字?”仅需一个相关上下文,
Context 1: "Lisa is at the park. Her dog Bella, is with her."
而问题“Lisa 在公园里都做些什么?”则需两个相关上下文,这里假设我们已将文本按两句话一组进行分块处理:
Context 1: "Lisa rides her bike and plays with Bella. They race each other in the sun."Context 2: "Then Lisa goes to the pond to see the ducks. She thinks they are so cute and funny."

检索上下文的数量
可以看出,确定需要检索的上下文数量并非易事。这取决于所提问题、现有信息及块的大小。理想状态下,进行几轮实验,以便找到块大小与检索数量之间的最佳平衡会是一种好方法。
理想状态下,进行几轮实验,以便找到块大小与检索数量之间的最佳平衡会是一种好方法。
评估
在进行实验以确定 RAG 管道的最优配置时,您需要评估系统性能,以此判断当前实验是否优于基准。本节将探讨与 RAG 应用中上下文检索相关的各种评估指标。特别是,本节将讨论如何评估检索到的上下文与用户输入的相关性。
相似度和距离测量
虽然我们可以将上下文信息存储并从多种数据库中提取,但通常我们通过相似性搜索来进行提取。
为此,我们将文档内容通过所谓的嵌入模型转换为向量形式。查询时,对搜索词进行相同处理。由于向量能够数值化地表达语义信息,我们可以通过寻找与搜索词在向量空间中最接近的数据,来找到相似的信息。这种接近性是通过常用的距离计算方法计算的,如余弦相似性、点积以及 L1 或 L2 距离。
下面展示了一个二维示意图(通过 PCA 技术),描绘了问题和文档段落通过 OpenAI 的 text-embedding-3-small 模型转化为向量后的样貌。在这个向量空间里,与问题“莉莎为什么去池塘?”最接近的上下文段落是:“然后莉莎去池塘看鸭子,她觉得它们既可爱又有趣。”,这是对用户查询最相关的上下文。
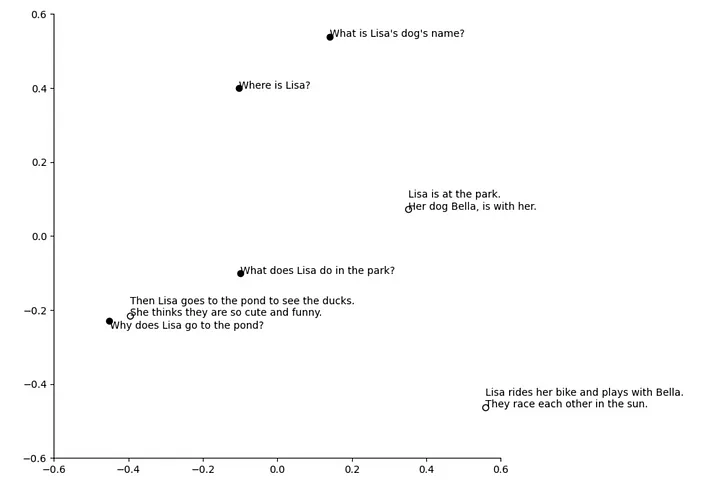
然而,“相似”并不总意味着“相关”。比如,对于问题“莉莎在公园里做了什么?”计算出的文档段落余弦距离如下所示:
What does Lisa do in the park?1. Lisa is at the park. Her dog Bella, is with her. (Distance: 0.40)2. Then Lisa goes to the pond to see the ducks. She thinks they are so cute and funny. (Distance: 0.45)3. Lisa rides her bike and plays with Bella. They race each other in the sun. (Distance: 0.51)
可以看出,最接近或最相似的上下文并未对问题提供答案,因此它与问题不相关。
然而,“相似”并不总意味着“相关”。
因此,单纯使用距离度量来判断上下文的相关性是不充分的。
搜索和排名指标
一个简单有效的方法来评估您的 RAG 系统的性能是采用经典的搜索和排名指标,包括:
- 准确率@K (Precision@K): 从检索的上下文中,有多少是相关的?
- 召回率@K (Recall@K): 从所有相关的上下文中,检索到了多少?(有助于您调整要检索的上下文数量。)
- 平均倒数排名 (MRR): 系统将排名中的第一个相关结果排在多高的位置。(如果您确定只有一个相关上下文,这是非常有用的。)
- 标准化折扣累积增益 (NDCG): 考虑所有检索结果的相关性以及它们的排序位置。(这是搜索和推荐系统中最常用的指标。)
虽然这些都是经过验证并推荐的指标,但一个缺点是它们需要真实的基准标签来确定上下文的相关性。对于 NDCG 指标,您甚至需要详细说明上下文的相关性(它到底有多相关?您是如何在“相关”、“稍有相关”、"非常相关" 或是 0 到 10 的标度上评估相关性的?)。随着数据集规模的增大,收集这些基准标签的成本可能会变得非常高。
RAG 评估框架中的上下文相关性度量
RAG 评估框架中有一个有趣的新发展:许多不同的 RAG 评估框架,例如 Ragas、TruLens 和 DeepEval,都引入了一种称为上下文相关性的“无参考指标”。
上下文相关性 度量评估提供的上下文与用户查询的相关性。在许多 RAG 评估框架中,这是一个“无参考”指标,因为它不需要任何真实标签,而是使用大语言模型(LLM)来计算。
上下文相关性 度量旨在评估提供的上下文与用户查询的相关性。
由于该度量指标相对较新,目前在不同框架中的计算方式有所不同。本节旨在提供关于 Ragas、TruLens 和 DeepEval 中上下文相关性度量的初步直观认识。
免责声明:本节并非旨在对上述框架进行广泛比较,也不是为了推荐使用哪种框架。它仅旨在提供框架概述以及上下文相关性度量的直观认识。
接下来,我们将使用两组小的示例数据。第一个 DataFrame 包含了示例工作表中的问题及我们定义为相关的上下文。

第二个 DataFrame 包含了问题“为什么 Lisa 去池塘?”的不同上下文。前三个上下文都包含了相关信息,但有不同程度的“杂乱”信息。最后一个上下文与问题完全无关。

import pandas as pd# Replace with your examples heredf = pd.DataFrame({'question': [ ...],'contexts': [[...], ...],'answers': [...]})
首先,请确保您的 OpenAI API 密钥已经设置在环境变量中,因为下面提到的所有框架均需利用 OpenAI 的大语言模型 (LLM) 来评定上下文的相关性。
import osos.environ["OPENAI_API_KEY"] = "sk..."
Ragas 采用以下公式来衡量上下文相关性:
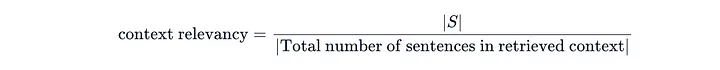
使用以下代码段,您可以在 Ragas 中计算出上下文相关性指标,这需要输入 question 和 contexts 这两项信息。
# !pip install ragasfrom datasets import Datasetfrom ragas.metrics import ContextRelevancy# Bring dataframe into right formatdataset = Dataset.from_pandas(df)# Set up context relevancy metriccontext_relevancy = ContextRelevancy()# Calculate metricresults = context_relevancy.score(dataset)
下面展示的是我们认为相关的上下文的相关性评分结果。

这些上下文相关性分数介于 0.5 至 1 之间,尽管我们已将所有上下文片段都视为相关。但由于 Ragas 是按照其认定的相关句子数与上下文中总句子数的比例来计算的,如果底层的 LLM 未将某些句子视为相关,分数就可能迅速下降。
接下来,您可以看到对于我们标记为不相关的上下文的相关性评分结果。

对于那些信息混乱的上下文,您会注意到相关性评分有所下降。另外,一个完全不相关的上下文的相关性评分为零。
DeepEval 则使用以下公式来评估上下文相关性:
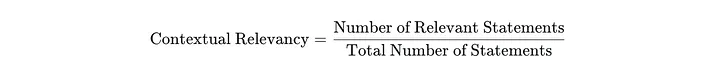
来自 DeepEval 文档的截图
您可以按照下面的代码在 DeepEval 中计算上下文相关性指标。该框架需要输入 question(问题)、contexts(上下文)和 answers(答案)来进行计算。
# ! pip install deepevalfrom deepeval import evaluatefrom deepeval.metrics import ContextualRelevancyMetricfrom deepeval.test_case import LLMTestCasecontext_relevancy = []for _, row in df.iterrows():# Define metricmetric = ContextualRelevancyMetric(threshold=0.5,model="gpt-3.5-turbo", #alternatively use "gpt-4")# Define test casetest_case = LLMTestCase(input = row.question,actual_output = row.answers,retrieval_context = row.contexts.tolist(),)# Calculate metricmetric.measure(test_case)context_relevancy.append(metric.score)
在下面,您可以查看我们认为相关的上下文所得到的上下文相关性指标。

大部分的结果显示上下文相关性为 1,仅有一个示例显示为 0.5。在下面,您可以查看我们认为不相关的上下文所得到的上下文相关性指标。

有趣的是,在加入了无关紧要的信息的示例中,我们并未观察到上下文相关性得分有任何变化。然而,一个完全无关的上下文示例的上下文相关性得分为 0。
据我了解,截至目前,TruLens 的文档还没有提供如何计算上下文相关性的详细说明。
您可以按照下面的代码在 TruLens 中计算上下文相关性指标。该框架同样需要输入 question(问题)、contexts(上下文)和 answers(答案)来进行计算。
# !pip install trulens_evalfrom trulens_eval import Select, Trufrom trulens_eval.tru_virtual import VirtualApp, TruVirtual, VirtualRecordfrom trulens_eval.feedback.provider import OpenAIfrom trulens_eval.feedback.feedback import Feedback# Define virtual appvirtual_app = VirtualApp()retriever = Select.RecordCalls.retrievervirtual_app[retriever] = "retriever"# Initialize provider classprovider = OpenAI()# Define context_callcontext_call = retriever.get_context # The selector for a presumed context retrieval component's call to `get_context`.context = context_call.rets[:] # Select context to be used in feedback. We select the return values of the virtual `get_context` call in the virtual `retriever` component.# Define feedback function for context relevancef_context_relevance = (Feedback(provider.context_relevance_with_cot_reasons).on_input().on(context))# Define virtual recordervirtual_recorder = TruVirtual(app_id="SmallTests",app=virtual_app,feedbacks=[f_context_relevance],)# Define test casesfor _, row in df.iterrows():record = VirtualRecord(main_input = row.question,main_output= row.answers,calls={context_call: dict(rets=row.contexts.tolist()),})virtual_recorder.add_record(record)# Calculate metrictru = Tru()tru.run_dashboard(force=True)tru.start_evaluator()
请注意,TruLens 的结果通过一个仪表板展示。下面的结果是为了保持与文章中其他框架的视觉一致性,从仪表板复制回数据框中的。 在下面,您可以查看我们认为相关的上下文所得到的上下文相关性指标。``

如图所示,所有与问题相关的上下文在 TruLens 的评分均在 0.85 到 1 之间。
在下图中,您可以看到针对不相关上下文的相关性评分结果。

值得注意的是,即使存在额外的无关信息,TruLens 也不会降低其评分:所有包含必要信息的上下文评分都在 0.9 或以上。另外一个有趣的现象是,相较于 Ragas 和 DeepEval,TruLens 对于不包含解决问题所需信息的上下文也给出了相对较高的 0.4 分。
摘要
本文讨论了为 RAG 应用检索上下文及评估其与问题相关性时遇到的挑战。文章通过分析一个包含六个句子和四个问题的简单一年级文本理解练习,展示了这些挑战。
在索引阶段,需要选择合适的上下文切分策略和尺寸。在检索阶段,还需权衡块的大小与检索的上下文数量。在评估阶段,则需选定一个恰当的度量标准来评估所检索上下文的质量。
此外,文章还探讨了几个现代 RAG 评估框架中使用的无需参考文献的“上下文相关性”指标。这些框架包括 Ragas,TruLens 和 DeepEval,它们如何评估人工识别为相关或不相关的上下文。